scrapy_电影天堂多页数据和图片下载
嵌套的 爬取
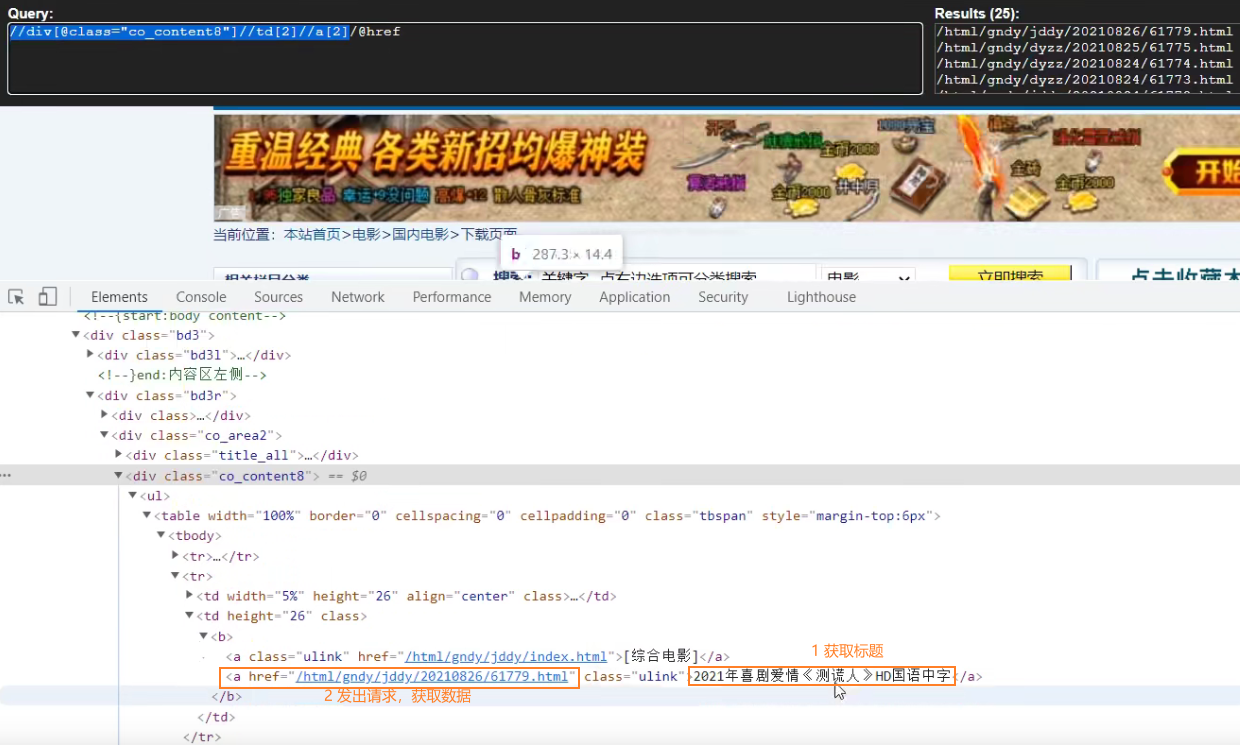
先获取第一页的标题
点击标题到第二页的图片url

1、创建项目
> scrapy startproject scrapy_movie_099
2、创建爬虫文件
spiders>scrapy genspider mv https: //www.dytt8.net/html/gndy/china/index.html
3、测试
5、运行
spiders> scrapy crawl mv

①、定义数据结构
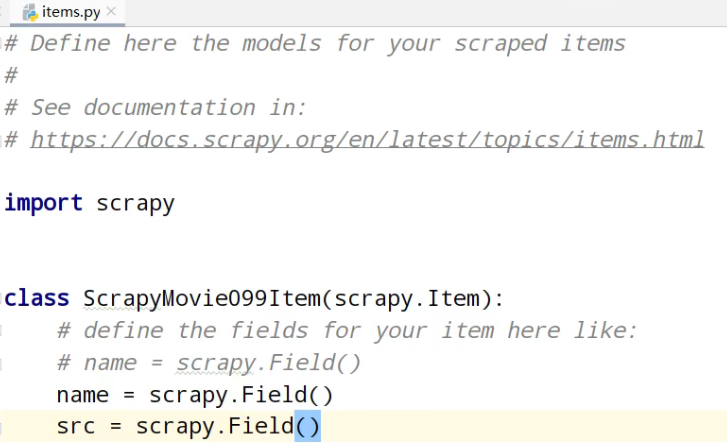
②、分析xpath
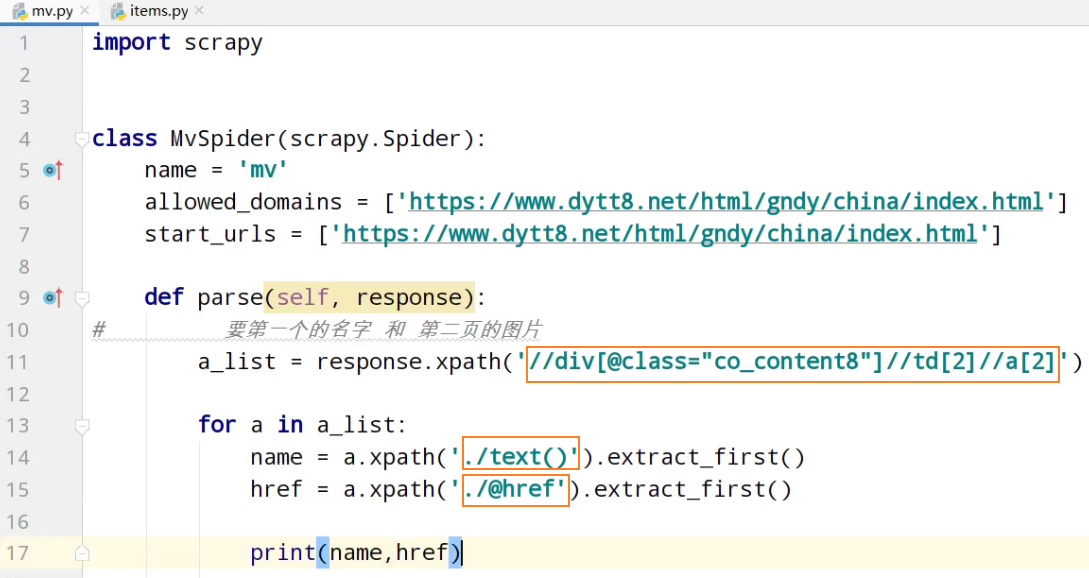
运行
spiders> scrapy crawl mv

分析第二页的地址

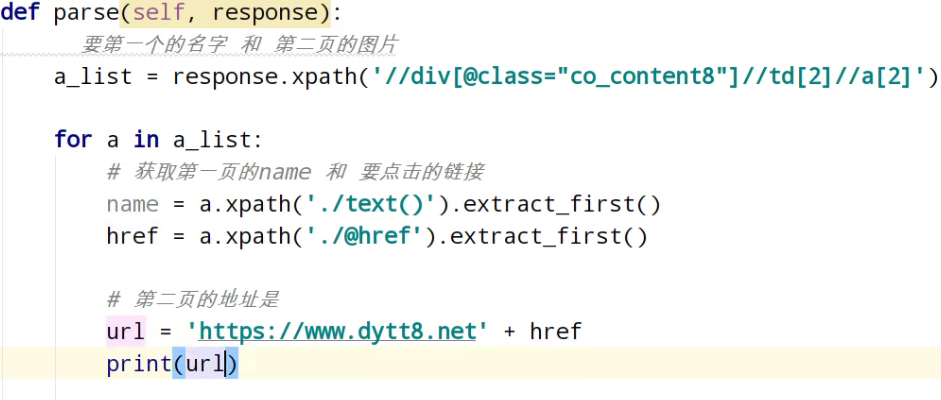
运行
spiders> scrapy crawl mv

测试

分析第二页的地址
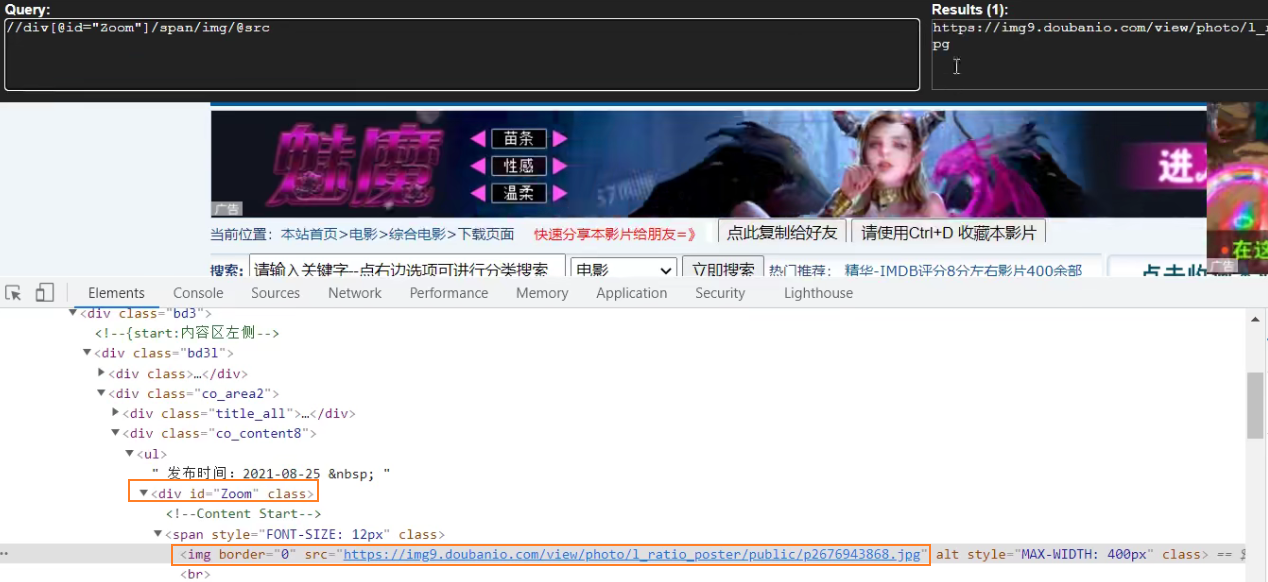
测试xpath,有些span标签识别不了。调试修改成 //div[@id="Zoom"]//img/@src
测试

查看转到定义request

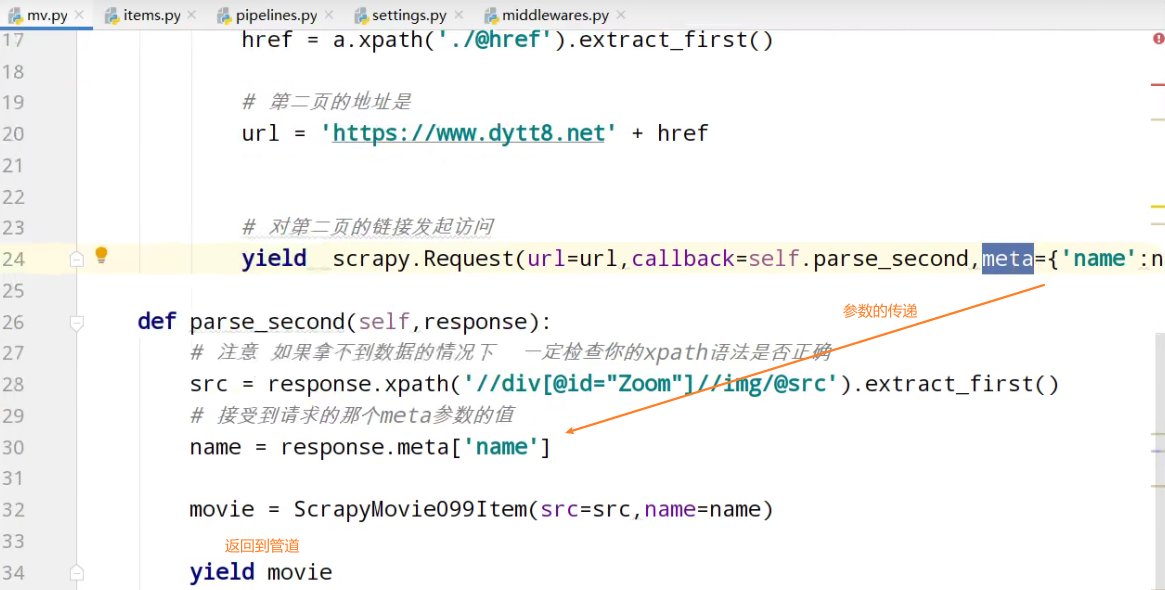
