python爬虫:爬取猫眼TOP100榜的100部高分经典电影
1、问题描述:
爬取猫眼TOP100榜的100部高分经典电影,并将数据存储到CSV文件中
2、思路分析:
(1)目标网址:http://maoyan.com/board/4
(2)代码结构:

(3) init(self)初始化函数
· hearders用到了fake_useragent库,用来随机生成请求头。
· datas空列表,用于保存爬取的数据。
def __init__(self,url):
self.headers = {"User-Agent": UserAgent().random}
self.url = url
self.datas = list()
(4) getPage()函数
猫眼Top100榜总共有10页电影,每页的链接基本一样,只有最后一个数字在变化http://maoyan.com/board/4?offset=10,所以可以通过for循环来访问10页的电影。
# 通过for循环,获取10页的电影信息的源码
def getPage(self):
for i in range(0,10):
url = self.url + "?offset={0}".format(i*10)
response = requests.get(url, headers = self.headers)
if response.status_code == 200:
self.parsePage(response.text)
else:
return None
(5)parsePage()函数
每页都有10部高分经典电影,通过BeautifulSoup获取每页10部电影的详细信息:名字、主演、上映时间、评分。
# 通过BeautifulSoup获取每页10部电影的详细信息
def parsePage(self, html):
soup = BeautifulSoup(html, "html.parser")
details = soup.find_all("dd")
for dd in details:
data = {}
data["index"] = dd.find("i").text
data["name"] = dd.find("p", class_ = "name").text
data["star"] = dd.find("p", class_="star").text.strip()[3:]
data["time"] = dd.find("p", class_="releasetime").text.strip()[5:]
data["score"] = dd.find("p", class_="score").text
self.datas.append(data)
(6)savaData()函数
通过DataFrame(),把Top100的电影存储到CSV文件中。
它默认的是按照列名的字典顺序排序的。想要自定义列的顺序,可以加columns字段
# 通过DataFrame,把Top100的电影存储到CSV文件中
def saveData(self):
self.getPage()
data = pd.DataFrame(self.datas)
columns = ["index", "name", "star", "time", "score"]
data.to_csv(".\maoyanTop100.csv", index=False, columns=columns)
3、效果展示
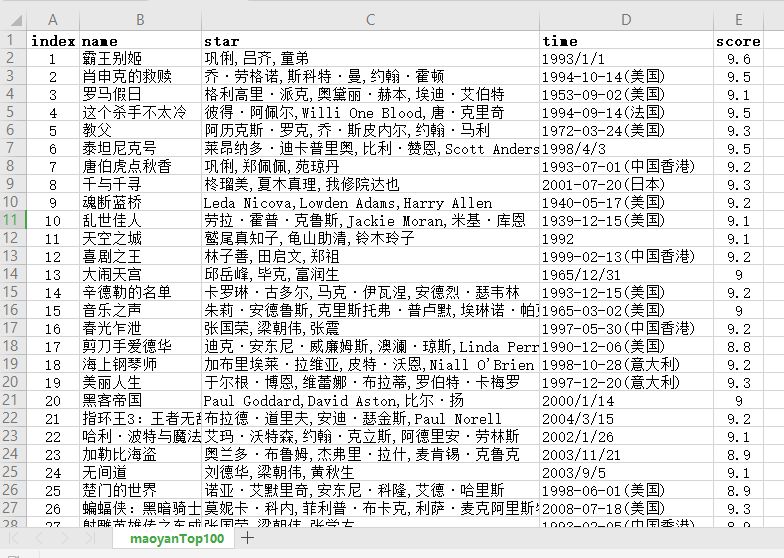
4、完整代码:
# -* conding: utf-8 *-
#author: wangshx6
#data: 2018-11-08
#description: 爬取猫眼TOP100榜的100部高分经典电影
import requests
from bs4 import BeautifulSoup
import pandas as pd
from fake_useragent import UserAgent
class MaoyanSpider(object):
def __init__(self,url):
self.headers = {"User-Agent": UserAgent().random}
self.url = url
self.datas = list()
# 通过for循环,获取10页的电影信息的源码
def getPage(self):
for i in range(0,10):
url = self.url + "?offset={0}".format(i*10)
response = requests.get(url, headers = self.headers)
if response.status_code == 200:
self.parsePage(response.text)
else:
return None
# 通过BeautifulSoup获取每页10部电影的详细信息
def parsePage(self, html):
soup = BeautifulSoup(html, "html.parser")
details = soup.find_all("dd")
for dd in details:
