Python-json 和 pickle
前面介绍了对于confluence和jira的破解版安装记录,下面简单记录下confluence和jira结合配置:
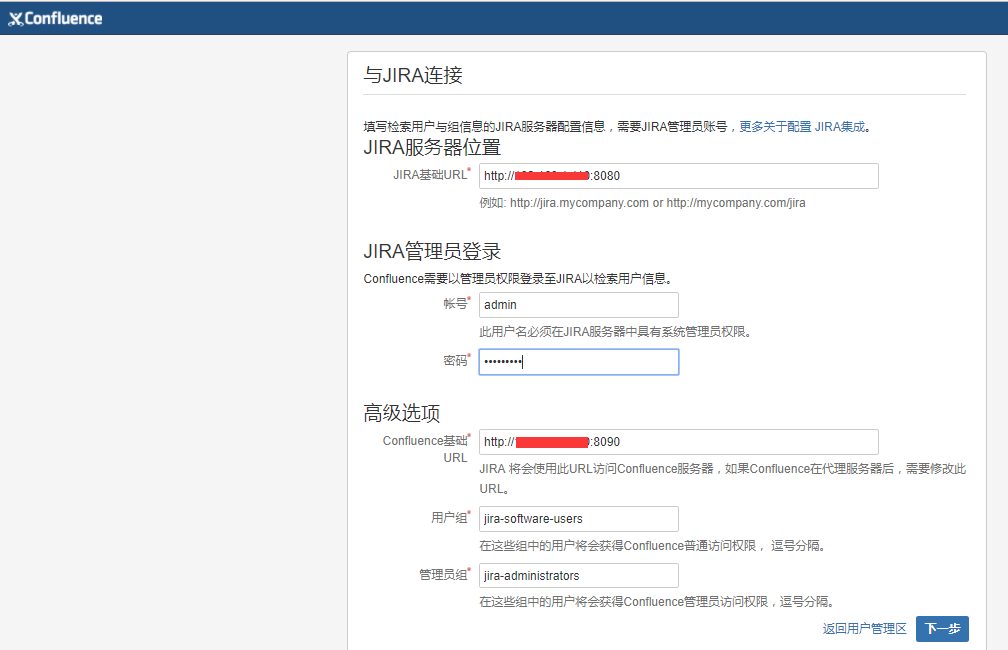
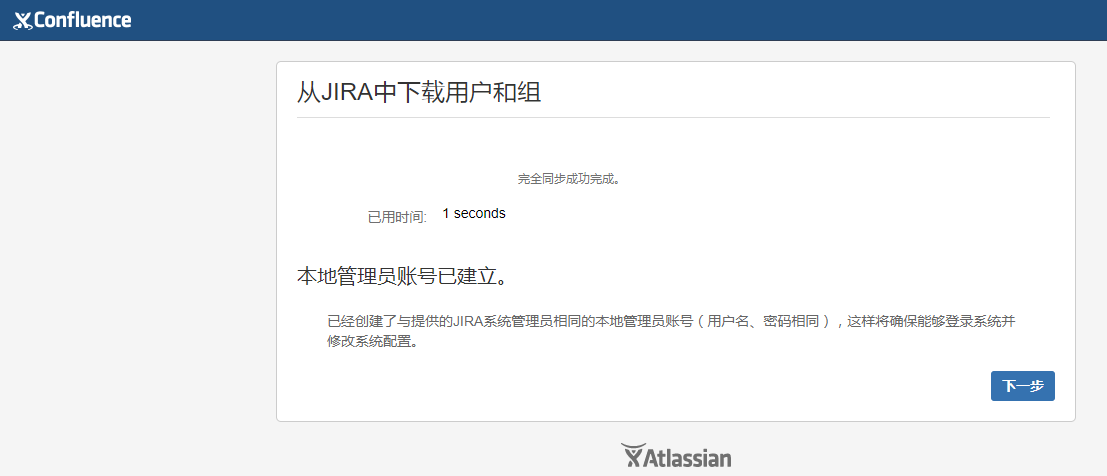
安装顺序:先安装Jira,然后安装Confluence,在Confluence安装过程中去连接jira,既Confluence用户目录会主动同步jira的用户目录。这样,在jira里创建用户就会自动同步到Confluence里,双方登陆的用户是一样的(最好是先在jira里创建用户,然后同步到Confluence里)。在同一个session环境下,可以使用同样的账号登陆jira和Confluence。(但是在切换登陆时仍然需要输入密码,要想切换登陆时不需要登陆密码,即实现单点登录,则需要基于Crowd实现,这样就不做介绍了)。
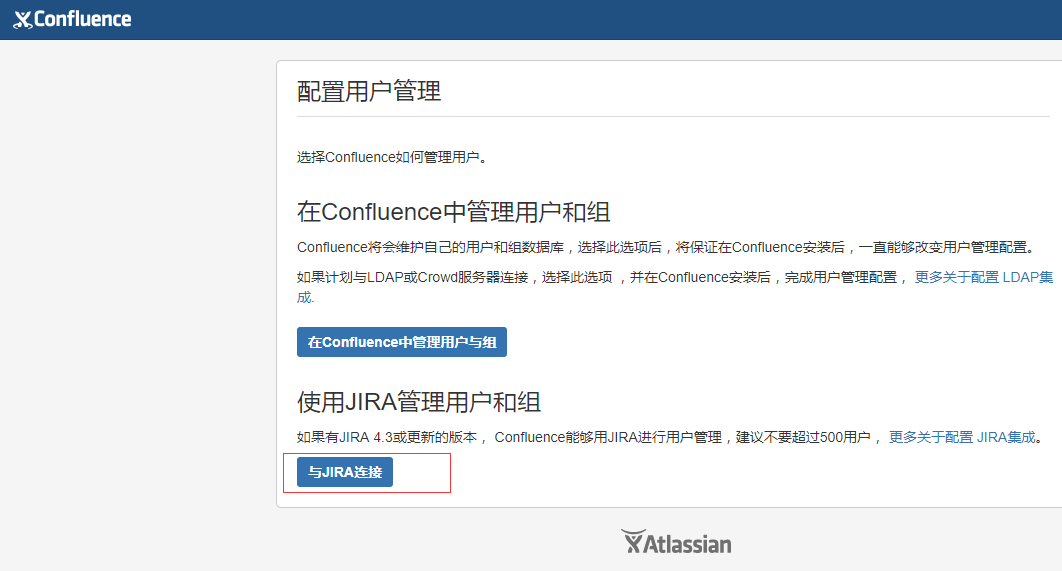
下面粘贴下Confluence安装中连接jira的截图:
===============================================================================
如果是先安装的confluence,并且在"配置用户管理"中选择的是"在Confluence中管理用户和组",那么后续向跟jira对接的操作方法如下:
1)jira和confluence最好设置相同的管理员账号和密码
2)登录confluence管理员账号下,依次点击右上角的"用户管理"->点击左侧最下面的"管理"中的"应用程序链接"->"创建新链接",然后添加jira的url地址,根据提示进行添加配置即可(提示中会跳到jira界面里,相继添加confluence的地址)
3)左上角jira和confluence对接的标题名称可以自定义,jira在"系统"->"一般配置"->编辑"标题";confluence在"一般配置"->编辑"标题"
===============================================================================
1)在jira里创建的用户,会主动给用户发送一封邮件,点击邮件可以重置密码。使用该用户登录后,点击左上角图标,切换到confluence后进行该用户的界面
设置,这样该用户才能载入到confluence用户目录下。
2)在jira里创建和删除用户,默认confluence同步是需要一段时间的。如果用户同步不及时,可以手动同步,即点击"用户目录"->"同步",即手动同步用户目录即可!(删除用户最后先在jira里删除,然后Confluence同步用户)

一般来说,用户创建(建议使用"邀请用户"的方式创建用户)的规则:
1)如果jira和Confluence都需要创建用户,就先在jira上创建用户,然后Confluence同步。
2)如果只需要Confluence账号,不需要jira账号。那么就在Confluence上"邀请用户"注册账号,然后同步到jira上的账号默认不能登录,需要将用户添加到jira的相关用户组内才能够登录。
========================================================
confluence和jira的用户目录同步方式:
根据以上部署可知,confluence和jira的用户同步是单方向的,及confluence同步jira的用户,但是jira不能同步confluence用户!
