(二)requests-爬取国家药监局生产许可证数据
首先访问这个页面 url = 'http://125.35.6.84:81/xk/'
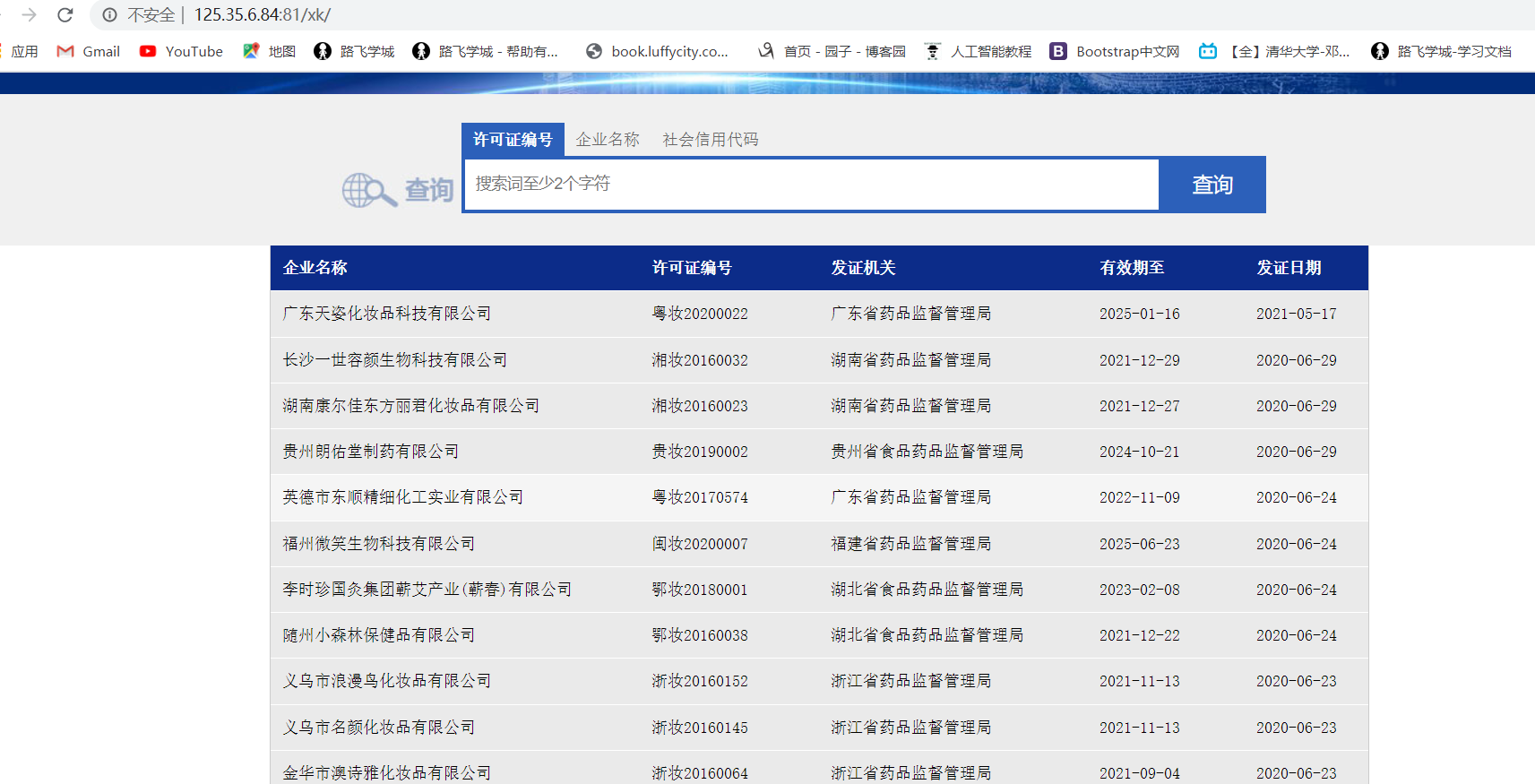
我们的目标是抓取这里的每一个企业的详情页数据,但是可以发现这里只有企业的简介信息,所以这就意味着我们要发送两次get请求。
在写代码之前,我们可以大概看一下我们想要的数据大概在什么位置。
1. 我们打开一个公司的详情页

2. 右击检查,通过Response查找对应的目标数据
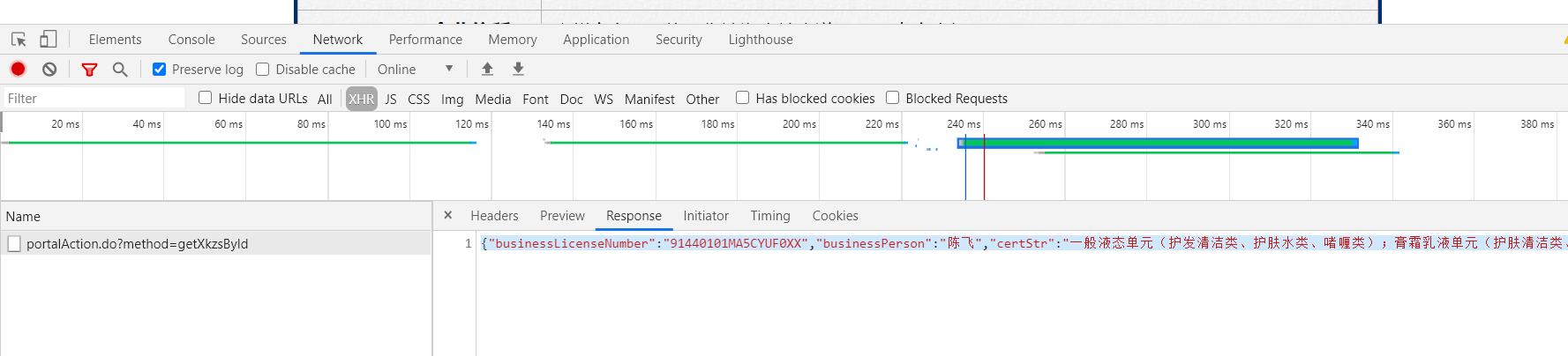
从这里我们可以看出,当前的数据是通过ajax请求动态加载出来的
3.查看头信息,以及参数信息

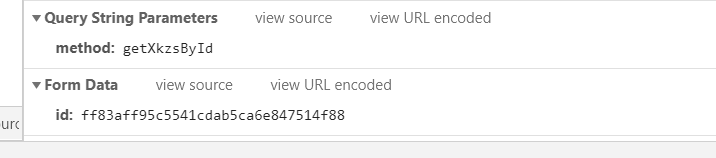
我们可以看出,当前的请求是post请求,所需要的参数是id,但是从以上的数据来看我们并没有发现哪里有id这个参数。因为我们将目光聚焦到首页。
4. 分析首页所返回的数据
同样是右击检查,打开抓包工具
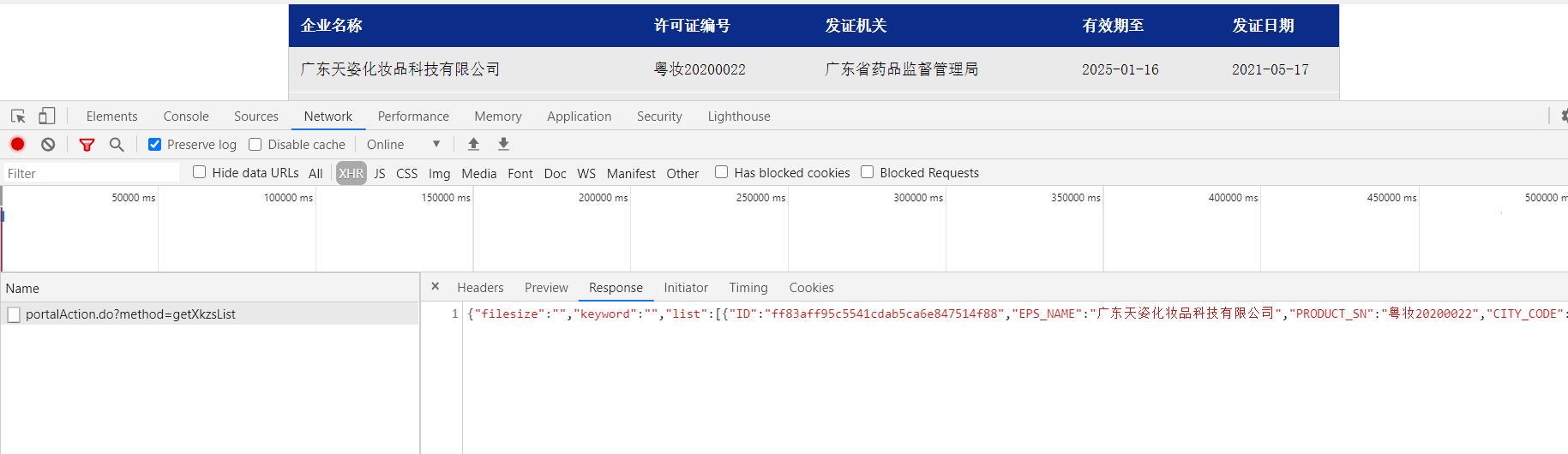
从这里我们可以看出首页的数据也是通过ajax动态加载出来的,并且通过观察我们可以发现在ID的踪迹,至此我们就可以形成一条完整的思路。
5.我们可以看看首页的请求方式,与是否携带了参数
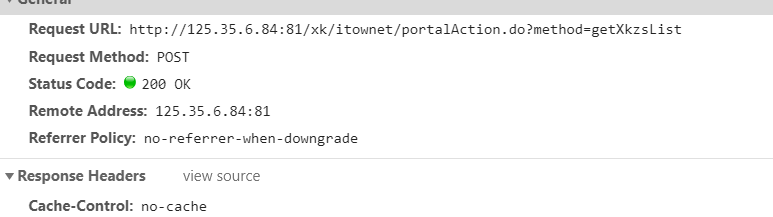
