Paper Reading - Im2Text: Describing Images Using 1 Million Captioned Photographs ( NIPS 2011 )
Link of the Paper: http://papers.nips.cc/paper/4470-im2text-describing-images-using-1-million-captioned-photographs.pdf
Main Points:
- A large novel data set containing images from the web with associated captions written by people, filtered so that the descriptions are likely to refer to visual content.
- A description generation method that utilizes global image representations to retrieve and transfer captions from their data set to a query image: authors achieve this by computing the global similarity ( a sum of gist similarity and tiny image color similarity ) of a query image to their large web-collection of captioned images; they find the closest matching image ( or images ) and simply transfer over the description from the matching image to the query image.
- A description generation method that utilizes both global representations and direct estimates of image content (objects, actions, stuff, attributes, and scenes) to produce relevant image descriptions.
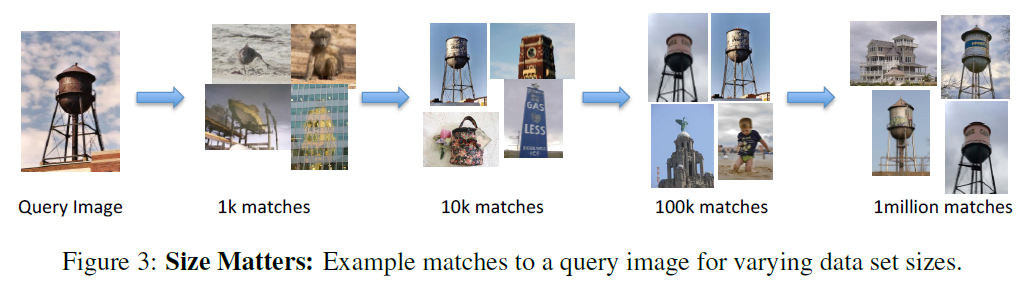
Other Key Points:
- Image captioning will help advance progress toward more complex human recognition goals, such as how to tell the story behind an image.
- An approach from Every picture tells a story: generating sentences for images produces image descriptions via a retrieval method, by translating both images and text descriptions to a shared meaning space represented by a single < object, action, scene > tuple. A description for a query image is produced by retrieving whole image descriptions via this meaning space from a set of image descriptions.
- The retrieval method relies on collecting and filtering a large data set of images from the internet to produce a novel web-scale captioned photo collection.
Paper Reading - Im2Text: Describing Images Using 1 Million Captioned Photographs ( NIPS 2011 )的更多相关文章
- Paper Reading: Stereo DSO
开篇第一篇就写一个paper reading吧,用markdown+vim写东西切换中英文挺麻烦的,有些就偷懒都用英文写了. Stereo DSO: Large-Scale Direct Sparse ...
- Paper Reading - Deep Captioning with Multimodal Recurrent Neural Networks ( m-RNN ) ( ICLR 2015 ) ★
Link of the Paper: https://arxiv.org/pdf/1412.6632.pdf Main Points: The authors propose a multimodal ...
- [Paper Reading]--Exploiting Relevance Feedback in Knowledge Graph
<Exploiting Relevance Feedback in Knowledge Graph> Publication: KDD 2015 Authors: Yu Su, Sheng ...
- Paper Reading: Perceptual Generative Adversarial Networks for Small Object Detection
Perceptual Generative Adversarial Networks for Small Object Detection 2017-07-11 19:47:46 CVPR 20 ...
- Paper Reading: In Defense of the Triplet Loss for Person Re-Identification
In Defense of the Triplet Loss for Person Re-Identification 2017-07-02 14:04:20 This blog comes ...
- Paper Reading - Attention Is All You Need ( NIPS 2017 ) ★
Link of the Paper: https://arxiv.org/abs/1706.03762 Motivation: The inherently sequential nature of ...
- Paper Reading - Convolutional Sequence to Sequence Learning ( CoRR 2017 ) ★
Link of the Paper: https://arxiv.org/abs/1705.03122 Motivation: Compared to recurrent layers, convol ...
- Paper Reading - Deep Visual-Semantic Alignments for Generating Image Descriptions ( CVPR 2015 )
Link of the Paper: https://arxiv.org/abs/1412.2306 Main Points: An Alignment Model: Convolutional Ne ...
- Paper Reading - Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation ( CVPR 2015 )
Link of the Paper: https://ieeexplore.ieee.org/document/7298856/ A Correlative Paper: Learning a Rec ...
随机推荐
- I、Python 环境搭建
I.安装Python https://www.python.org/downloads/windows/ 下载路径总是变,认准那个名字 安装, 记住,所有语言都推荐安装在 默认路径,不要相信那些让你改 ...
- 位图索引对于DML操作的影响
位图索引相对于常规的B-tree 索引,有着体积更加小的优势,节省空间.对于重复率特别高的字段,比如性别,比如省份.查询效率要优于B-tree 索引.那为什么我们总被告知在业务库中不要使用呢? 业务库 ...
- [iOS]CIDetector之CIDetectorTypeFace人脸识别
- (void)viewDidLoad { [super viewDidLoad]; // Do any additional setup after loading the view, typica ...
- Mac电脑用终端生成SSH key 访问自己的Github
链接:https://www.jianshu.com/p/5b34b7b34cae
- mysql的索引和执行计划
一.mysql的索引 索引是帮助mysql高效获取数据的数据结构.本质:索引是数据结构 1:索引分类 普通索引:一个索引只包含单个列,一个表可以有多个单列索引. 唯一索引:索引列的值必须唯一 ,但允许 ...
- iview中tree的事件运用
iview中的事件和方法如下: 案例说明: html代码 <Tree :data="data4" @on-check-change="choiceAll" ...
- Centos7前后台运行jar包
方式一: java -jar lf-test-1.0-SNAPSHOT.jar 前台运行,当前ssh窗口被锁定,可按CTRL + C打断程序运行,或直接关闭窗口,程序退出. 方式二: java -ja ...
- 快速认识LinkIt 7697开发板
LinkIt 7697是一款多功能且价格亲民的开发板,可用来连接网络或你的各项装置,同时提供Wi-Fi及蓝芽两种联机功能.此开发板采用MediaTek MT7697芯片,比起其他类似的Wi-Fi/蓝芽 ...
- 用k8s构建生产环境下应用服务
1.生成镜像 见https://www.cnblogs.com/mushou/p/9713741.html,把测试成熟的应用添加到tomcat镜像生成新的镜像,用ansible部署到集群的几点服务器中 ...
- jquery ajax实例教程和一些高级用法
jquery ajax的调用方式:jquery.ajax(url,[settings]),jquery ajax常用参数:红色标记参数几乎每个ajax请求都会用到这几个参数,本文将介绍更多jquery ...