爬虫技术 -- 进阶学习(七)简单爬虫抓取示例(附c#代码)
这是我的第一个爬虫代码。。。算是一份测试版的代码。大牛大神别喷。。。
通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配。
List<string> todo :进行抓取的网址的集合
List<string> visited :已经访问过的网址的集合
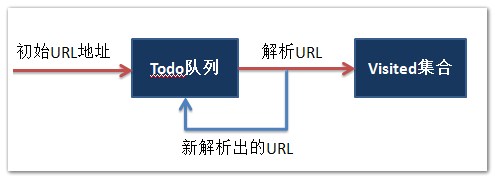
下面实现的是,给定一个初始地址,然后进行爬虫,输出正在访问的网址和已经访问的网页的个数。
需要注意的是,下面代码实现的链接匹配页面的内容如图一、图二所示:
- 图一:

- 图二:

简单代码示范如下:(测试版)
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Web.Security;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web; namespace Demo1
{ public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
} private void button1_Click(object sender, EventArgs e)
{
Test1 a = new Test1();
a.getCurrentURL();
} public class Test1
{
List<string> todo = new List<string>();
List<string> visited = new List<string>();
string startPoint = "http://www.cnblogs.com/lmei/";
public void getCurrentURL()
{
RequestSite(startPoint); while (todo.Count > )
{
string currentURL = todo[]; RequestSite(currentURL); if (visited.Contains(currentURL)) //注释1
{
Console.WriteLine("已经访问过了" + currentURL);
todo.Remove((currentURL));
}
else
{
Console.WriteLine("现在正在访问:===> " + currentURL);
visited.Add(currentURL); Console.WriteLine("目前已经访问了:===> " + visited.Count + "个网页" );
todo.Remove((currentURL));
}
}
} public void RequestSite(string url)
{
WebRequest req = WebRequest.Create(url);
HttpWebResponse res;
try{
res = (HttpWebResponse)(req.GetResponse());
}
catch (WebException ex) { res = (HttpWebResponse)ex.Response; } Stream st = res.GetResponseStream();
StreamReader rdr = new StreamReader(st);
string s = rdr.ReadToEnd();
todo.AddRange(GetLink(s));
} List<string> GetLink(string htmlPage)
{ Regex regx =
new Regex("http://www\\.cnblogs\\.com\\/lmei\\/p\\/[0-9a-zA-Z]+\\.html*" ,RegexOptions.IgnoreCase);
MatchCollection matches = regx.Matches(htmlPage); List<string> results = new List<string>();
foreach (Match match in matches)
{
if (!visited.Contains(match.Value)) //注释2
{
results.Add(match.Value);
}
}
return results;
}
} }
}
注释1 :是将已经访问过的网址排除。
注释2 :是将已经访问过的网址排除,但是可能由于同个网页中包含的两个(或两个以上)相同的链接,而且都没被访问过的,这样使得todo队列中会有相同的网址,所以需要注释1那部分进行再次过滤排除。其实也可以将注释2那部分删去,直接让注释1过滤就行。
接下来会进一步补充爬虫抓取的内容。。。
爬虫技术 -- 进阶学习(七)简单爬虫抓取示例(附c#代码)的更多相关文章
- 爬虫技术 -- 进阶学习(十)网易新闻页面信息抓取(htmlagilitypack搭配scrapysharp)
最近在弄网页爬虫这方面的,上网看到关于htmlagilitypack搭配scrapysharp的文章,于是决定试一试~ 于是到https://www.nuget.org/packages/Scrapy ...
- 爬虫技术(四)-- 简单爬虫抓取示例(附c#代码)
这是我的第一个爬虫代码...算是一份测试版的代码.大牛大神别喷... 通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配. List<string&g ...
- 爬虫技术 -- 进阶学习(九)使用HtmlAgilityPack获取页面链接(附c#代码及插件下载)
菜鸟HtmlAgilityPack初体验...弱弱的代码... Html Agility Pack是一个开源项目,为网页提供了标准的DOM API和XPath导航.使用WebBrowser和HttpW ...
