吴裕雄 python 数据处理(2)
import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(data.head())
a = data.stack()
print(a)
b = a.unstack()
print(b)

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(data.head())
df = data.set_index("日期")
print(df.head())

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
print(a.info())

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
print(data.head())

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = data["价格"].groupby([data["出发地"],data["目的地"]]).mean()
print(a)

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_route_cnt.csv")
print(data.head())

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
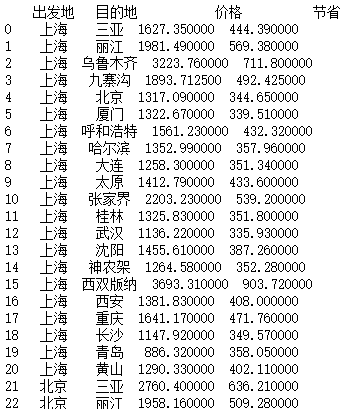
a = data.groupby([data["出发地"],data["目的地"]],as_index=False).mean()
print(a)
import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_route_cnt.csv")
print(data.head())
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
print(data_1.head())
a = data_1.groupby([data_1["出发地"],data_1["目的地"]],as_index=False).mean()
print(a.head())
b = pd.merge(a,data)
print(b.head())

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = pd.pivot_table(data_1,values=["价格"],index=["出发地"],columns=["目的地"])
print(a.head())

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = pd.pivot_table(data_1[data_1["出发地"]=="杭州"],values=["价格"],index=["出发地","目的地"],columns=["去程方式"])
print(a)

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(data_1.head())
print(data_1.isnull().head())
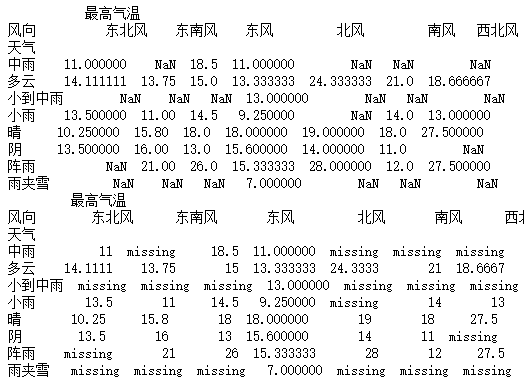
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
print(a.isnull())

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.dropna(axis=0)
print(b)

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.dropna(axis=1)
print(b)

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
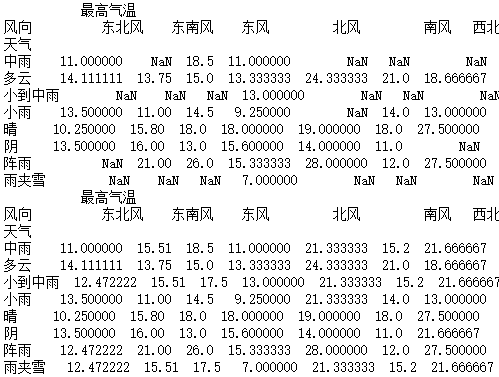
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna("missing")
print(b)
import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna(method="pad")
print(b)

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna(method="bfill",limit=1)
print(b)

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna(a.mean())
print(b)
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(np.shape(df))
print(df.head())
fig,ax = plt.subplots(1,1,figsize=(8,5))
ax.hist(df["最低气温"],bins=20)
plt.show()
d = df["最低气温"]
zscore = (d-d.mean())/d.std()
df["isOutlier"]=zscore.abs()>3
print(df.head())
a = df["isOutlier"].value_counts()
print(a)


%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\sale_data.csv")
print(np.shape(df))
print(df.head())
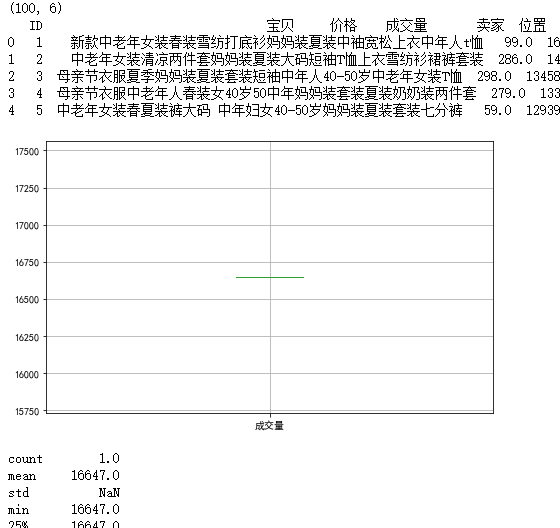
a = df[df["卖家"]=="夏奈凤凰旗舰店"]
fig,ax = plt.subplots(1,1,figsize=(8,5))
a.boxplot(column="成交量",ax=ax)
plt.show()
b = a["成交量"]
print(b.describe())
a["isOutlier"]=d>d.quantile(0.75)
c = a[a["isOutlier"]==True]
print(c)
import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(np.shape(df))
print(df.head())
a = df.duplicated()
print(np.shape(a))
print(a[:5])