data = {}
data["index"] = dd.find("i").text
data["name"] = dd.find("p", class_ = "name").text
data["star"] = dd.find("p", class_="star").text.strip()[3:]
data["time"] = dd.find("p", class_="releasetime").text.strip()[5:]
data["score"] = dd.find("p", class_="score").text
self.datas.append(data)
# 通过DataFrame,把Top100的电影存储到CSV文件中
def saveData(self):
self.getPage()
data = pd.DataFrame(self.datas)
columns = ["index", "name", "star", "time", "score"]
data.to_csv(".\maoyanTop100.csv", index=False, columns=columns)
if __name__ == "__main__":
url = "http://maoyan.com/board/4"
spider = MaoyanSpider(url)
spider.saveData()
python爬虫:爬取猫眼TOP100榜的100部高分经典电影的更多相关文章
- 【爬虫】-爬取猫眼TOP100
原文崔庆才<python3网络爬虫实战> 本文为自学记录,如有侵权,请联系删除 目标: 熟悉正则表达式,以及爬虫流程 获取猫眼TOP100榜单 1.网站分析 目标站点为http://www ...
- Python 爬取 猫眼 top100 电影例子
一个Python 爬取猫眼top100的小栗子 import json import requests import re from multiprocessing import Pool #//进程 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
随机推荐
- c# cook book -Linq 关于Object的比较
实际项目中经常用到 Union,Distinct,INtersect,Execpt对列表进行处理 一般来说要首先重写 Equals 和GetHashCode方法 首先看为重写的情况: namespac ...
- Hibernate课程 初探多对多映射1-1 多对多应用场景
1 用途: 员工和项目之间的多对多关系 2 实现: 员工表和项目表之外,建立员工和项目关联表来实现: 3 hibernate应用: set元素和many-to-many来实现
- spring boot Configuration Annotation Proessor not found in classpath
出现spring boot Configuration Annotation Proessor not found in classpath的提示是在用了@ConfigurationPropertie ...
- springmvc+spring+mybatis+sqlserver----插入一条新数据
<insert id="addOneMsg" parameterType="java.util.Map"> INSERT INTO PDA_JWL_ ...
- SpringCloud的学习记录(7)
这一章节讲zuul的使用. 在我们生成的Demo项目上右键点击New->Module->spring Initializr, 然后next, 填写Group和Artifact等信息, 这里 ...
- Linux读取NTFS类型数据盘
Windows的文件系统通常使用NTFS或者FAT32格式,而Linux的文件系统格式通常是EXT系列,请参考下面方法: 1) 在Linux系统上使用以下命令安装ntfsprogs软件使得Linux能 ...
- [转]Windows 下常用盗版软件的替代免费软件列表
当您看完这篇文章,我相信您完全可以把您 Windows 系统里安装的盗版软件清理干净而不影响您的任何工作.如果您仍然希望并且喜欢.享受做一个盗版软件用户的话,那也没有办法,但是请您记住,非常非常重要的 ...
- Spark master节点HA配置
Spark master节点HA配置 1.介绍 Spark HA配置需要借助于Zookeeper实现,因此需要先搭建ZooKeeper集群. 2.配置 2.1 修改所有节点的spark-evn.sh文 ...
- Object-C 语法 字符串 数组 字典 和常用函数 学习笔记
字符串 //取子字符串 NSString *str1=@"今天的猪肉真贵,200块一斤"; NSString *sub1=[str1 substringFromIndex:4]; ...
- POJ-3126 Prime Path---BFS+素数打表
题目链接: https://vjudge.net/problem/POJ-3126 题目大意: 给两个四位数a,b 每次改变a中的一位而且改动之后的必须是素数,问最少改动几次可以到b?(永远达不到b就 ...