Gradient Descent with Momentum and Nesterov Momentum
在Batch Gradient Descent及Mini-batch Gradient Descent, Stochastic Gradient Descent(SGD)算法中,每一步优化相对于之前的操作,都是独立的。每一次迭代开始,算法都要根据更新后的Cost Function来计算梯度,并用该梯度来做Gradient Descent。
Momentum以及Nestrov Momentum相较于前三种算法,虽然也会根据Cost Function来计算当前的梯度,但是却不直接用此梯度去做Gradient Descent。而是赋予当前梯度一个权值,并综合考虑之前N次优化的梯度(使其形成一个动量、或类比为惯性),得到一个加权平均的移动平均值(Weighted Moving Average),之后再来作Gradient Descent。
Gradient Descent with Momentum:
首先,我们需要计算Momentum,即动量。这里使用Exponential Moving Average(EMA)来计算该加权平均值,公式为:
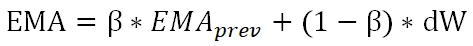
dW为本次计算出的梯度值,β是衰减因子,取值在0-1之间。为了直观的理解指数衰减权值,将上式展开,可以得到:
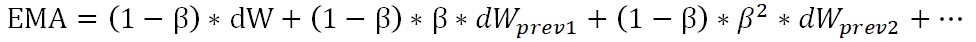
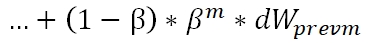
通过上式,我们可以知道,梯度序列的权重是随着β进行指数衰减的。根据β值的大小,可以得出大致纳入考虑范围的步数为1/(1-β),β值越大,衰减满、纳入考虑的步数约多,反之则窗口约窄。
Momentum算法会减小算法的震荡,在实现上也非常有效率,比起Simple Moving Average,EMA所用的存储空间小,并且每次迭代中使用一行代码即可实现。不过,β成为了除α外的又一个Hyperparameter,调参要更难了。
Nesterov Momentum:
如下图左侧所示,Gradient Descent with Momentum实际上是两个分向量的加和。一个分量是包含“惯性”的momentum,另一个分量是当前梯度,二者合并后产生出实际的update梯度。下图右侧,是Nesterov Momentum算法的示意图。其思路是:明知道momentum分量是需要的,不如先将这部分更新了。
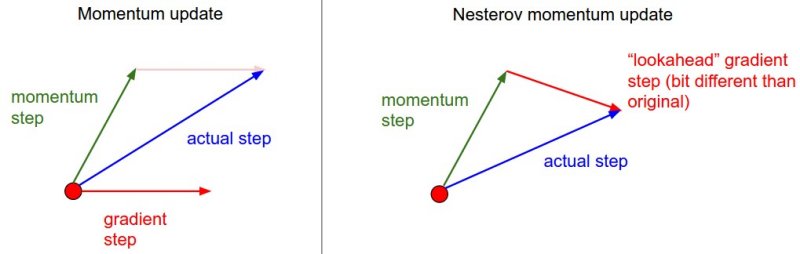
在下图中,Nesterov算法不在红点处计算梯度,而是先更新绿色箭头,并且在绿色箭头处计算梯度,再做更新。两个算法会得出不一样的结果。
Gradient Descent with Momentum and Nesterov Momentum的更多相关文章
- 深度学习(九) 深度学习最全优化方法总结比较(SGD,Momentum,Nesterov Momentum,Adagrad,Adadelta,RMSprop,Adam)
前言 这里讨论的优化问题指的是,给定目标函数f(x),我们需要找到一组参数x(权重),使得f(x)的值最小. 本文以下内容假设读者已经了解机器学习基本知识,和梯度下降的原理. SGD SGD指stoc ...
- (转) An overview of gradient descent optimization algorithms
An overview of gradient descent optimization algorithms Table of contents: Gradient descent variants ...
- An overview of gradient descent optimization algorithms
原文地址:An overview of gradient descent optimization algorithms An overview of gradient descent optimiz ...
- <反向传播(backprop)>梯度下降法gradient descent的发展历史与各版本
梯度下降法作为一种反向传播算法最早在上世纪由geoffrey hinton等人提出并被广泛接受.最早GD由很多研究团队各自发表,可他们大多无人问津,而hinton做的研究完整表述了GD方法,同时hin ...
- FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MINI-BATCH LEARNING. WHAT IS THE DIFFERENCE?
FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MIN ...
- (转)Introduction to Gradient Descent Algorithm (along with variants) in Machine Learning
Introduction Optimization is always the ultimate goal whether you are dealing with a real life probl ...
- Adaptive gradient descent without descent
目录 概 主要内容 算法1 AdGD 定理1 ADGD-L 算法2 定理2 算法3 ADGD-accel 算法4 Adaptive SGD 定理4 代码 Malitsky Y, Mishchenko ...
- 梯度下降(Gradient Descent)小结
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
- 机器学习基础——梯度下降法(Gradient Descent)
机器学习基础--梯度下降法(Gradient Descent) 看了coursea的机器学习课,知道了梯度下降法.一开始只是对其做了下简单的了解.随着内容的深入,发现梯度下降法在很多算法中都用的到,除 ...
随机推荐
- 持续集成工具——Jenkins
一.jenkins简介 1.持续集成工具 2.基于JAVA环境 二.环境搭建 1.安装JDK 2.安装配置git 3.安装配置tomcat Tomcat是针对Java的一个开源中间件服务器(容器),基 ...
- TP5.1+Vue前后端分离实践
配置: 主域名 www.demo.xyz 二级子域名 api.demo.xyz 列表项目其中api.demo.xyz加入了版本控制,使用的是URL路由传入方式 在route.php路由文件中配置,如下 ...
- app防攻击办法
方法一 要求请求端带上一个随机字符串state(也可以是特定规则生成的,甚至是从服务器上请求过来的),服务端(用过滤/拦截器之类的实现不会影响业务代码)收到之后缓存一定的时间(长短视业务和硬件),每次 ...
- spark复习笔记(3):使用spark实现单词统计
wordcount是spark入门级的demo,不难但是很有趣.接下来我用命令行.scala.Java和python这三种语言来实现单词统计. 一.使用命令行实现单词的统计 1.首先touch一个a. ...
- Git:将本地项目连接到远程(github、gitee、gitlab)仓库流程
当进行协同开发或者为了代码安全备份需要,一般都会将本地代码和远程仓库相连接. 备注:Github.Gitee.Gitlab是三个常用的远程git仓库,操作流程基本一致. 提前环境要求: 1.node. ...
- openstack stein部署手册 10. 创建实例
# 建立网络(provider)与子网 openstack network create --share --external --provider-physical-network provider ...
- 详解webpack4打包--新手入门(填坑)
注意,这个dev和build好像在哪儿见过??对了, 刚刚才在package.json里配置的“scripts”这一项的值就有“dev”和“build”.对,一点都不错,就是这2个值,这2个值代表的是 ...
- leetcode x进制数 python3
不少题目都是实现吧10进制数转换成x进制数,实际上都是一个套路,下面是7进制的,想换成什么进制,把7替换成相应数字即可,输出的是字符串 16,32进制这种有特殊要求的转不了,其他的应该通用 class ...
- [apache] apache配置文件中的deny和allow
allow 和Deny可以用于apache的conf文件或者.htaccess文件中(配合Directory, Location, Files等),用来控制目录和文件的访问授权. 例如: <Di ...
- DataFrame.loc的区间
df.loc[dates[0:1],'E']和df.loc[dates[0]:dates[1],'E']不同. 前者不包含dates[1],后者是包含dates[1]的. 根据Python3中实际代码 ...