大数据-HBase HA集群搭建
1、下载对应版本的Hbase,在我们搭建的集群环境中选用的是hbase-1.4.6
将下载完成的hbase压缩包放到对应的目录下,此处我们的目录为/opt/workspace/
2、对已经有的压缩包进行解压缩
[root@master1 workspace]#tar -zxvf hbase-1.4.-bin.tar.gz
3、为了方便可以将文件重命名,此处我们不需要重命名
4、修改配置文件、/etc/profile,添加下面代码
# HBase Config
export HBASE_HOME=/opt/workspace/hbase-1.4.
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:${HIVE_HOME}/bin:${SPARK_HOME}/bin:${HBASE_HOME}/bin:${ZK_HOME}/bin:$PATH
[root@master1 workspace]# source /etc/profile
5、修改配置文件hbase-env.sh,在文件中添加如下,其中HBASE_MANAGES_ZK=false 是不启用HBase自带的Zookeeper集群。
export JAVA_HOME=/opt/workspace/jdk1.
export HADOOP_HOME=/opt/workspace/hadoop-2.9.
export HBASE_HOME=/opt/workspace/hbase-1.4.
export HBASE_CLASSPATH=$HADOOP_HOME/etc/hadoop
export HBASE_PID_DIR=/root/hbase/pids
export HBASE_MANAGES_ZK=false
export HBASE_LOG_DIR=${HBASE_HOME}/logs
6、修改配置文件hbase-site.xml,配置如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/**
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
-->
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop-test/hbase</value>
<description>The directory shared byregion servers.</description>
</property>
<!--port of hbase-->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value></value>
</property>
<!--timeout time-->
<property>
<name>zookeeper.session.timeout</name>
<value></value>
</property>
<!--pretend errors caused by time don't synchronize in servers-->
<property>
<name>hbase.master.maxclockskew</name>
<value></value>
</property>
<!--cluser host-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>master1,master2,slave1,slave2,slave3</value>
</property>
<!--path of tmp-->
<property>
<name>hbase.tmp.dir</name>
<value>/opt/hbase_tmp/tmp</value>
</property>
<!-- true means of distributed-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--master-->
<property>
<name>hbase.master</name>
<value></value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/workspace/zookeeper/data</value>
</property>
<property>
<name>hbase.regionserver.restart.on.zk.expire</name>
<value>true</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value></value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
</configuration>
其中hbase.rootdir配置的是hdfs地,用来持久化Hbase,ip:port要和hadoop/core-site.xml中的fs.defaultFS保持一致。hbase.cluster.distributed :Hbase的运行模式。false是单机模式,true是分布式模式
7、修改regionservers,指定hbase的主从
slave1
slave2
slave3
8、将该环境配置发送到其余4台服务器
9、启动hbase集群
[root@master1 hbase-1.4.]# cd bin
[root@master1 bin]# start-hbase.sh
报错如下:

解决:
在hbase-env.sh文件中添加
export HBASE_SSH_OPTS="-p 61333"
重新启动,成功。
[root@master1 hbase-1.4.]# cd bin
[root@master1 bin]# start-hbase.sh
master1节点进程如下:

slave1、slave2、slave3节点进程如下:

10、启动备用节点的HMaster
[root@master2 hbase-1.4.]# cd bin
[root@master2 bin]# hbase-daemon.sh start master
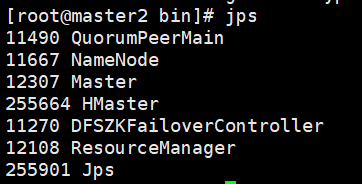
启动成功,进程如下:
大数据-HBase HA集群搭建的更多相关文章
- 大数据-hadoop HA集群搭建
一.安装hadoop.HA及配置journalnode 实现namenode HA 实现resourcemanager HA namenode节点之间通过journalnode同步元数据 首先下载需要 ...
- 大数据-spark HA集群搭建
一.安装scala 我们安装的是scala-2.11.8 5台机器全部安装 下载需要的安装包,放到特定的目录下/opt/workspace/并进行解压 1.解压缩 [root@master1 ~]# ...
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据中Hadoop集群搭建与配置
前提环境是之前搭建的4台Linux虚拟机,详情参见 Linux集群搭建 该环境对应4台服务器,192.168.1.60.61.62.63,其中60为主机,其余为从机 软件版本选择: Java:JDK1 ...
- 大数据平台Hadoop集群搭建
一.概念 Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce.HDFS是一个分布式文件系统,类似mogilef ...
- 大数据:spark集群搭建
创建spark用户组,组ID1000 groupadd -g 1000 spark 在spark用户组下创建用户ID 2000的spark用户 获取视频中文档资料及完整视频的伙伴请加QQ群:9479 ...
- 大数据学习——Storm集群搭建
安装storm之前要安装zookeeper 一.安装storm步骤 1.下载安装包 2.解压安装包 .tar.gz storm 3.修改配置文件 mv /root/apps/storm/conf/st ...
- 大数据中Linux集群搭建与配置
因测试需要,一共安装4台linux系统,在windows上用vm搭建. 对应4个IP为192.168.1.60.61.62.63,这里记录其中一台的搭建过程,其余的可以直接复制虚拟机,并修改相关配置即 ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
随机推荐
- boost之date_time库
最近开了boost库的学习,就先从日期时间库开始吧,boost的date_time库是一个很强大的时间库,用起来还是挺方便的.以下算是我学习的笔记,我把它记录下来,以后便于我复习和查阅. #inclu ...
- Mosquitto服务器的搭建以及SSL/TLS安全通信配置
Mosquitto服务器的搭建以及SSL/TLS安全通信配置 摘自:https://segmentfault.com/a/1190000005079300 openhab raspberry-pi ...
- Java程序设计17——多线程-Part-B
5 改变线程优先级 每个线程执行都具有一定的优先级,优先级高的线程获得较多的执行机会,而优先级低的线程则获得较少的执行机会. 每个线程默认的优先级都与创建它的父线程具有相同的优先级,在默认情况下,ma ...
- Oracle学习笔记(十)
光标(游标)概念引入 就是一个结果集(查询或者其他操作返回的结果是多个时使用)定义一个光标 cursor c1 is select ename from emp: 从光标中取值 打开光标: --ope ...
- 团体程序设计天梯赛L2-001 紧急救援 2017-03-22 17:25 93人阅读 评论(0) 收藏
L2-001. 紧急救援 时间限制 200 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 陈越 作为一个城市的应急救援队伍的负责人,你有一张特殊的全国 ...
- EventBus事件总线框架(发布者/订阅者模式,观察者模式)
一. android应用内消息传递的方式: 1. handler方式-----------------不同线程间传递消息. 2. Interface接口回调方式-------任意两个对象. 3. In ...
- 常用脚本--SQL Server获取OS日志
--=================================================== --SQL Server获取OS日志: ), ), ), ) select @start_d ...
- 打造一个简单实用的的TXT文本操作及日志框架
首先先介绍一下这个项目,该项目实现了文本写入及读取,日志写入指定文件夹或默认文件夹,日志数量控制,单个日志大小控制,通过约定的参数让用户可以用更少的代码解决问题. 1.读取文本文件方法 使用:JIYU ...
- Katalon Studio简单使用(一)
官网地址:https://www.katalon.com/ katalon 目前有两种产品 一个是studio 另外一个是katalon analytics,此处先来学习studio部分. 文章学习内 ...
- .Net Core MVC初学习
.net core已经出来很长一段时间了,没有很好的学习过,现在工作不那么忙了,参考官方文档,在这里记录自己的学习过程! ASP.NET Core 是一个跨平台的高性能开源框架,用于生成基于云且连接 ...