大数据处理框架之Strom:事务
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
storm-0.9
apache-flume-1.6.0
一、storm三种事务
1、普通事务(常用)
2、Partitioned Transaction - 分区事务
3、Opaque Transaction - 不透明分区事务
二、普通事务设计
1、Design 1
强顺序流(强有序)
(1)引入事务(transaction)的概念,每个transaction(即每个tuple)关联一个transaction id。
(2)Transaction id从1开始,每个tuple会按照顺序+1。
(3)在处理tuple时,将处理成功的tuple结果以及transaction id同时写入数据库中进行存储。
缺点:
一次只能处理一个tuple,无法实现分布式计算
2、Design 2
强顺序的Batch流
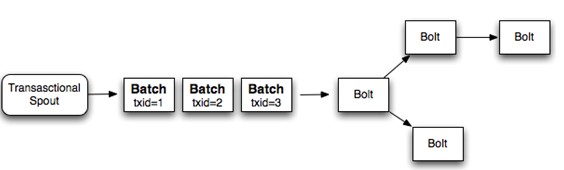
(1)事务(transaction)以batch为单位,即把一批tuple称为一个batch,每次处理一个batch。
(2)每个batch(一批tuple)关联一个transaction id
(3)每个batch内部可以并行计算
缺点:
由于维持强有序,当一个batch处理时,其他batch处于闲置状态,效率低。
3、Design 3
将Topology拆分为两个阶段:
1、Processing phase
允许并行处理多个batch
2、Commit phase
保证batch的强有序,一次只能处理一个batch
其他:
Manages state - 状态管理
Storm通过Zookeeper存储所有transaction相关信息(包含了:当前transaction id 以及batch的元数据信息)
Coordinates the transactions - 协调事务
Storm会管理决定transaction应该处理什么阶段(processing、committing)
Fault detection - 故障检测
Storm内部通过Acker机制保障消息被正常处理(用户不需要手动去维护)
First class batch processing API
Storm提供batch bolt接口
三、案例
Topology
package com.sxt.storm.transactional; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.transactional.TransactionalTopologyBuilder; public class MyTopo { /**
* @param args
*/
public static void main(String[] args) {
//
TransactionalTopologyBuilder builder = new TransactionalTopologyBuilder("ttbId","spoutid",new MyTxSpout(),1);
builder.setBolt("bolt1", new MyTransactionBolt(),3).shuffleGrouping("spoutid");
builder.setBolt("committer", new MyCommitter(),1).shuffleGrouping("bolt1") ; Config conf = new Config() ;
conf.setDebug(false); if (args.length > 0) {
try {
StormSubmitter.submitTopology(args[0], conf, builder.buildTopology());
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
}
}else {
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("mytopology", conf, builder.buildTopology());
}
}
}
Spout:
package com.sxt.storm.transactional; import java.util.HashMap;
import java.util.Map;
import java.util.Random; import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.transactional.ITransactionalSpout;
import backtype.storm.tuple.Fields; public class MyTxSpout implements ITransactionalSpout<MyMeta> { /**
* 数据源
*/
Map<Long, String> dbMap = null; public MyTxSpout() {
Random random = new Random();
dbMap = new HashMap<Long, String>();
String[] hosts = { "www.taobao.com" };
String[] session_id = {
"ABYH6Y4V4SCVXTG6DPB4VH9U123",
"XXYH6YCGFJYERTT834R52FDXV9U34",
"BBYH61456FGHHJ7JL89RG5VV9UYU7",
"CYYH6Y2345GHI899OFG4V9U567",
"VVVYH6Y4V4SFXZ56JIPDPB4V678"
};
String[] time = {
"2017-02-21 08:40:50",
"2017-02-21 08:40:51",
"2017-02-21 08:40:52",
"2017-02-21 08:40:53",
"2017-02-21 09:40:49",
"2017-02-21 10:40:49",
"2017-02-21 11:40:49",
"2017-02-21 12:40:49"
}; for (long i = 0; i < 100; i++) {
dbMap.put(i, hosts[0] + "\t" + session_id[random.nextInt(5)] + "\t" + time[random.nextInt(8)]);
}
} private static final long serialVersionUID = 1L; @Override
public backtype.storm.transactional.ITransactionalSpout.Coordinator<MyMeta> getCoordinator(Map conf,
TopologyContext context) {
return new MyCoordinator();
} @Override
public backtype.storm.transactional.ITransactionalSpout.Emitter<MyMeta> getEmitter(Map conf,
TopologyContext context) {
return new MyEmitter(dbMap);
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("tx", "log"));
} @Override
public Map<String, Object> getComponentConfiguration() {
return null;
} }
Bolt:
package com.sxt.storm.transactional; import java.util.Map; import backtype.storm.coordination.BatchOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseTransactionalBolt;
import backtype.storm.transactional.TransactionAttempt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; public class MyTransactionBolt extends BaseTransactionalBolt { /**
*
*/
private static final long serialVersionUID = 1L; Integer count = 0;
BatchOutputCollector collector;
TransactionAttempt tx ; @Override
public void prepare(Map conf, TopologyContext context,
BatchOutputCollector collector, TransactionAttempt id) {
this.collector = collector;
System.err.println("MyTransactionBolt prepare txid:"+id.getTransactionId() +"; attemptid: "+id.getAttemptId());
} /**
* 处理batch中每一个tuple
*/
@Override
public void execute(Tuple tuple) { tx = (TransactionAttempt) tuple.getValue(0);
System.err.println("MyTransactionBolt TransactionAttempt txid:"+tx.getTransactionId() +"; attemptid:"+tx.getAttemptId());
String log = tuple.getString(1);