meta是个字典

导入数据结构类

movie返回个管道
settings中开启管道
pipeline管道的封装
运行
spiders> scrapy crawl mv

项目文件
爬虫核心文件mv.py
import scrapy from scrapy_movie_099.items import ScrapyMovie099Item class MvSpider(scrapy.Spider):
name = 'mv'
allowed_domains = ['www.dytt8.net']
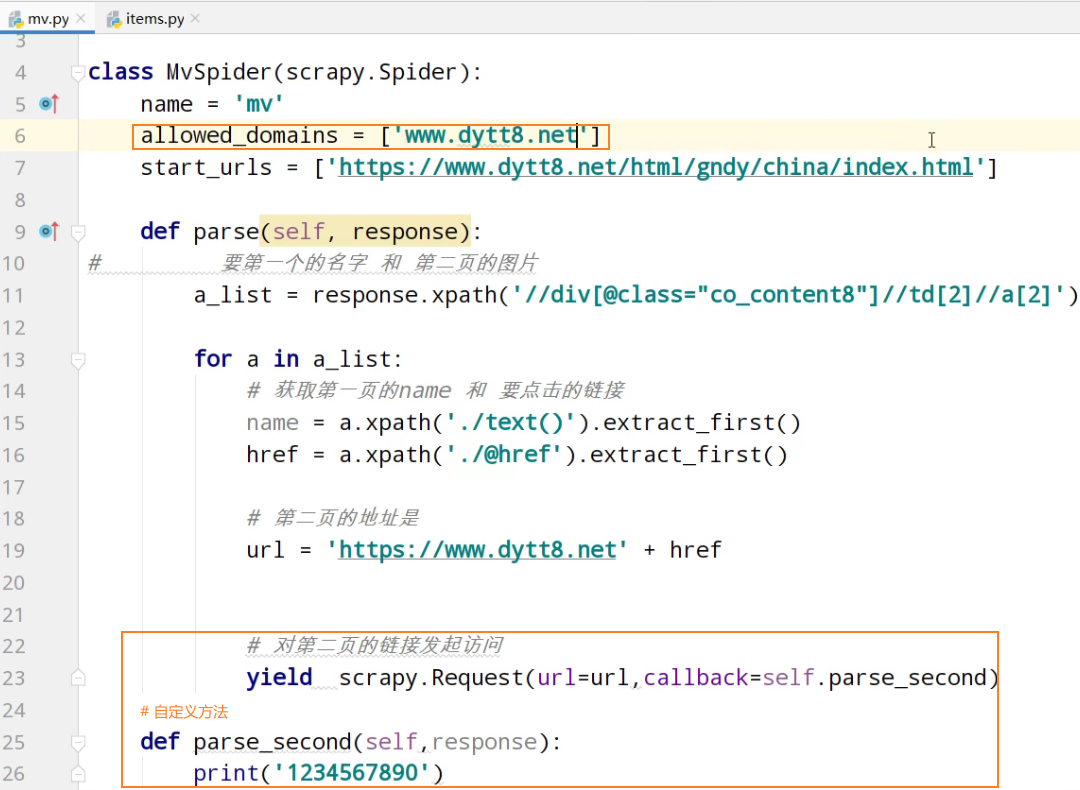
start_urls = ['https://www.dytt8.net/html/gndy/china/index.html'] def parse(self, response):
# 要第一个的名字 和 第二页的图片
a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[2]') for a in a_list:
# 获取第一页的name 和 要点击的链接
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first() # 第二页的地址是
url = 'https://www.dytt8.net' + href # 对第二页的链接发起访问
