python scrapy+Mongodb爬取蜻蜓FM,酷我及懒人听书
- 1、初衷:想在网上批量下载点听书、脱口秀之类,资源匮乏,大家可以一试
- 2、技术:wireshark scrapy jsonMonogoDB
- 3、思路:wireshark分析移动APP返回的各种连接分类、列表、下载地址等(json格式)
- 4、思路:scrapy解析json,并生成下载连接
- 5、思路:存储到MongoDB
- 6、难点:wireshark分析各类地址,都是简单的scrapy的基础使用,官网的说明文档都有
- 7、按照:tree /F生成的文件目录进行说明吧
1 items.py 字段设置,根据需要改变
'''
from scrapy import Item,Field
class QtscrapyItem(Item):
id = Field()
parent_info = Field()
title = Field()
update_time = Field()
file_path = Field()
source = Field()
'''
2 pipelines.py 字段设置及相关处理,根据需要改变
'''
import pymongo as pymongo
from scrapy import signals
import json
import codecs
from scrapy.conf import settings
class QtscrapyPipeline(object):
def init(self):
self.file = codecs.open('qingting_209.json', 'wb', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
# print(line)
self.file.write(line)
return item
class QtscrapyMongoPipeline(object):
def init(self):
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
dbName = settings['MONGODB_DBNAME']
client = pymongo.MongoClient(host=host, port=port)
tdb = client[dbName]
self.post = tdb[settings['MONGODB_DOCNAME']]
def process_item(self, item, spider):
qtfm = dict(item)
self.post.insert(qtfm)
return item
'''
3 settings.py 基础配置 配置数据库存储相关 QtscrapyPipeline 来自pipelines.py中定义的类
'''
ITEM_PIPELINES = {
# 'qtscrapy.pipelines.QtscrapyPipeline': 300,
'qtscrapy.pipelines.QtscrapyMongoPipeline': 300,
}
MONGODB_HOST = '127.0.0.1'
MONGODB_PORT = 12345
MONGODB_DBNAME = 'qingtingDB'
MONGODB_DOCNAME = 'qingting'
'''
└─spiders
4 qingting.py 爬虫,各显神通
'''
from scrapy.spiders import BaseSpider
from scrapy.http import Request
import sys, json
from qtscrapy.items import QtscrapyItem
from scrapy_redis.spiders import RedisSpider
reload(sys)
sys.setdefaultencoding("utf-8")
1 酷我听书地址分析
http://ts.kuwo.cn/service/gethome.php?act=new_home
http://ts.kuwo.cn/service/getlist.v31.php?act=catlist&id=97
http://ts.kuwo.cn/service/getlist.v31.php?act=cat&id=21&type=hot
http://ts.kuwo.cn/service/getlist.v31.php?act=detail&id=100102396
2 配合Redis使用class qtscrapy(RedisSpider):
class qtscrapy(BaseSpider):
name = "qingting"
# redis_key = 'qingting:start_urls'
base_url = "http://api2.qingting.fm/v6/media/recommends/guides/section/"
start_urls = ["http://api2.qingting.fm/v6/media/recommends/guides/section/0",
"http://ts.kuwo.cn/service/gethome.php?act=new_home",
"http://api.mting.info/yyting/bookclient/ClientTypeResource.action?type=0&pageNum=0&pageSize=500&token=_4WfzpCah8ujgJZZzboaUGkJQvWGfEEL-zdukwv7lbY*&q=0&imei=ODY1MTY2MDIxNzMzNjI0"]