if (log != null && log.length()>0) {
count ++ ;
}
} /**
* 同一个batch处理完成后,会调用一次finishBatch方法
*/
@Override
public void finishBatch() {
System.err.println("finishBatch: "+count );
collector.emit(new Values(tx,count));
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("tx","count"));
} }
package com.sxt.storm.transactional; import java.math.BigInteger;
import java.util.HashMap;
import java.util.Map; import backtype.storm.coordination.BatchOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseTransactionalBolt;
import backtype.storm.transactional.ICommitter;
import backtype.storm.transactional.TransactionAttempt;
import backtype.storm.tuple.Tuple; public class MyCommitter extends BaseTransactionalBolt implements ICommitter { /**
*
*/
private static final long serialVersionUID = 1L; public static final String GLOBAL_KEY = "GLOBAL_KEY";
public static Map<String, DbValue> dbMap = new HashMap<String, DbValue>();
int sum = 0;
TransactionAttempt id;
BatchOutputCollector collector; @Override
public void execute(Tuple tuple) {
sum += tuple.getInteger(1);
} @Override
public void finishBatch() { DbValue value = dbMap.get(GLOBAL_KEY);
DbValue newValue;
//
if (value == null || !value.txid.equals(id.getTransactionId())) {
// 更新数据库
newValue = new DbValue();
newValue.txid = id.getTransactionId();
if (value == null) {
newValue.count = sum;
} else {
newValue.count = value.count + sum;
}
dbMap.put(GLOBAL_KEY, newValue);
} else {
newValue = value;
}
System.out.println("total==========================:" + dbMap.get(GLOBAL_KEY).count);
// collector.emit(tuple)
} @Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, TransactionAttempt id) {
this.id = id;
this.collector = collector;
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) { } public static class DbValue {
BigInteger txid;
int count = 0;
} }
package com.sxt.storm.transactional; import java.math.BigInteger; import backtype.storm.transactional.ITransactionalSpout;
import backtype.storm.utils.Utils; public class MyCoordinator implements ITransactionalSpout.Coordinator<MyMeta>{ // batch中消息条数
public static int BATCH_NUM = 10 ; /**
* 在initializeTransaction前执行
* 确认数据源是否已经准备就绪,可以读取数据
* 返回值 true、false
*/
@Override
public boolean isReady() {
Utils.sleep(2000);
return true;
} /**
* txid:事务序列号
* prevMetadata:之前事务的元数据(如果第一次启动事务,则为null)
* 返回值:当前事务的元数据
*/
@Override
public MyMeta initializeTransaction(BigInteger txid, MyMeta prevMetadata) {
long beginPoint = 0;
if (prevMetadata == null) {
beginPoint = 0 ;
}else {
beginPoint = prevMetadata.getBeginPoint() + prevMetadata.getNum() ;
} MyMeta meta = new MyMeta() ;
meta.setBeginPoint(beginPoint);
meta.setNum(BATCH_NUM);
System.err.println("启动一个事务:"+meta.toString());
return meta;
} @Override
public void close() { }
}
package com.sxt.storm.transactional;
import java.io.Serializable;
public class MyMeta implements Serializable{
/**
*
*/
private static final long serialVersionUID = 1L;
private long beginPoint ;//事务开始位置
private int num ;//batch 的tuple个数
@Override
public String toString() {
return getBeginPoint()+"----"+getNum();
}
public long getBeginPoint() {
return beginPoint;
}
public void setBeginPoint(long beginPoint) {
this.beginPoint = beginPoint;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
}
package com.sxt.storm.transactional; import java.math.BigInteger;
import java.util.Map; import backtype.storm.coordination.BatchOutputCollector;
import backtype.storm.transactional.ITransactionalSpout;
import backtype.storm.transactional.TransactionAttempt;
import backtype.storm.tuple.Values; public class MyEmitter implements ITransactionalSpout.Emitter<MyMeta>{ Map<Long, String> dbMap = null;
public MyEmitter(Map<Long, String> dbMap) {
this.dbMap = dbMap;
} @Override
public void cleanupBefore(BigInteger txid) { } @Override
public void close() { } /**
* 发送tuple的batch
*/
@Override
public void emitBatch(TransactionAttempt tx, MyMeta coordinatorMeta,
BatchOutputCollector collector) { long beginPoint = coordinatorMeta.getBeginPoint() ;
int num = coordinatorMeta.getNum() ; for (long i = beginPoint; i < num+beginPoint; i++) {
if (dbMap.get(i)==null) {
continue;
}
/**
* 必须以TransactionAttempt第一位发送
* _txid: transaction id 每组batch中的tuple必须为同一id,不论replay多少次
* _attemptId
*/
collector.emit(new Values(tx,dbMap.get(i)));
}
} }
大数据处理框架之Strom:事务的更多相关文章
- 大数据处理框架之Strom: Storm----helloword
大数据处理框架之Strom: Storm----helloword Storm按照设计好的拓扑流程运转,所以写代码之前要先设计好拓扑图.这里写一个简单的拓扑: 第一步:创建一个拓扑类含有main方法的 ...
