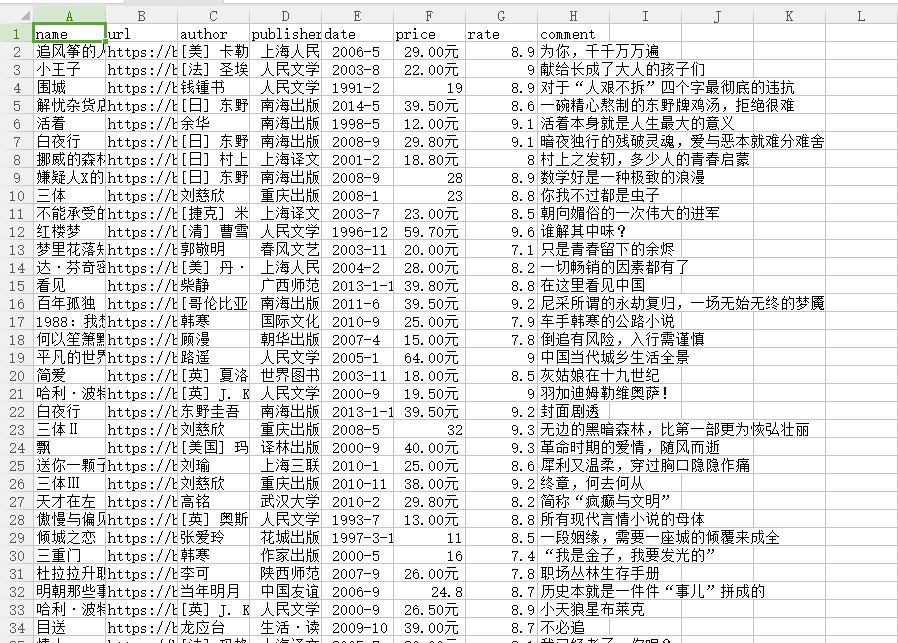
爬去豆瓣图书top250数据存储到csv中
from lxml import etree
import requests
import csv
fp=open('C://Users/Administrator/Desktop/lianxi/doubanbook.csv','w+',newline='',encoding='utf-8')
writer=csv.writer(fp)
writer.writerow(('name','url','author','publisher','date','price','rate','comment'))
headers={
#'User-Agent':'Nokia6600/1.0 (3.42.1) SymbianOS/7.0s Series60/2.0 Profile/MIDP-2.0 Configuration/CLDC-1.0'
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
urls=['https://book.douban.com/top250?start={}'.format(str(i))for i in range(0,50,25)]
for url in urls:
html=requests.get(url,headers=headers)
selector=etree.HTML(html.text)
infos=selector.xpath('//tr[@class="item"]')
for info in infos:
name=info.xpath('td/div/a/@title')[0]
url=info.xpath('td/div/a/@href')[0]
book_infos=info.xpath('td/p/text()')[0]
author=book_infos.split('/')[0]
publisher=book_infos.split('/')[-3]
date=book_infos.split('/')[-2]
price=book_infos.split('/')[-1]
rate=info.xpath('td/div/span[2]/text()')[0]
comments=info.xpath('td/p/span/text()')
comment=comments[0] if len(comments) != 0 else "空"
writer.writerow((name,url,author,publisher,date,price,rate,comment))
fp.close()
爬去豆瓣图书top250数据存储到csv中的更多相关文章
- Python 2.7_利用xpath语法爬取豆瓣图书top250信息_20170129
大年初二,忙完家里一些事,顺带有人交流爬取豆瓣图书top250 1.构造urls列表 urls=['https://book.douban.com/top250?start={}'.format(st ...
- Python爬虫-爬取豆瓣图书Top250
豆瓣网站很人性化,对于新手爬虫比较友好,没有如果调低爬取频率,不用担心会被封 IP.但也不要太频繁爬取. 涉及知识点:requests.html.xpath.csv 一.准备工作 需要安装reques ...
