spark集群搭建(三台虚拟机)——spark集群搭建(5)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下:
virtualBox5.2、Ubuntu14.04、securecrt7.3.6_x64英文版(连接虚拟机)
jdk1.7.0、hadoop2.6.5、zookeeper3.4.5、Scala2.12.6、kafka_2.9.2-0.8.1、spark1.3.1-bin-hadoop2.6
本文在前面基础上搭建spark
一、spark1
下面操作在spark1上:
1、spark(spark1.3.1-bin-hadoop2.6)下载解压重命名
2、配置环境变量
export SPARK_HOME=/usr/local/bigdata/spark
export PATH=$PATH:$SPARK_HOME/bin
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
修改配置文件
1、spark-env.sh
$ cd ./spark/conf #进入spark的conf目录下
$ mv spark-env.sh.template spark-env.sh
$ vim spark-env.sh
添加如下配置
export JAVA_HOME=/usr/local/bigdata/jdk
export SCALA_HOME=/usr/local/bigdata/scala
export SPARK_MASTER_IP=192.168.43.XXX
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/local/bigdata/hadoop/etc/hadoop
2、slaves
$ mv slaves.template slaves
$ vim slaves
添加三台主机名
spark1
spark2
spark3
二、spark2和spark3
1、拷贝spark到另外两台机器上
root@spark1:/usr/local/bigdata# scp -r spark root@spark2://usr/local/bigdata/
root@spark1:/usr/local/bigdata# scp -r spark root@spark3://usr/local/bigdata/
2、同理配置spark2和spark3的环境变量,或者直接把环境变量文件拷贝过去
三、启动spark
进入spark的sbin目录下,执行:
$ ./start-all.sh
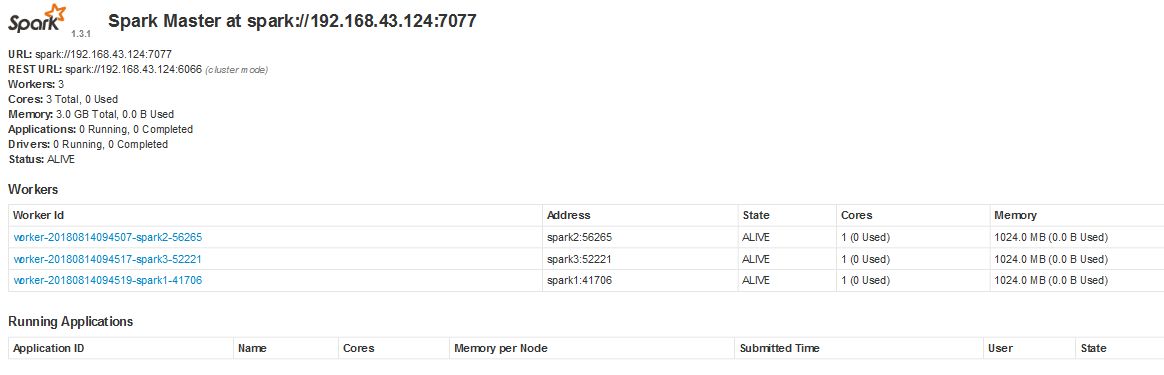
此时查看jps,spark1上有Master
root@spark1:/usr/local/bigdata/spark/sbin# jps
Worker
NodeManager
SecondaryNameNode
Jps
NameNode
Master
ResourceManager
DataNode
spark2
root@spark2:/usr/local/bigdata# jps
Jps
NodeManager
Worker
DataNode
spark3
root@spark3:/usr/local/bigdata# jps
Jps
NodeManager
Worker
DataNode
浏览器输入http://spark1:8080/
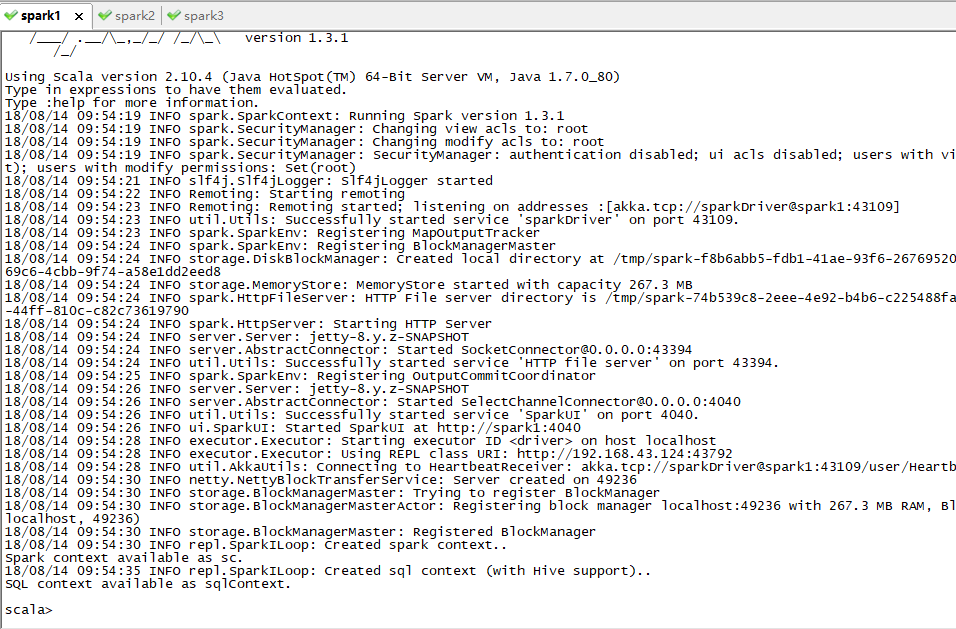
$ spark-shell #进入shell
spark集群搭建(三台虚拟机)——spark集群搭建(5)的更多相关文章
- Centos 7下VMware三台虚拟机Hadoop集群初体验
一.下载并安装Centos 7 传送门:https://www.centos.org/download/ 注:下载DVD ISO镜像 这里详解一下VMware安装中的两个过程 网卡配置 是Add ...