在配置用户目录同步时,点击"添加目录",发现只有三种同步方式:
1)添加Crowd服务器,可以实现jira和confluence用户目录双向同步;
2)添加LDAP服务器,可以实现jira和confluence用户目录双向同步;
3)添加Jira服务器,只能实现confluence同步jira用户目录,即单向同步。
=================================================
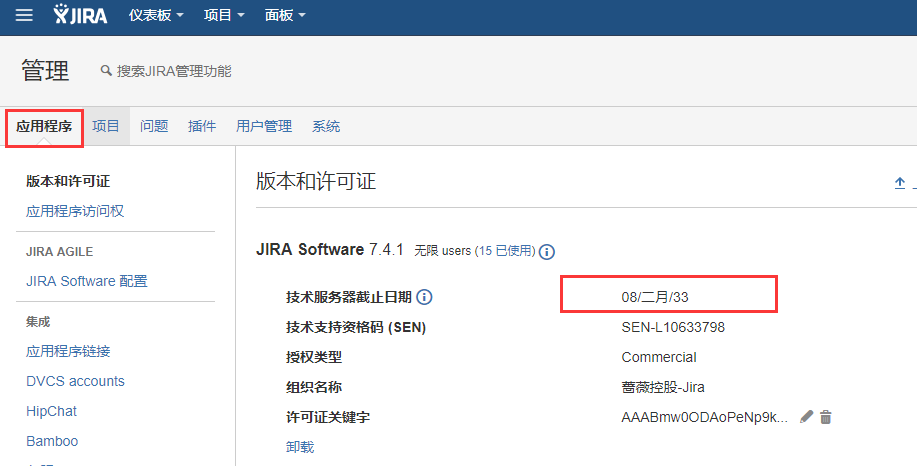
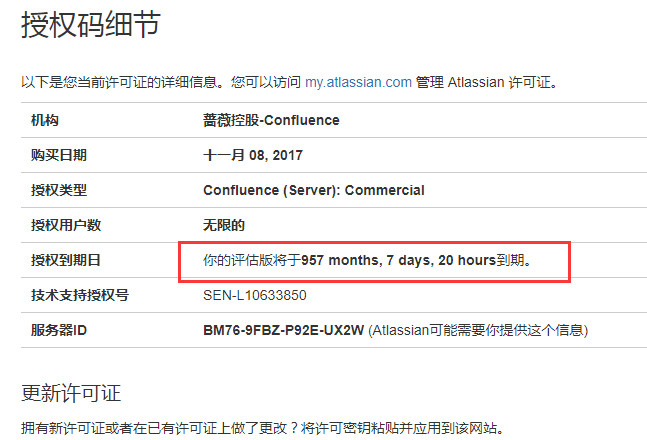
如何查看破解后的的jira和Confluence到期时间
1)查看jira的到期时间。如下可知,jira到期时间是2033年2月8号
2)查看Confluence的到期时间。如下可知,Confluence离到期时间还有957个月零7天20小时

=====confluence上开通用户,使该用户只具有某一个或几个项目空间的操作权限=====
方法:
1)正常开通用户,比如A用户。
2)创建一个用户组,比如test用户组(默认是空的)。
3)点击右上角设置图标里的"用户管理"->"站点管理"->"用户"->"全局权限",然后编辑test组权限(设置"个人空间"、"创建空间"两个权限即可,
"站点管理"和"系统管理员"权限看情况是否设置)
4)编辑A用户,将A用户所属的组设置为test。注意:千万不要设置为confluence-users组,否则就对所有的项目空间都具有权限。
5)假设使A用户仅仅只具有kevin项目的操作权限。则打开kevin名称的目录空间,点击左下角的"空间管理"->"权限",在右边的"用户"区域(或者"组"区域)点击
"编辑权限",将A用户(或者test组)添加进去,并设置权限(比如只设置"查看"权限)即可。
6)如果是一个用户针对多个项目空间的权限,就依次在这些项目空间的"空间管理"->"权限"里设置,如上第4步操作即可。 如上操作后,A用户登录confluence就只有所设置的空间的权限了。
jira跟confluence不一样,它只有角色权限,针对组进行设置的,不针对个人。jira权限设置:"系统"->"安全"->"全局权限"
=====jira/confluence访问界面出现"您可以临时访问管理功能。如果不再需要,请 取消访问。更多信息, 请查看 相关文档"======
如何取消?