- 爬虫技术 -- 进阶学习(十一)【补充】获取html中meta标签中的content的内容
上一篇网易新闻页面信息抓取 -- htmlagilitypack搭配scrapysharp中提及了很多如何快速抓取html中的文本的语句, 但是meta标签中的content内容的抓取,没有提及到! ...
- 爬虫技术 -- 进阶学习(八)模拟简单浏览器(附c#代码)
由于最近在做毕业设计,需要用到一些简单的浏览器功能,于是学习了一下,顺便写篇博客~~大牛请勿喷,菜鸟练练手~ 实现界面如下:(简单朴素版@_@||) button_go实现如下: private vo ...
- 爬虫技术 -- 基础学习(一)HTML规范化(附特殊字符编码表)
最近在做网页信息提取这方面的,由于没接触过这系列的知识点,所以逛博客,看文档~~看着finallyly大神的博文和文档,边看边学习边总结~~ 对网站页面进行信息提取,需要进行页面解析,解析的方法有以下 ...
- 爬虫学习一系列:urllib2抓取网页内容
爬虫学习一系列:urllib2抓取网页内容 所谓网页抓取,就是把URL地址中指定的网络资源从网络中读取出来,保存到本地.我们平时在浏览器中通过网址浏览网页,只不过我们看到的是解析过的页面效果,而通过程 ...
- python3爬虫再探之豆瓣影评数据抓取
一个关于豆瓣影评的爬虫,涉及:模拟登陆,翻页抓取.直接上代码: import re import time import requests import xlsxwriter from bs4 imp ...
- [python应用]python简单图片抓取
前言 emmmm python简单图片抓取 1 import requests 2 import threading 3 import queue 4 from subprocess import P ...
随机推荐
- 建立一个名叫Cat的类
//属性 成员变量 String name; int age; String color; //方法 函数 成员函数 void name() { System.out.println("名字 ...
- iOS开发Swift篇(02) NSThread线程相关简单说明
iOS开发Swift篇(02) NSThread线程相关简单说明 一 说明 1)关于多线程部分的理论知识和OC实现,在之前的博文中已经写明,所以这里不再说明. 2)该文仅仅简单讲解NSThread在s ...
- 分享45个设计师应该见到的新鲜的Web移动设备用户界面PSD套件
对于一个网页设计师来说做一个好的PSD模板是非常有挑战性的一项任务,虽然PSD的模板简化了设计任务,但找出高质量的PSD文件,可以自由使用,是一 项艰巨的任务.你必须通过许多网页去找出一个极少数的PS ...
- 关于H.264 x264 h264 AVC1
1. H.264是MPEG4的第十部分,是一个标准.对头,国际上两个视频专家组(VCEG和MPEG)合作提出的标准,两个专家组各有各的叫法,所以既叫H.264,也叫AVC. 2.x264是一个编码器, ...
- 基于JQuery.timer插件实现一个计时器
基于JQuery.timer插件实现一个计时器,需要的朋友可以参考下. 先去官网下载jQuery Timers插件 ,然后引用到html中.这里是1.2 version 复制代码代码如下: < ...
- android手机两种方式获取IP地址
1.使用WIFI 首先设置用户权限 <uses-permission android:name="android.permission.ACCESS_WIFI_STATE"& ...
- 关于ios中得路径详细讲解
利用create groups for any added folders 这样的方式表示的是将所有的资源都放在资源包得路径下,没有层次的概念利用create folder references fo ...
- 笔记 - 本地拦截genymotion或者Android模拟器的网络请求
我们在主机上面运行了Burp或者fiddler,那么代理已经监听在本机的8080端口了. 那么我们需要在模拟器中进行如下设置: 1.在设置中,长按当前连接的wifi网络,弹出如下: 2. 点击修改网络 ...
- requirejs、backbone.js配置
requirejs初探 参考资料官网:http://requirejs.org中文译文:http://makingmobile.org/docs/tools/requirejs-api-zh reuq ...
- Python 中Editplus 特别实用的设置方法
editplus 中输入tab自动变成4个空格打开tools->preference打开面板,files的子栏目->settings & syntax面板中的 tab/indent ...