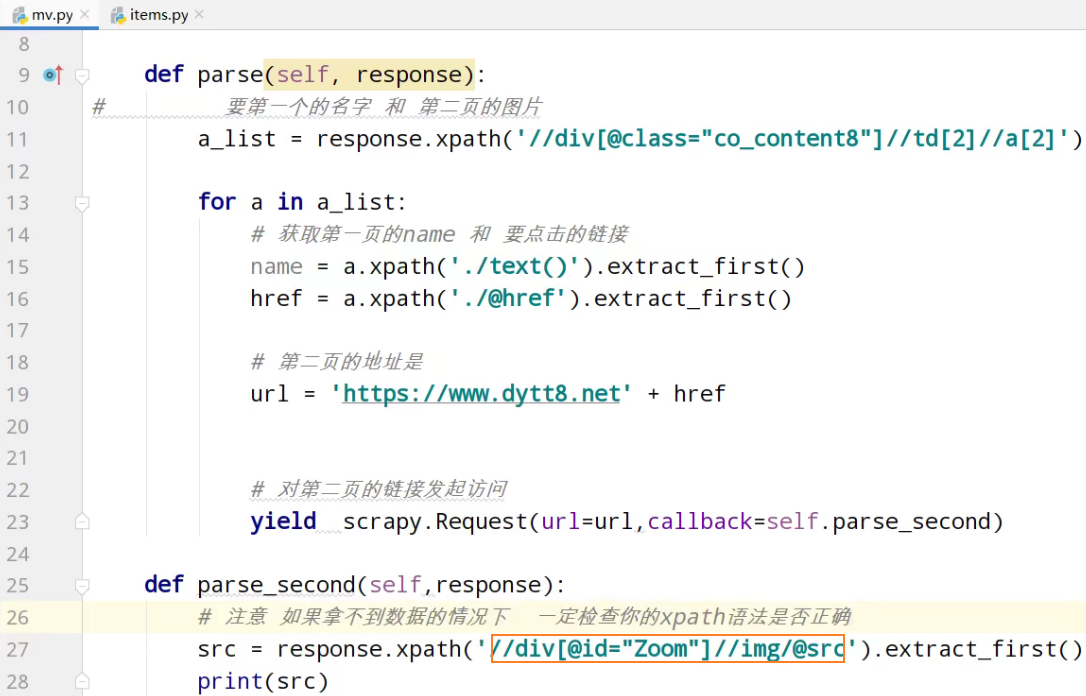
yield scrapy.Request(url=url,callback=self.parse_second,meta={'name':name}) def parse_second(self,response):
# 注意 如果拿不到数据的情况下 一定检查你的xpath语法是否正确
src = response.xpath('//div[@id="Zoom"]//img/@src').extract_first()
# 接受到请求的那个meta参数的值
name = response.meta['name'] movie = ScrapyMovie099Item(src=src,name=name) yield movie
items.py自定义结构类
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html import scrapy class ScrapyMovie099Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
src = scrapy.Field()
settings.py基本配置。robots协议配置,管道配置