1)需要在JIRA的Home文件夹里手工创建一个文件:jira-config.properties,文件里面写一句话jira.websudo.is.disabled=true
2)重启JIRA服务即可 具体操作:
a)查询jira服务的家目录
[root@file-server ~]# cat /opt/atlassian/jira/atlassian-jira/WEB-INF/classes/jira-application.properties
# Do not modify this file unless instructed. It is here to store the location of the JIRA home directory only and is typically written to by the installer.
jira.home = /var/atlassian/application-data/jira 如上可以得知,jira服务的家目录是/var/atlassian/application-data/jira b)在jira家目录下添加文件
[root@file-server ~]# cd /var/atlassian/application-data/jira
[root@file-server jira]# touch jira-config.properties
[root@file-server jira]# vim jira-config.properties
jira.websudo.is.disabled=true
[root@file-server jira]# chown jira.jira jira-config.properties c)重启jira
[root@file-server jira]# /etc/init.d/jira stop
[root@file-server jira]# /etc/init.d/jira start
==========jira和confluence调整为域名访问的操作记录============
如之前的安装文档,jira和confluence安装后都是通过ip+port进行访问以及关联,后面调整为域名访问,修改记录如下:
1)在前面架设一个LB层,通过域名访问代替ip+port访问,然后将域名解析到LB的ip上即可。例如:
http://jira.kevin-inc.com 代替http://172.16.220.129:8080
http://wiki.kevin-inc.com 代替http://172.16.220.129:8090
2)访问http://wiki.kevin-inc.com,在右上角
a)点击"一般配置",将"服务器主页URL"由http://172.16.220.129:8090修改为http://wiki.kevin-inc.com;
b)点击"配置应用程序链接",将对应的ip的url修改为域名的url;
c)点击"应用程序导航器",发现confluence对应的url已经变成wiki域名了,此时jira的链接还是ip+port方式,
接着进行添加操作,将jira的域名方式添加进去,然后将之前的ip+port方式的链接拉到最下面。(这个配置
涉及到从confluence界面的左上角切换到jira后显示的地址信息)
3)访问http://jira.kevin-inc.com,在右上角
a)点击点击"一般配置",将"服务器主页URL"由http://172.16.220.129:8080修改为http://jira.kevin-inc.com;
b)点击"应用程序"->"应用程序链接",将对应的ip的url修改为域名的url;
c)点击"应用程序导航器",将对应的ip的url修改为域名的url;
===========jira账号创建项目的权限==========
默认创建的jira账号是没有创建jira项目的权限的,如果想让一个jira账号拥有创建项目的权限,正确做法如下:
1)创建一个组,比如叫jira-project
2)点击右上角的"系统"->"安全"->"全局配置",然后将所创建的组jira-project设置为"JIRA 管理员",注意是
"JIRA 管理员",而不是"JIRA 系统管理员"
3)然后将用户拉到jira-project组内即可!
===========confluence和jira的备份和恢复==========
confluence的自动备份:
数据备份目录:/var/atlassian/application-data/confluence/backups ("站点管理"->"每日备份管理")
附件备份目录:/var/atlassian/application-data/confluence/attachments ("站点管理"->"附件存储") confluence备份与还原 ("站点管理"->"管理"->"备份与还原") 可以根据界面里提示进行数据恢复
如果从confluence主目录中由备份和恢复
备份必须复制至/var/atlassian/application-data/confluence/restore目录中。 如果备份文件很大,推荐这种方式 ---------------------------------------------------------------- jira的自动备份
数据备份目录: /var/atlassian/application-data/jira/export ("系统"->"导入导出"->"备份系统")
附件所在目录:/var/atlassian/application-data/jira/data/attachments 这个需要手动备份 jira的数据恢复: ("系统"->"导入导出"->"恢复系统")
========confluence管理员admin账号密码忘记的处理办法========
1)登录mysql,查看admin账号情况,记下admin管理员的id号
[root@confluence-server ~]# mysql -p123456
......
MariaDB [(none)]> use confluence;
......
