第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
1、分布式爬虫原理
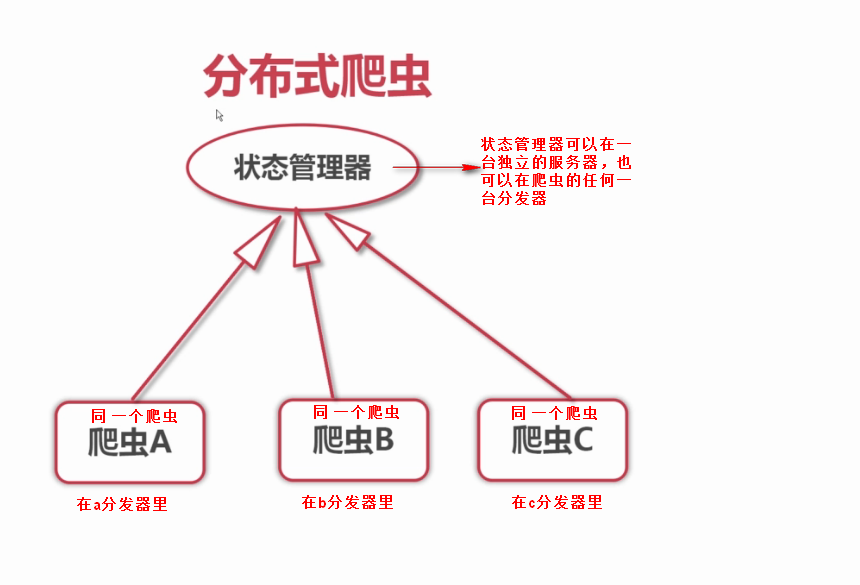
2、分布式爬虫优点

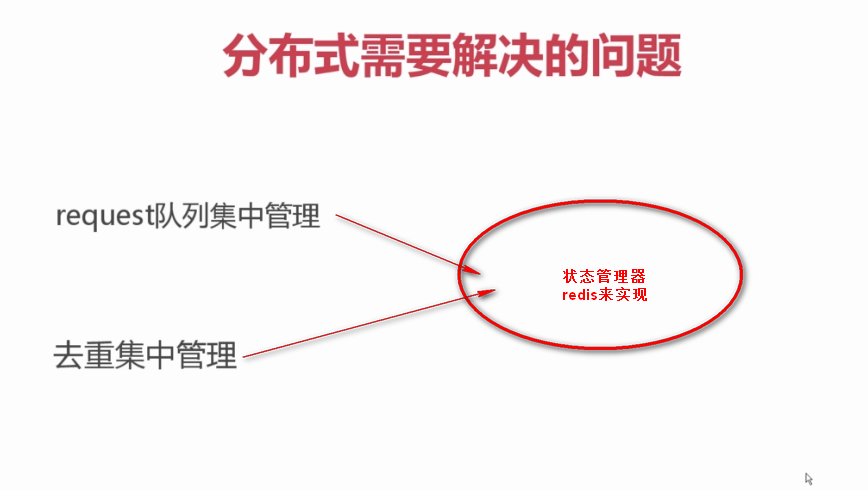
3、分布式爬虫需要解决的问题
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点的更多相关文章
- 第三百八十六节,Django+Xadmin打造上线标准的在线教育平台—HTML母版继承
第三百八十六节,Django+Xadmin打造上线标准的在线教育平台—HTML母版继承 母板-子板-母板继承 母板继承就是访问的页面继承一个母板,将访问页面的内容引入到母板里指定的地方,组合成一个新页 ...
- 第三百七十六节,Django+Xadmin打造上线标准的在线教育平台—创建用户操作app,在models.py文件生成5张表,用户咨询表、课程评论表、用户收藏表、用户消息表、用户学习表
第三百七十六节,Django+Xadmin打造上线标准的在线教育平台—创建用户操作app,在models.py文件生成5张表,用户咨询表.课程评论表.用户收藏表.用户消息表.用户学习表 创建名称为ap ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection)
第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection) Scrapy提供了方便的收集数据的机制.数据以key/value方式存储,值大多是计数 ...
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中,判断URL是否重复 布隆过滤器(Bloom Filter)详 ...
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启 scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的UR ...
- 第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url 一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 ...
- 第三百八十四节,Django+Xadmin打造上线标准的在线教育平台—路由映射与静态文件配置以及会员注册
第三百八十四节,Django+Xadmin打造上线标准的在线教育平台—路由映射与静态文件配置以及会员注册 基于类的路由映射 from django.conf.urls import url, incl ...
- 第三百七十九节,Django+Xadmin打造上线标准的在线教育平台—xadmin的安装
第三百七十九节,Django+Xadmin打造上线标准的在线教育平台—xadmin的安装 xadmin介绍 xadmin是基于Django的admin开发的更完善的后台管理系统,页面基于Bootstr ...
随机推荐
- js模板引擎art-template使用方法
art-template是款性能卓越的 js 模板引擎 https://aui.github.io/art-template/ 特性 拥有接近 JavaScript 渲染极限的的性能 调试友好:语法. ...
- Vue之vuex实现简易计算器
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 【转】解决Lost connection to MySQL server during query错误方法
初步判断是MySQL可能挂掉了,在系统服务里面查看MySQL的进程并没有停止. 最开始考虑是数据库结构不对,但是我是通过Navicat for MySQL的备份和恢复备份导入数据,应该表结构都在备份文 ...
- Python(三)之Python的表达式和语句概述
Python常用的表达式操作符: 算术运算符: x+y, x-y, x / y, x*y, x // y, x%y 比较运算符: x>y, x<y, x>=y, x<=y, x ...
- 移动web开发(一)——移动web开发必备知识
参考: 移动终端开发必备知识.http://isux.tencent.com/mobile-development-essential-knowledge.html
- ARKit从入门到精通(9)-ARKit让飞机跟着镜头飞起来
1.1-ARKit物体跟随相机移动流程介绍 1.2-完整代码 1.3-代码下载地址 废话不多说,先看效果 1001.gif 1.1-ARKit物体跟随相机移动流程介绍 1.点击屏幕添加物体,已经在第三 ...
- DeepNLP的核心关键/NLP词的表示方法类型/NLP语言模型 /词的分布式表示/word embedding/word2vec
DeepNLP的核心关键/NLP语言模型 /word embedding/word2vec Indexing: 〇.序 一.DeepNLP的核心关键:语言表示(Representation) 二.NL ...
- [转]详解Oracle高级分组函数(ROLLUP, CUBE, GROUPING SETS)
原文地址:http://blog.csdn.net/u014558001/article/details/42387929 本文主要讲解 ROLLUP, CUBE, GROUPING SETS的主要用 ...
- mysqldump具体应用实例
1.导出整个数据库 mysqldump -h主机 -u 用户名 -p 数据库名 > 导出的文件名 mysqldump -h127.0.0.1 -u wcnc -p smgp_apps ...
- 【Android Studio】DDMS的模拟器控制(Emulator Control)不可用
问题:Win10,Android Studio2.1.3中,创建了一个安卓手机模拟器,但是在DDMS中模拟器控制(Emulator Control)是灰色不可用的(比如想模拟来电和来短信).如下图: ...