import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(np.shape(df))
a = df.set_index("日期")
print(a.head())
b = a.duplicated()
print(b[:5])
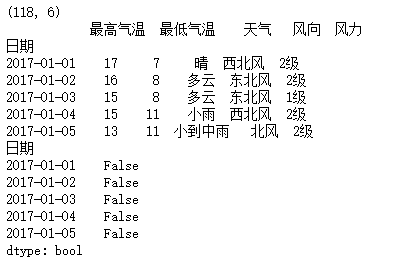
import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(np.shape(df))
a = df.set_index("日期")
print(a.head())
b = a.duplicated("最高气温")
print(b[:5])

import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(type(df))
print(np.shape(df))
a = df.set_index("日期")
print(a.head())
b = a.drop_duplicates("最高气温")
print(np.shape(b))
print(b.head())

import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
print(df.head())
print(df.info())

import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = df.duplicated().value_counts()
print(a)
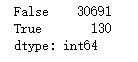
import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = df.drop_duplicates()
b = a.duplicated().value_counts()
print(b)

import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = df.drop_duplicates()
print(a.describe())

%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
print(np.shape(df))
fig,axes = plt.subplots(1,2,figsize=(12,5))
axes[0].hist(df["价格"],bins=20)
df.boxplot(column="价格",ax=axes[1])
plt.show()

%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
d = df["价格"]
zscore = (d-d.mean())/d.std()
print(zscore[0:3])
df["isOutlier"]=zscore.abs()>3.5
print(df["isOutlier"].value_counts())
a = df[df["isOutlier"]==True]
print(a.head())

吴裕雄 python 数据处理(2)的更多相关文章
- 吴裕雄 python 数据处理(3)
import time a = time.time()print(a)b = time.localtime()print(b)c = time.strftime("%Y-%m-%d %X&q ...
- 吴裕雄 python 数据处理(1)
import time print(time.time())print(time.localtime())print(time.strftime('%Y-%m-%d %X',time.localtim ...
- 吴裕雄 python 神经网络——TensorFlow 输入数据处理框架
import tensorflow as tf files = tf.train.match_filenames_once("E:\\MNIST_data\\output.tfrecords ...
- 吴裕雄 python神经网络 花朵图片识别(10)
import osimport numpy as npimport matplotlib.pyplot as pltfrom PIL import Image, ImageChopsfrom skim ...
- 吴裕雄 python神经网络 花朵图片识别(9)
import osimport numpy as npimport matplotlib.pyplot as pltfrom PIL import Image, ImageChopsfrom skim ...
- 吴裕雄 python 神经网络——TensorFlow pb文件保存方法
import tensorflow as tf from tensorflow.python.framework import graph_util v1 = tf.Variable(tf.const ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(4)
# -*- coding: utf-8 -*- import glob import os.path import numpy as np import tensorflow as tf from t ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(3)
import glob import os.path import numpy as np import tensorflow as tf from tensorflow.python.platfor ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(2)
import glob import os.path import numpy as np import tensorflow as tf from tensorflow.python.platfor ...
随机推荐
- Server对象,HttpServerUtility类,获取服务器信息
在Asp.net WebForm中,Server对象是HttpServerUtility类的实例.看下图: 而在Asp.net MVC中,Server对象是HttpServerUtilityBase对 ...
- hanlp中文自然语言处理的几种分词方法
自然语言处理在大数据以及近年来大火的人工智能方面都有着非同寻常的意义.那么,什么是自然语言处理呢?在没有接触到大数据这方面的时候,也只是以前在学习计算机方面知识时听说过自然语言处理.书本上对于自然语言 ...
- 【python】class之super关键字的作用
在Python类的方法(method)中,要调用父类的某个方法,在Python 2.2以前,通常的写法如代码段1: 代码段1: class A: def __init__(self): prin ...
- 【unittest】unittest单元模块做assert
我在Windows上开发Python用的版本是2.7,在Ubuntu上开发的版本是2.6,而在Python的unittest模块中,有几个方法是在2.7才有的,它们是: Method Checks t ...
- .Net和SqlServer的事务处理实例
1,SqlServer存储过程的事务处理一种比较通用的出错处理的模式大概如下:Create procdure prInsertProducts( @intProductId int, @chvProd ...
- PHP中imagecopyresampled参数详解
原文链接http://blog.csdn.net/ajaxchen_615/article/details/5941181 做php缩微图程序,用到了imagecopyresampled函数,在网上找 ...
- vmware12共享windows的文件给虚拟的linux
1:首先我的vmware的版本是12的 点击vmware的虚拟机---------------------->设置------------------------>选项---------- ...
- 自己写的jQuery颜色插件
界面效果: 插件js代码: ;(function ($) { //122种颜色 var aColors = [ "ff0000", "ffff00", &quo ...
- LayUI——数据表格使用
Layui数据表格的实际项目使用 Layui的数据表格可谓是在后台管理的页面中经常用到的工具了 最近做项目就用到了,项目的要求是用数据表格显示出后台文章的列表并且每一行的文章都有对应的修改删除操作按钮 ...
- C++并发编程 02 数据共享
在<C++并发编程实战>这本书中第3章主要将的是多线程之间的数据共享同步问题.在多线程之间需要进行数据同步的主要是条件竞争. 1 std::lock_guard<std::mute ...