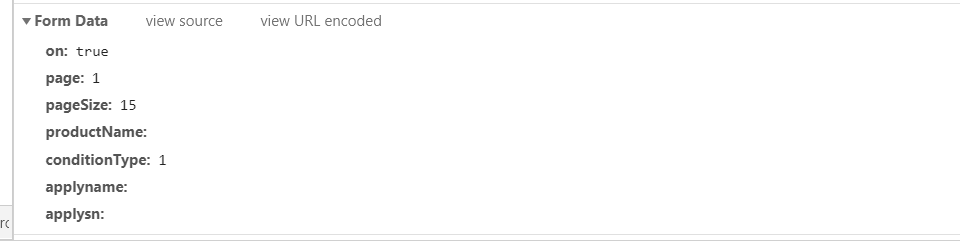
6. 思路:拿到首页的响应数据的ID,并以此为参数向详情页发送post请求,拿到每个详情页的详情数据。
7.代码实现:
import requests
import json if __name__ == '__main__':
# 获取各个企业id
id_list = []
# 这里的url并非是首页的url 首页中的所有企业信息都是通过ajax动态请求的 因此应查看对应包中的url
url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36'
}
# 获取前五页的数据
for page in range(1, 5):
page = str(page)
# 首页请求所需参数
data = {
'on': 'true',
'page': page,
'pageSize': '15',
'productName': '',
'conditionType': '1',
'applyname': '',
'applysn': ''
} # 向首页发送请求
response = requests.post(url=url, data=data, headers=header)
# 拿到json格式的数据
info = response.json()
# 拿到所有企业信息的列表
target_id = info['list']
for i in target_id:
# 获取所有企业的id
id_list.append(i['ID']) # 获取企业详情信息
ret_list = []
url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById' # 获取所有企业的详情数据
for i in id_list:
data = {
'id': i
}
ret = requests.post(url=url, data=data, headers=header)
ret_list.append(ret.json()) # 持久化存储
fileName = 'files/药监总局.json'
with open(fileName, 'w', encoding='utf-8') as f:
f.write(json.dumps(ret_list, ensure_ascii=False))
print('work is done')
(二)requests-爬取国家药监局生产许可证数据的更多相关文章
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- selenium爬取qq空间,requests爬取雪球网数据
一.爬取qq空间好友动态数据 # 爬取qq空间好友状态信息(说说,好友名称),并屏蔽广告 from selenium import webdriver from time import sleep f ...