MariaDB [confluence]> select id,user_name,credential from cwd_user;
+--------+-----------+---------------------------------------------------------------------------+
| id | user_name | credential |
+--------+-----------+---------------------------------------------------------------------------+
| 229377 | admin | {PKCS5S2}1QX4TpvSnyJPEwfJ5Y5OQDIxaHPqkrYlsRAPSvd4quVt3wku9WPKugZxSlUCYV71 |
+--------+-----------+---------------------------------------------------------------------------+
1 row in set (0.000 sec) MariaDB [confluence]> 2)根据admin的id号进行update更新密码。如果你的密码是{PKCS5S2}前缀开头的,则用下面这个sql:
如下密码修改为"Ab123456"(下面的密码就是Ab123456的密文)
MariaDB [confluence]> update cwd_user set credential = '{PKCS5S2}ltrb9LlmZ0QDCJvktxd45WgYLOgPt2XTV8X7av2p0mhPvIwofs9bHYVz2OXQ6/kF' where id=229377;
Query OK, 0 rows affected (0.057 sec)
Rows matched: 1 Changed: 0 Warnings: 0 MariaDB [confluence]> select id,user_name,credential from cwd_user;
+--------+-----------+---------------------------------------------------------------------------+
| id | user_name | credential |
+--------+-----------+---------------------------------------------------------------------------+
| 229377 | admin | {PKCS5S2}ltrb9LlmZ0QDCJvktxd45WgYLOgPt2XTV8X7av2p0mhPvIwofs9bHYVz2OXQ6/kF |
+--------+-----------+---------------------------------------------------------------------------+
1 row in set (0.000 sec) MariaDB [confluence]> 3)然后使用更新后的新密码Ab123456登录admin账号,在confluence界面里进行密码重置。
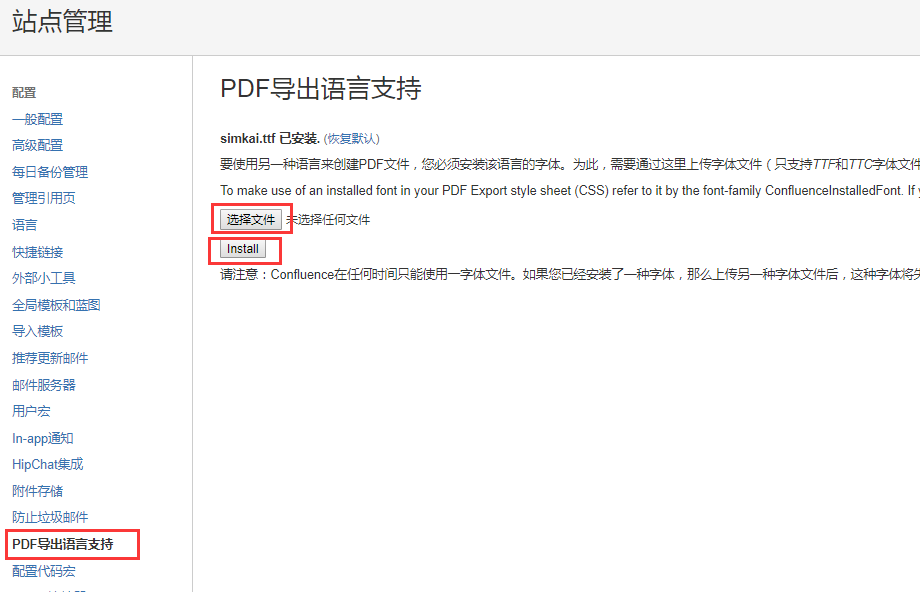
========confluence导出PDF格式文件不显示中文解决========
由于confluence导出PDF格式文件需要应用字体文件,下载字体文件在confluence管理员界面安装即可。
从本机c盘->Windows-Fonts文件夹里复制simkai字体文件到桌面,然后使用管理员账号登陆confluence,找到"PDF导出语言支持"选择,
选择本机桌面的simkai字体文件进行安装即可。安装后,导出的pdf文件里的中文就能正常显示了。
=========================离职人员的jira/confluence账号销毁=========================
员工离职时是不能直接在jira/confluence里删除他们账号的,因为这些账号关联了对应项目,除非修改为其他账号的关联关系, 否则不能直接删除. 但是可以禁用这些账号.
可行的处理方法:
1) 管理员账号登录jira, 点右上角的"设置"->"用户管理"->"用户",直接搜索离职人员的对应账号, 点击后面的"编辑", 将"活跃"前面方框里的对勾去掉, 即改为了"不活跃"状态, 这样该用户就登录不了jira了! 然后使用管理员账号登录confluence, 点击右上角的"设置"->"用户管理"->"用户目录"->"同步". 然后在"用户"里搜索离职人员账号,发现账号上被标记了"无效",即登录不了confluence了!