# Scrapy settings for scrapy_movie_099 project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'scrapy_movie_099' SPIDER_MODULES = ['scrapy_movie_099.spiders']
NEWSPIDER_MODULE = 'scrapy_movie_099.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'scrapy_movie_099 (+http://www.yourdomain.com)' # Obey robots.txt rules
ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'scrapy_movie_099.middlewares.ScrapyMovie099SpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'scrapy_movie_099.middlewares.ScrapyMovie099DownloaderMiddleware': 543,
#} # Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
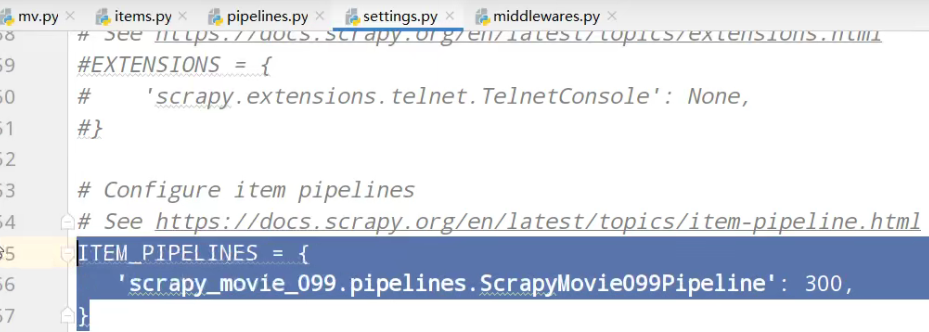