- 爬虫(二)Python网络爬虫相关基础概念、爬取get请求的页面数据
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆 ...
- requests爬取百度音乐
使用requests爬取百度音乐,我想把当前热门歌手的音乐信息爬下来. 首先进行url分析,可以看到: 歌手网页: 薛之谦网页: 可以看到,似乎这些路劲的获取一切都很顺利,然后可以写代码: # -*- ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 爬虫学习(二)--爬取360应用市场app信息
欢迎加入python学习交流群 667279387 爬虫学习 爬虫学习(一)-爬取电影天堂下载链接 爬虫学习(二)–爬取360应用市场app信息 代码环境:windows10, python 3.5 ...
- Python爬虫入门——使用requests爬取python岗位招聘数据
爬虫目的 使用requests库和BeautifulSoup4库来爬取拉勾网Python相关岗位数据 爬虫工具 使用Requests库发送http请求,然后用BeautifulSoup库解析HTML文 ...
- Requests爬取网页的编码问题
Requests爬取网页的编码问题 import requests from requests import exceptions def getHtml(): try: r=requests.get ...
- Python爬虫系列之爬取美团美食板块商家数据(二)
今天为大家重写一个美团美食板块小爬虫,说不定哪天做旅游攻略的时候也可以用下呢.废话不多说,让我们愉快地开始吧~ 开发工具 Python版本:3.6.4 相关模块: requests模块: argpar ...
随机推荐
- 传统 Web 框架部署与迁移
简介: 与其说 Serverless 架构是一个新的概念,不如说它是一种全新的思路,一种新的编程范式. 与其说 Serverless 架构是一个新的概念,不如说它是一种全新的思路,一种新的编程范式. ...
- MaxCompute 公共云多租户设计的技术要点详解及产品实现特色
简介:公共云大数据平台在多租户的设计和实现方式上有所差异.本文主要介绍在公共云大数据平台的多租实现方案中需要考虑的问题和挑战,重点介绍了MaxCompute在计算和存储多租实现上的特点.期望通过这些 ...
- 深度解读 MongoDB 最全面的增强版本 4.4 新特性
MongoDB 在今年正式发布了新的 4.4 大版本,这次的发布包含众多的增强 Feature,可以称之为是一个维护性的版本,而且是一个用户期待已久的维护性版本,MongoDB 官方也把这次发布称为「 ...
- 阿里云 Serverless 助力企业全面拥抱云原生
简介:相信随着云计算的发展,Serverless 将成为云时代默认的计算范式,越来越多的企业客户将会采用这个技术. 作者:洛浩 Serverless 应用引擎的组件架构 最早的时候,大家设计软件一般 ...
- 开发日志:企业微信实现扫码登录(WEB)
一:获取扫码登陆所需的参数:appid,secret,agentid 登录企业微信:https://work.weixin.qq.com/ 扫码登录文档:https://work.weixin.qq. ...
- LVGL 显示图片
一.图片存储 我们可以将图像存储在两个位置 作为内部存储器(RAM或ROM)中的变量 作为文件 图片以文件的形式存储在文件系中(比如SD),需要打开LVGL的文件操作的功能(打开,读取,关闭等).虽然 ...
- vue解决二级路由redirect(默认路由)不传参的问题
场景: pageA----pageB(pageB包含三个二级路由) 默认进入pageB时进入第一个页面的路由,之后点击左侧按钮,分别进入其他二级路由 原router.js写法: //应用信息 ...
- SAP Adobe Form 教程四 动态隐藏和显示字段
前文: SAP Adobe Form 教程一 简单示例 SAP Adobe Form 教程二 表 SAP Adobe Form 教程三 日期,时间,floating field 本文链接:https: ...
- SAP Adobe Form 教程一 简单示例
马上需要用到adobe form,这里搬运一篇教程学习下. 英文原文:SAP Adobe Interactive Form Tutorial. Part I. First Adobe Form 本文链 ...
- 【简说Python WEB】Flask应用的单元测试
[简说Python WEB]Flask应用的单元测试 tests/test_basics.py import unittest from flask import current_app from a ...