- 实例学习——爬取豆瓣音乐TOP250数据
开发环境:(Windows)eclipse+pydev+MongoDB 豆瓣TOP网址:传送门 一.连接数据库 打开MongoDBx下载路径,新建名为data的文件夹,在此新建名为db的文件夹,d ...
- 实例学习——爬取豆瓣网TOP250数据
开发环境:(Windows)eclipse+pydev 网址:https://book.douban.com/top250?start=0 from lxml import etree #解析提取数据 ...
- 爬取豆瓣电影top250并存储到mysql数据库
import requests from lxml import etree import re import pymysql import time conn= pymysql.connect(ho ...
- python爬虫1——获取网站源代码(豆瓣图书top250信息)
# -*- coding: utf-8 -*- import requests import re import sys reload(sys) sys.setdefaultencoding('utf ...
- python系列之(3)爬取豆瓣图书数据
上次介绍了beautifulsoup的使用,那就来进行运用下吧.本篇将主要介绍通过爬取豆瓣图书的信息,存储到sqlite数据库进行分析. 1.sqlite SQLite是一个进程内的库,实现了自给自足 ...
- 【Python数据分析】Python3操作Excel-以豆瓣图书Top250为例
本文利用Python3爬虫抓取豆瓣图书Top250,并利用xlwt模块将其存储至excel文件,图片下载到相应目录.旨在进行更多的爬虫实践练习以及模块学习. 工具 1.Python 3.5 2.Bea ...
- 【Python数据分析】Python3多线程并发网络爬虫-以豆瓣图书Top250为例
基于上两篇文章的工作 [Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 [Python数据分析]Python3操作Excel(二) 一些问题的解决与优化 已经正确地实现 ...
随机推荐
- day4 函数重载
函数的重载 1.函数重载的定义:在同一个类中,有一个以上的同名函数,只要函数的参数列表或参数类型不一样即可,与返回值无关, 这些统称为方法的重载. 2.函数的重载存在的原因:为了增强方法的阅读性,优化 ...
- Centos 6.5 下Nginx安装部署https服务器
一般我们都需要先装pcre, zlib,前者为了重写rewrite,后者为了gzip压缩.1.选定源码目录选定目录 /usr/local/cd /usr/local/2.安装PCRE库cd /usr/ ...
- c/c++ 获取mysql数据库以blob类型储存的图片
简单的code如下: #include <iostream> #include <fstream> #include <sstream> #include < ...
- 分层确定性钱包开发的代码实现(HD钱包服务)
HD Wallets的全称是Hierachical Deterministic Wallets, 对应中文是 分层确定性钱包. 这种钱包能够使用一组助记词来管理所有的账户的所有币种,在比特币的BIP3 ...
- pytest框架(四)
测试用例setup和teardown 代码示例一 # coding=utf-8 import pytest def setup_module(): print("setup_module:整 ...
- 四、python中表示组的概念与定义
现实世界中总是存在一组一组的事物,如俄罗斯方块.游戏中的技能.世界杯总决赛(8个小组,每组4个队) 一.python中如何表示“组”的概念 1.列表 1)定义 [1,2,3,4,5] type[1,2 ...
- SpringBoot2.0 基础案例(11):配置AOP切面编程,解决日志记录业务
本文源码 GitHub地址:知了一笑 https://github.com/cicadasmile/spring-boot-base 一.AOP切面编程 1.什么是AOP编程 在软件业,AOP为Asp ...
- java CDI
Scope声明周期 http://www.cnblogs.com/yjmyzz/p/javaee-cdi-bean-scope.html
- 黑马Mybatis day3 多表查询 1.xml配置方式 2.注解方式
package com.itheima.mozq; import com.itheima.domain.Order; import com.itheima.mapper.OrderMapper; im ...
- CSS标签大全
CSS常用标签 字体属性:(font) 大小:font-size: x-large;(特大) xx-small;(极小) 一般中文用不到,只要用数值就可以,单位:PX.PD 样式 :font-styl ...