ITEM_PIPELINES = {
'scrapy_movie_099.pipelines.ScrapyMovie099Pipeline': 300,
} # Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
pipelines.py管道功能
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface
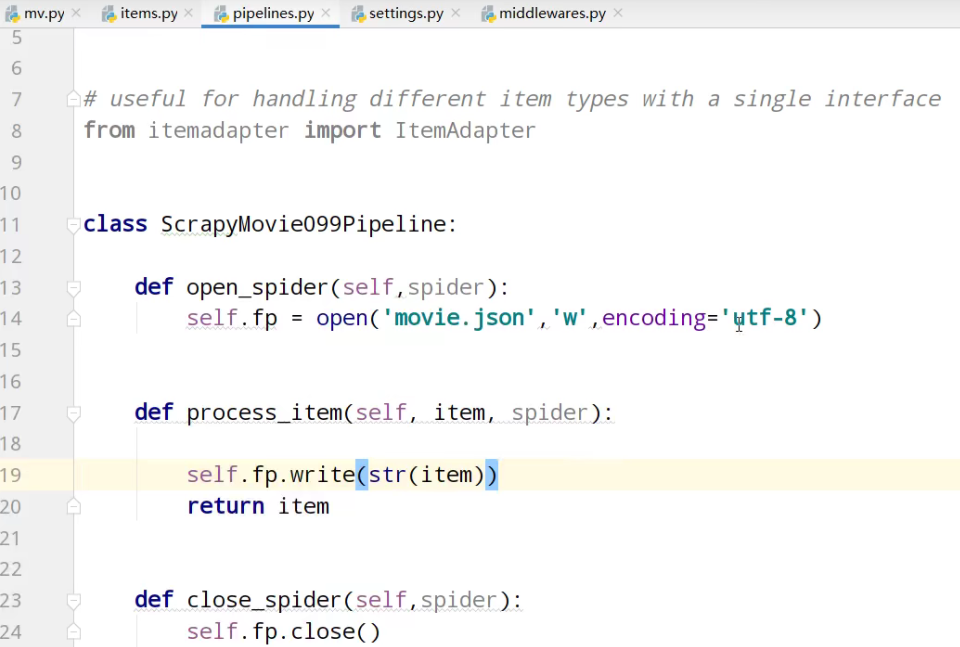
from itemadapter import ItemAdapter class ScrapyMovie099Pipeline: def open_spider(self,spider):
self.fp = open('movie.json','w',encoding='utf-8') def process_item(self, item, spider): self.fp.write(str(item))
return item def close_spider(self,spider):
self.fp.close()
scrapy_电影天堂多页数据和图片下载的更多相关文章
- 猫眼电影和电影天堂数据csv和mysql存储
字符串常用方法 # 去掉左右空格 'hello world'.strip() # 'hello world' # 按指定字符切割 'hello world'.split(' ') # ['hello' ...
- [py][mx]django添加后台课程机构页数据-图片上传设置
分析下课程页前台部分 机构类别-目前机构库中没有这个字段,需要追加下 所在地区 xadmin可以手动添加 课程机构 涉及到机构封面图, 即图片上传media设置, 也需要在xadmin里手动添加几条 ...
- ajax的get方法获取豆瓣电影前10页的数据
# _*_ coding : utf-8 _*_ # @Time : 2021/11/2 11:45 # @Author : 秋泊酱 # 1页数据 电影条数20 # https://movie.dou ...
- python爬取豆瓣电影第一页数据and使用with open() as读写文件
# _*_ coding : utf-8 _*_ # @Time : 2021/11/2 9:58 # @Author : 秋泊酱 # @File : 获取豆瓣电影第一页 # @Project : 爬 ...
- python利用requests和threading模块,实现多线程爬取电影天堂最新电影信息。
利用爬到的数据,基于Django搭建的一个最新电影信息网站: n1celll.xyz (用的花生壳动态域名解析,服务器在自己的电脑上,纯属自娱自乐哈.) 今天想利用所学知识来爬取电影天堂所有最新电影 ...