allowed_domains = ["api2.qingting.fm", "ts.kuwo.cn", "api.mting.info"]
def parse(self, response):
3 根据返回的url判断,在思考是scrapy执行多爬虫还是这种混杂
if "qingting" in response.url:
qt_json = json.loads(response.body, encoding="utf-8")
if qt_json["data"] is not None:
for data in qt_json["data"]:
if data is not None:
for de in data["recommends"]:
if de["parent_info"] is None:
pass
else:
jm_url = "http://api2.qingting.fm/v6/media/channelondemands/%(parent_id)s/programs/curpage/1/pagesize/1000" % \
de["parent_info"]
yield Request(jm_url, callback=self.get_qt_jmlist, meta={"de": de})
for i in range(0, 250):
url = self.base_url + str(i)
yield Request(url, callback=self.parse)
if "kuwo" in response.url:
kw_json = json.loads(response.body, encoding="utf-8")
if kw_json["cats"] is not None:
for data in kw_json["cats"]:
pp_id = data["Id"]
kw_url = "http://ts.kuwo.cn/service/getlist.v31.php?act=catlist&id=%s" % pp_id
yield Request(kw_url, callback=self.get_kw_catlist)
if "mting" in response.url:
# print(response)
lr_json = json.loads(response.body, encoding="utf-8")
if len(lr_json["list"]) > 0:
for l in lr_json["list"]:
try:
lr_url = "http://api.mting.info/yyting/bookclient/ClientTypeResource.action?type=%(id)s&pageNum=0&pageSize=1000&sort=2&token=_4WfzpCah8ujgJZZzboaUGkJQvWGfEEL-zdukwv7lbY*&imei=ODY1MTY2MDIxNzMzNjI0" % l
yield Request(lr_url, callback=self.get_lr_booklist)
except:
pass
for r in range(-10, 1000):
lr_url = "http://api.mting.info/yyting/bookclient/ClientTypeResource.action?type=%s&pageNum=0&pageSize=1000&token=_4WfzpCah8ujgJZZzboaUGkJQvWGfEEL-zdukwv7lbY*&q=0&imei=ODY1MTY2MDIxNzMzNjI0" % t
yield Request(lr_url, callback=self.parse)
4 需递归几次是由App结构决定的
def get_qt_jmlist(self, response):
jm_json = json.loads(response.body, encoding="utf-8")
de = response.meta["de"]
for jm_data in jm_json["data"]:
if jm_data is None:
pass
else:
try:
file_path = "http://upod.qingting.fm/%(file_path)s?deviceid=ffffffff-ebbe-fdec-ffff-ffffb1c8b222" % \
jm_data["mediainfo"]["bitrates_url"][0]
item = QtscrapyItem()
# print(item)
# print(jm_data["id"])
item["id"] = str(jm_data["id"])
parent_info = "%(parent_id)s_%(parent_name)s" % de["parent_info"]
item["parent_info"] = parent_info
item["title"] = jm_data["title"]
item["update_time"] = str(jm_data["update_time"])[:str(jm_data["update_time"]).index(' ')]
item["file_path"] = file_path
item["source"] = "qingting"
yield item
except:
pass
pass
def get_kw_catlist(self, response):
try:
kw_json = json.loads(response.body, encoding="utf-8")
if kw_json["sign"] is not None:
if kw_json["list"] is not None:
for data in kw_json["list"]:
p_id = data["Id"]
kw_p_url = "http://ts.kuwo.cn/service/getlist.v31.php?act=cat&id=%s&type=hot" % p_id
yield Request(kw_p_url, callback=self.get_kw_cat)
except:
print("*" * 300)
print(self.name, kw_json)
pass
def get_kw_cat(self, response):
try:
kw_json = json.loads(response.body, encoding="utf-8")
p_info = {}
if kw_json["sign"] is not None:
if kw_json["list"] is not None:
for data in kw_json["list"]:
id = data["Id"]
p_info["p_id"] = data["Id"]
p_info["p_name"] = data["Name"]
kw_pp_url = "http://ts.kuwo.cn/service/getlist.v31.php?act=detail&id=%s" % id
yield Request(kw_pp_url, callback=self.get_kw_jmlist, meta={"p_info": p_info})
except:
print("*" * 300)
print(self.name, kw_json)
pass
def get_kw_jmlist(self, response):
jm_json = json.loads(response.body, encoding="utf-8")
p_info = response.meta["p_info"]
for jm_data in jm_json["Chapters"]:
if jm_data is None:
pass
else:
try:
file_path = "http://cxcnd.kuwo.cn/tingshu/res/WkdEWF5XS1BB/%s" % jm_data["Path"]
item = QtscrapyItem()
item["id"] = str(jm_data["Id"])
parent_info = "%(p_id)s_%(p_name)s" % p_info
item["parent_info"] = parent_info
item["title"] = jm_data["Name"]
item["update_time"] = ""
item["file_path"] = file_path
item["source"] = "kuwo"
yield item
except:
pass
pass
def get_lr_booklist(self, response):
s_lr_json = json.loads(response.body, encoding="utf-8")
if len(s_lr_json["list"]) > 0:
for s_lr in s_lr_json["list"]:
s_lr_url = "http://api.mting.info/yyting/bookclient/ClientGetBookResource.action?bookId=%(id)s&pageNum=1&pageSize=2000&sortType=0&token=_4WfzpCah8ujgJZZzboaUGkJQvWGfEEL-zdukwv7lbY*&imei=ODY1MTY2MDIxNzMzNjI0" % s_lr
meta = {}
meta["id"] = s_lr["id"]
meta["name"] = s_lr["name"]
yield Request(s_lr_url, callback=self.get_lr_kmlist, meta={"meta": meta})
def get_lr_kmlist(self, response):
ss_lr_json = json.loads(response.body, encoding="utf-8")
parent = response.meta["meta"]
if len(ss_lr_json["list"]) > 0:
for ss_lr in ss_lr_json["list"]:
try:
item = QtscrapyItem()
item["id"] = str(ss_lr["id"])
parent_info = "%(id)s_%(name)s" % parent
item["parent_info"] = parent_info
item["title"] = ss_lr["name"]
item["update_time"] = ""
item["file_path"] = ss_lr["path"]
item["source"] = "lr"
yield item
except:
pass
'''
5 结果展示,爬取了大概40万记录
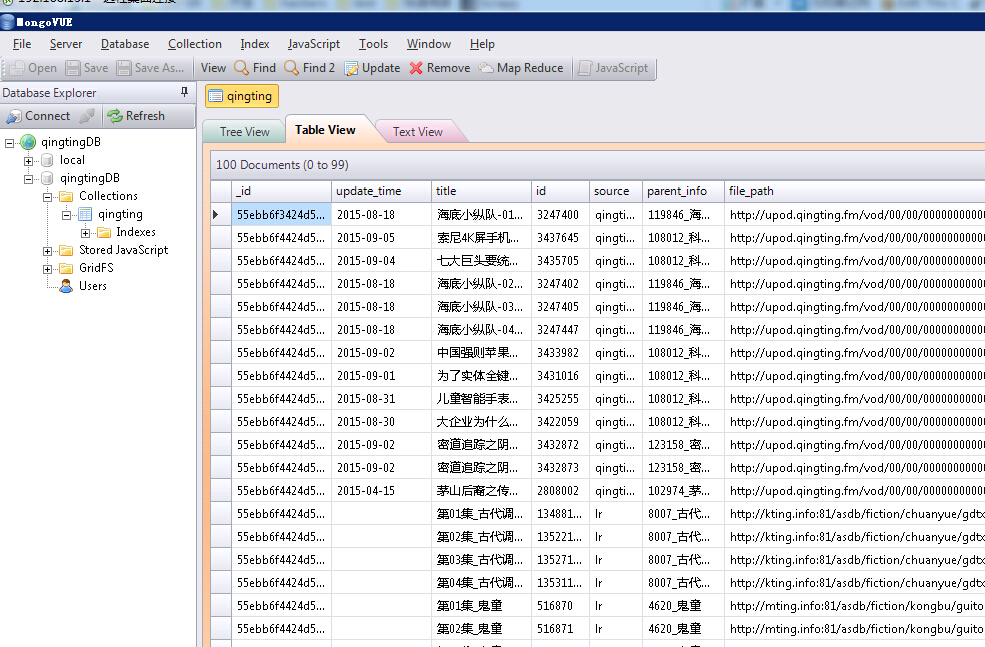
python scrapy+Mongodb爬取蜻蜓FM,酷我及懒人听书的更多相关文章
- 教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点: 之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以 ...