- 大数据处理框架之Strom:认识storm
Storm是分布式实时计算系统,用于数据的实时分析.持续计算,分布式RPC等. (备注:5种常见的大数据处理框架:· 仅批处理框架:Apache Hadoop:· 仅流处理框架:Apache Stor ...
- 大数据处理框架之Strom:Flume+Kafka+Storm整合
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 apache-flume-1.6.0 ...
- 大数据处理框架之Strom: Storm拓扑的并行机制和通信机制
一.并行机制 Storm的并行度 ,通过提高并行度可以提高storm程序的计算能力. 1.组件关系:Supervisor node物理节点,可以运行1到多个worker,不能超过supervisor. ...
- 大数据处理框架之Strom:DRPC
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 一.DRPC DRPC:Distri ...
- 大数据处理框架之Strom:Storm集群环境搭建
搭建环境 Red Hat Enterprise Linux Server release 7.3 (Maipo) zookeeper-3.4.11 jdk1.7.0_80 Pyth ...
- 大数据处理框架之Strom:redis storm 整合
storm 引入redis ,主要是使用redis缓存库暂存storm的计算结果,然后redis供其他应用调用取出数据. 新建maven工程 pom.xml <project xmlns=&qu ...
- 大数据处理框架之Strom:kafka storm 整合
storm 使用kafka做数据源,还可以使用文件.redis.jdbc.hive.HDFS.hbase.netty做数据源. 新建一个maven 工程: pom.xml <project xm ...
- 大数据处理框架之Strom:容错机制
1.集群节点宕机Nimbus服务器 单点故障,大部分时间是闲置的,在supervisor挂掉时会影响,所以宕机影响不大,重启即可非Nimbus服务器 故障时,该节点上所有Task任务都会超时,Nimb ...
随机推荐
- Xml xpath samples
Xml: <?xml version="1.0" encoding="utf-8" ?> <Orders xmlns="http:/ ...
- Java学习之App开发公司手机端设想
背景:最近在学JAVA,看到JAVA做各种APP,而公司软件主要是做家居设计,使用者多是设计师和家具门店,很难让大部分非专业人士接触到我们的产品,由于设计复杂且占用资源较多不太可能用APP实现网站设计 ...
- linux 挂载硬盘
fdisk -l mkfs.ext4 /dev/vdb mkdir /data mount -t ext4 /dev/vdb /data 编辑/etc/fstab /dev/vdb /data ext ...
- Py修行路 python基础 (七)文件操作 笔记(随时更改添加)
文件操作流程: 1.打开文件 open() 2.操作文件 read .writeread(n) n对应读指定个数的 2.x中读取的是字节! 3.x中读取的是字符!read 往外读取文件,是以光标位置开 ...
- 处理大数据对象clob数据和blob数据
直接上下代码: package com.learn.jdbc.chap06; import java.io.File; import java.io.FileInputStream; import j ...
- Delphi PDF
llPDFLib,TPDFDocument 2016开始开源. procedure TForm2.Button1Click(Sender: TObject); var lPdf : TPdfDocum ...
- elastic(10) 基本查询
# 指定index名以及type名的搜索 GET /library/books/_search?q=title:elasticsearch # 指定index名没有type名的搜索 GET /libr ...
- 通过class类获取类的成员变量和构造函数信息
- Resin 的watchdog(看门狗)介绍和resin负载均衡实现
为了稳定和安全,Resin使用一个独立的watchdog进程来启动和监视Resin服务器.watchdog连续你检测Resin服务器的状态,如果其没有反应或者迟钝,将会重启Resin服务器进程.大多数 ...
- SpringBoot15 sell01 项目创建、MySQL数据库连接、日志配置、开发热部署、商品信息模块
项目软件版本说明: jdk: 1.8 springboot: 2.0.1 mysql: 5.7 1 项目创建 创建一个SpringBoot项目即可,创建是勾选 web jpa mysql 这三个依赖就 ...