- Node.js 抓取电影天堂新上电影节目单及ftp链接
代码地址如下:http://www.demodashi.com/demo/12368.html 1 概述 本实例主要使用Node.js去抓取电影的节目单,方便大家使用下载. 2 node packag ...
- 使用Requests+正则表达式爬取猫眼TOP100电影并保存到文件或MongoDB,并下载图片
需要着重学习的地方:(1)爬取分页数据时,url链接的构建(2)保存json格式数据到文件,中文显示问题(3)线程池的使用(4)正则表达式的写法(5)根据图片url链接下载图片并保存(6)MongoD ...
- scrapy电影天堂实战(二)创建爬虫项目
公众号原文 创建数据库 我在上一篇笔记中已经创建了数据库,具体查看<scrapy电影天堂实战(一)创建数据库>,这篇笔记创建scrapy实例,先熟悉下要用到到xpath知识 用到的xpat ...
- 14.python案例:爬取电影天堂中所有电视剧信息
1.python案例:爬取电影天堂中所有电视剧信息 #!/usr/bin/env python3 # -*- coding: UTF-8 -*- '''======================== ...
随机推荐
- Codeforces Round #747 (Div. 2)
比赛地址 A(水题) 题目链接 题目: 给出指定\(n\),求解出一段区间\([l,r]\)使得\(\sum\limits_{i=l}^ri=n\) 解析: 从点0,1两点作为起点分别向左右延伸长度, ...
- 使用CEF(二)— 基于VS2019编写一个简单CEF样例
使用CEF(二)- 基于VS2019编写一个简单CEF样例 在这一节中,本人将会在Windows下使用VS2019创建一个空白的C++Windows Desktop Application项目,逐步进 ...
- Java标识符和关键字的区别!java基础 java必学
任何计算机语言都离不开标识符和关键字,那我们就来简单讲一下他们两者的区别,希望有助于大家的的理解!本篇文章干货满满,如果你觉得难懂的话可以看下高淇老师讲的Java300集的教学视频,分选集,深度剖析了 ...
- CF739E Gosha is hunting(费用流/凸优化dp)
纪念合格考爆炸. 其实这个题之前就写过博客了,qwq但是不小心弄丢了,所以今天来补一下. 首先,一看到球的个数的限制,不难相当用网络流的流量来限制每个球使用的数量. 由于涉及到最大化期望,所以要使用最 ...
- java链接并操作数据库
链接准备 MySQL数据库驱动(连接器).mysql-connector-java-x.x.xx.jar会在MySQL安装时提供,若Mysql是默认安装路径,则连接器在:C:\Program File ...
- C++ 与 Visual Studio 2019 和 WSL(四)——库组件
C++ 与 Visual Studio 2019 和 WSL (库组件) Reference 在 C++ 项目中使用库和组件 | Microsoft Docs 演练:创建和使用自己的动态链接库 (C+ ...
- 初学python-day5 集合
- Unity——伤害数字显示HUD
伤害数字显示HUD 游戏中收到伤害掉血,会有飘动的伤害数值: 可以使用OnGUI中GUI.Label来实现: 可自定义字体,颜色,大小等: 如果需要更好看的数字特效,可以手动添加: 普通字体不够好看可 ...
- Spring Cloud Gateway + Jwt + Oauth2 实现网关的鉴权操作
Spring Cloud Gateway + Jwt + Oauth2 实现网关的鉴权操作 一.背景 二.需求 三.前置条件 四.项目结构 五.网关层代码的编写 1.引入jar包 2.自定义授权管理器 ...
- 单片机stm32F103单片机晶振不起振的原因分析
这是我在做单片机最小系统板时候碰到的问题,之前虽然也做过相似的板子,可是未曾出现过无源晶振不起振的问题.下面是我在遇到问题后的一些检查,排除问题的过程.本人小菜鸟一个,文章中如有错误和不足,还望各位大 ...