- spark集群搭建(三台虚拟机)——kafka集群搭建(4)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- spark集群搭建(三台虚拟机)——zookeeper集群搭建(3)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- spark集群搭建(三台虚拟机)——hadoop集群搭建(2)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- spark集群搭建(三台虚拟机)——系统环境搭建(1)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- AWS EC2 搭建 Hadoop 和 Spark 集群
前言 本篇演示如何使用 AWS EC2 云服务搭建集群.当然在只有一台计算机的情况下搭建完全分布式集群,还有另外几种方法:一种是本地搭建多台虚拟机,好处是免费易操控,坏处是虚拟机对宿主机配置要求较高, ...
- Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群
一.集群规划 这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop00 ...
- 用三台虚拟机搭建Hadoop全分布集群
用三台虚拟机搭建Hadoop全分布集群 所有的软件都装在/home/software下 虚拟机系统:centos6.5 jdk版本:1.8.0_181 zookeeper版本:3.4.7 hadoop ...
- 一台虚拟机,基于docker搭建大数据HDP集群
前言 好多人问我,这种基于大数据平台的xxxx的毕业设计要怎么做.这个可以参考之前写得关于我大数据毕业设计的文章.这篇文章是将对之前的毕设进行优化. 个人觉得可以分为两个部分.第一个部分就是基础的平台 ...
随机推荐
- JZOJ5771【NOIP2008模拟】遨游
Description MWH寒假外出旅游,来到了S国.S国划分为N个省,第i个省有Ti座城市,编号分别为Ci1,Ci2,……CiTi(各省城市编号不会重复).所有城市间有M条双向的道路连接 ...
- table表格中文字超出显示省略号
第一步: table {table-layout:fixed:}列宽由表格宽度和列宽度设定,不随文字多少变化 第二步: td { white-space:nowrap;/*文本不会换行,文本会在在同一 ...
- 分布式FastDFS集群部署
FastDFS FastDFS的作者余庆在其 GitHub 上是这样描述的:"FastDFS is an open source high performance distributed f ...
- Java 异常处理的 20 个最佳实践,你知道几个?
异常处理是 Java 开发中的一个重要部分,是为了处理任何错误状况,比如资源不可访问,非法输入,空输入等等.Java 提供了几个异常处理特性,以try,catch 和 finally 关键字的形式内建 ...
- liunux中的标准输出。以及常用的 2>dev/null 命令的含义
了解Linux怎样处理输入和输出是非常重要的.一旦我们了解其原理以后,我们就可以正确熟练地使用脚本把内容输出到正确的位置.同样我们也可以更好地理解输入重定向和输出重定向. 首先我们来了解一下linux ...
- CocosCreator中_worldMatrix到底是什么(下)
Cocos Creator 中 _worldMatrix 到底是什么(下) 1. 摘要 上篇介绍了矩阵的基本知识以及对应图形变换矩阵推倒.中篇具体介介绍了对应矩阵转换成cocos creator代码的 ...
- 音视频入门-12-手动生成一张PNG图片
* 音视频入门文章目录 * 预热 上一篇 [PNG文件格式详解]详细介绍了 PNG 文件的格式. PNG 图像格式文件由一个 8 字节的 PNG 文件署名域和 3 个以上的后续数据块(IHDR.IDA ...
- Easy Poi入门
最近有一个需求,就是把excel中的内容,解析成Json对象格式的文件输出. 然后就上网找了一波资料,大神们都说用POI来做.但是我看了一下POI的解析过程,但是为了秉着高效的原则,花最少的时间去实现 ...
- Spring cloud 学习笔记
前奏 1. 什么是微服务? 微服务化的核心就是将传统的一站式应用,根据业务拆分成一个一个的服务,彻底地去耦合,==每一个微服务提供单个业务功能的服务==,一个服务做一件事,从技术角度看就是一种 ...
- (记录)Ubuntu系统中运行需要导入jar包的Java程序
在学习Redis的过程中,在学到Redis客户端Jedis的时候,考虑到能不能在ubuntu下用Vim编写Java程序并且能够运行呢? 于是,首先在网上调研了一番用Vim写Java程序的可实现性. 相 ...