- Python scrapy框架爬取瓜子二手车信息数据
项目实施依赖: python,scrapy ,fiddler scrapy安装依赖的包: 可以到https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载 pywi ...
- python scrapy框架爬取豆瓣
刚刚学了一下,还不是很明白.随手记录. 在piplines.py文件中 将爬到的数据 放到json中 class DoubanmoviePipelin2json(object):#打开文件 open_ ...
- Python+Scrapy+Crawlspider 爬取数据且存入MySQL数据库
1.Scrapy使用流程 1-1.使用Terminal终端创建工程,输入指令:scrapy startproject ProName 1-2.进入工程目录:cd ProName 1-3.创建爬虫文件( ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- python+selenium+PhantomJS爬取网页动态加载内容
一般我们使用python的第三方库requests及框架scrapy来爬取网上的资源,但是设计javascript渲染的页面却不能抓取,此时,我们使用web自动化测试化工具Selenium+无界面浏览 ...
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- Scrapy+selenium爬取简书全站
Scrapy+selenium爬取简书全站 环境 Ubuntu 18.04 Python 3.8 Scrapy 2.1 爬取内容 文字标题 作者 作者头像 发布日期 内容 文章连接 文章ID 思路 分 ...
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
随机推荐
- Javascript单元测试Unit Testing之QUnit
body{ font: 16px/1.5em 微软雅黑,arial,verdana,helvetica,sans-serif; } QUnit是一个基于JQuery的单元测试Uni ...
- Java异常的中断和恢复
中断:抛出一个异常类的实例而终止现有程序的执行:恢复:不是抛出一个异常类的实例,而是调用一个用于解决问题的方法或就地解决问题. 在Java中,对那些要调用方法的客户程序员,我们要通知他们可能从自己的方 ...
- Eclipse的SVN插件提示:验证验证位置时发生错误:"Unable to load default SVN Client“解决
这个原因是你的机器上没有 JAVAHL 这个包, 这个是另外的一个开源组件, 所以, 在trigis的svn插件发行版里面没有这个东西,下载装上就是, 这个包在不同的系统上, 有不同的情况...详情见 ...
- jQuery Panorama Viewer – 360度全景展示插件
jQuery Panorama Viewer 这款插件可以帮助你在网站中嵌入全景图片.要做到这一点,首先只需要在页面中引入最新的 jQuery 库,以及 jquery.panorama_viewer. ...
- 25款响应式,支持视网膜显示的 Wordpress 主题
响应式和现代设计风格的多用途 WordPress 主题与能够非常灵活的适应所有设备.而高级主题能够更大可能性的轻松定制.所有的主题是完全响应式的,您可以从主题选项中禁用/启用响应模式. 多用途的响应式 ...
- checkbox全选,反选,取消选择 jquery
checkbox全选,反选,取消选择 jquery. //checkbox全部选择 $(":checkbox[name='osfipin']").each(function(){ ...
- 网页引用本地电脑的字体 css设置浏览器会不显示的解决办法
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- .NET破解之图片下载器
自去年五月加入吾爱后,学习了三个月,对逆向破解产生了深厚的兴趣,尤其是对.NET方面的分析:但由于这一年,项目比较忙,事情比较多,破解这方面又停滞了许久,不知道还要好久. 前些天,帮忙批量下载QQ相册 ...
- 如何在sharepoint2010中配置Google Anlytics 分析服务
简介 Google Analytics(分析)不仅可以帮助您衡量销售与转化情况,而且能为您提供新鲜的深入信息,帮助您了解访问者如何使用您的网站,他们如何到达您的网站,以及您可以如何吸引他们不断回访 ...
- 如何排查sharepoint2010用户配置文件同步服务启动问题
用户配置文件同步服务与 Microsoft Forefront Identity Manager (FIM) 交互,以与外部系统(如目录服务和业务系统)同步配置文件信息.启用用户配置文件同步服务时,将 ...