Coursera在线学习---第四节.过拟合问题
一、解决过拟合问题方法
1)减少特征数量
--人为筛选
--靠模型筛选
2)正则化(Regularization)
原理:可以降低参数Θ的数量级,使一些Θ值变得非常之小。这样的目的既能保证足够的特征变量存在(虽然Θ值变小了,但是并不为0),还能减少这些特征变量对模型的影响。换言之,这些特征对于准备预测y值依然能发挥微小的贡献,这样也避免了过拟合问题。(个别Θ值过大,容易过拟合,如果Θ=0,等于缺少个别特征变量,对模型依然不好)
二、具体实例
通常我们并不知道具体使哪些Θ值变小,所以我们就让Θ1,Θ2,...,Θ100 都变小,不包括Θ0。
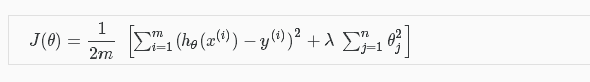
λ为正则化参数
有了正则化参数 λ就能使后面的Θ1-Θj变小了,因为如果后面的Θ值不变小,J(Θ)的值就会太大了,所以在减小J(Θ)值的过程中会逼着减小Θ的值。
λ值过大,会让Θ1-Θj的值变得非常非常小,这样就只有Θ0的值非常大,几乎变成了y=Θ0一条直线了,会造成欠拟合问题。所以,λ的值应该比较合理才行。另外,正则化参数过多也会出现该问题,可以适时减少参与正则化的参数,例如从Θ2-Θj开始参与正则化等等。
备注:如果模型在训练样本上就表现不好,说明模型欠拟合,需要增加更多的特征变量,可以引入多项式回归(Θ0+Θ1*X+Θ2*X^2+Θ3*X^3),多项式回归方程能让曲线更加弯曲以适应训练样本。这样能更好的拟合训练样本,或者减少正则化参数(例如:从Θ2开始正则化)
Coursera在线学习---第四节.过拟合问题的更多相关文章
- Coursera在线学习---第十节.大规模机器学习(Large Scale Machine Learning)
一.如何学习大规模数据集? 在训练样本集很大的情况下,我们可以先取一小部分样本学习模型,比如m=1000,然后画出对应的学习曲线.如果根据学习曲线发现模型属于高偏差,则应在现有样本上继续调整模型,具体 ...
- Coursera在线学习---第六节.构建机器学习系统
备: High bias(高偏差) 模型会欠拟合 High variance(高方差) 模型会过拟合 正则化参数λ过大造成高偏差,λ过小造成高方差 一.利用训练好的模型做数据预测时,如果效果不好 ...
- Coursera在线学习---第七节.支持向量机(SVM)
一.代价函数 对比逻辑回归与支持向量机代价函数. cost1(z)=-log(1/(1+e-z)) cost0(z)=-log(1-1/(1+e-z)) 二.支持向量机中求解代价函数中的C值相当于 ...
- Coursera在线学习---第五节.Logistic Regression
一.假设函数与决策边界 二.求解代价函数 这样推导后最后发现,逻辑回归参数更新公式跟线性回归参数更新方式一摸一样. 为什么线性回归采用最小二乘法作为求解代价函数,而逻辑回归却用极大似然估计求解? 解答 ...
- 大白话5分钟带你走进人工智能-第十四节过拟合解决手段L1和L2正则
第十四节过拟合解决手段L1和L2正则 第十三节中, ...
- Coursera在线学习---第九节(1).异常数据检测(Anomaly Detection)
一.如何构建Anomaly Detection模型? 二.如何评估Anomaly Detection系统? 1)将样本分为6:2:2比例 2)利用交叉验证集计算出F1值,可以用F1值选取概率阈值ξ,选 ...
- VUE2.0实现购物车和地址选配功能学习第四节
第四节 v-on实现金额动态计算 用¥金额 进行格式处理,可以使用原生js进行转换,但是在vuei,使用filter过滤器更加方便 注: 1.es6语法=>和import等 好处在于res参数后 ...
- Coursera在线学习---第九节(2).推荐系统
一.基于内容的推荐系统(Content Based Recommendations) 所谓基于内容的推荐,就是知道待推荐产品的一些特征情况,将产品的这些特征作为特征变量构建模型来预测.比如,下面的电影 ...
- Coursera在线学习---第一节.梯度下降法与正规方程法求解模型参数比较
一.梯度下降法 优点:即使特征变量的维度n很大,该方法依然很有效 缺点:1)需要选择学习速率α 2)需要多次迭代 二.正规方程法(Normal Equation) 该方法可以一次性求解参数Θ 优点:1 ...
随机推荐
- 【Python】Python处理csv文件
Python处理csv文件 CSV(Comma-Separated Values)即逗号分隔值,可以用Excel打开查看.由于是纯文本,任何编辑器也都可打开.与Excel文件不同,CSV文件中: 值没 ...
- 【bzoj4311】向量 线段树对时间分治+STL-vector维护凸包
题目描述 你要维护一个向量集合,支持以下操作: 1.插入一个向量(x,y) 2.删除插入的第i个向量 3.查询当前集合与(x,y)点积的最大值是多少.如果当前是空集输出0 输入 第一行输入一个整数n, ...
- WEB测试基础
一.输入框1.字符型输入框:(1)字符型输入框:英文全角.英文半角.数字.空或者空格.特殊字符“~!@#¥%……&*?[]{}”特别要注意单引号和&符号.禁止直接输入特殊字符时,使用“ ...
- 【纪念】NOIP2018后记——也许是一个新的起点
如果你为了失去太阳而哭泣,那么你也将失去星星和月亮. —— 泰戈尔<飞鸟集> NOIP结束了,我挂了一道题……曾经在心中觉得怎么都不会考到的分数,就这么冷冷的出现在了我的成绩单上.的确是比 ...
- THUSC2018滚粗记
THUSC2018滚粗记 前言 大家好,我是\(yyb\),我的博客里又多了一篇滚粗记, 我记得我原来在某篇滚粗记中曾经写过 \(yyb\)还会写很多很多次滚粗记才会有一篇不是滚粗记的东西. 看起来这 ...
- 【BZOJ4152】The Captain(最短路)
[BZOJ4152]The Captain(最短路) 题面 BZOJ Description 给定平面上的n个点,定义(x1,y1)到(x2,y2)的费用为min(|x1-x2|,|y1-y2|),求 ...
- 使图片相对于上层DIV始终水平、垂直都居中
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- ping: unknown host 解决办法
如果ping命令返回如下错误,那主要的可能性就是系统的DNS设置有误. [root@CentOS5 ~]# ping www.sina.com.cn ping: unknown host www.si ...
- Contest Record
Contest 1135 at HZOI Problem A: 优美的棋发现一个可以证明的规律就是了……忘记给<<运算的左边变量转化为long long类型了,结果挂了20分……以后一定记 ...
- pycrypto 安装
https://www.dlitz.net/software/pycrypto/ 下载pycrypto-2.6.1.tar.gz,解压后 python setup.py build python se ...