2) 如果离职的人员是jira上某些项目关联负责人, 则也是无法设置为"不活跃"的, 即无法注释"编辑"->"活跃", 此时的做法是:
将此账号从它之前所有所在的组内撤出来, 即确保它在jira/confluence下不属于任何组, 这样它登录后就没有任何权限了.
==============================Confluence问题============================
1)问题一:
JVM 堆内存溢出,导致confluence访问慢或程序直接跑死问题
查看/opt/atlassian/confluence/logs/catalina.out日志,报错信息为:
java.lang.OutOfMemoryError: Direct buffer memory 解决办法:增大JVM内存,做法如下:
在bin/catalina.sh脚本文件里添加下面一行内容,具体内存增加到多少,要根据自己服务器的实际内存来考虑(比如我的机器是128G,这里我调整到24G)
[root@file-server ~]# vim /opt/atlassian/confluence/bin/catalina.sh
......
JAVA_OPTS='-Xms20480m -Xmx20480m -XX:PermSize=10240M -XX:MaxNewSize=10240m -XX:MaxPermSize=5120m' [root@file-server ~]# /etc/init.d/confluence restart
-------------------------------------------------------------------------------------------------------------- 2)问题二:
confluence正常启动,8090端口也顺利起来了,但是confluence访问报错404!
[root@file-server ~]# tail -f /opt/atlassian/confluence/logs/catalina.out
........
11-Jan-2018 09:10:46.527 SEVERE [http-nio-8090-exec-6] org.springframework.web.socket.sockjs.client.SockJsClient.doHandshake Initial SockJS "Info" request to server failed,
url=ws://127.0.0.1:8091/synchrony/sockjs/v1org.springframework.web.client.ResourceAccessException: I/O error on GET request for "http://127.0.0.1:8091/synchrony/sockjs/v1/info":
Connection refused (Connection refused); nested exception is java.net.ConnectException: Connection refused (Connection refused)
at org.springframework.web.client.RestTemplate.doExecute(RestTemplate.java:607)
at org.springframework.web.client.RestTemplate.execute(RestTemplate.java:572)
at org.springframework.web.socket.sockjs.client.RestTemplateXhrTransport.executeInfoRequestInternal(RestTemplateXhrTransport.java:138)
at org.springframework.web.socket.sockjs.client.AbstractXhrTransport.executeInfoRequest(AbstractXhrTransport.java:153)
at org.springframework.web.socket.sockjs.client.SockJsClient.getServerInfo(SockJsClient.java:286)
at org.springframework.web.socket.sockjs.client.SockJsClient.doHandshake(SockJsClient.java:254)
at org.springframework.web.socket.sockjs.client.SockJsClient.doHandshake(SockJsClient.java:236)
at com.atlassian.synchrony.proxy.websocket.WebSocketProxy.afterConnectionEstablished(WebSocketProxy.java:49)
at org.springframework.web.socket.handler.PerConnectionWebSocketHandler.afterConnectionEstablished(PerConnectionWebSocketHandler.java:81) 特别注意:
confluence和jira的日志不只是只在/opt/atlassian/confluence/logs和/opt/atlassian/jira/logs下面,有时只根据这里面的日志是看不到具体报错的!
还需要去confluence和jira服务的家目录/var/atlassian/application-data(默认就是这个路径)下面查看日志,可以通过这里面的日志信息进行排错。
日志分别为/var/atlassian/application-data/jira/log/atlassian-jira.log和/var/atlassian/application-data/confluence/logs/atlassian-confluence.log
以上报错查看confluence日志如下
[root@file-server ~]# tail -f /var/atlassian/application-data/confluence/logs/atlassian-confluence.log
......
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'hostComponentProvider': Injection of autowired dependencies failed; nested exception is
org.springframework.beans.factory.BeanCreationException: Could not autowire method: public void com.atlassian.plugin.spring.SpringHostComponentProviderFactoryBean.setSpringHos
tComponentProviderConfig(com.atlassian.plugin.spring.SpringHostComponentProviderConfig); nested exception is org.springframework.beans.factory.BeanCreationException: Error cre
ating bean with name 'bundledPluginLoader' defined in class path resource [services/pluginServiceContext.xml]: Cannot resolve reference to bean 'osgiPluginFactory' while setting
constructor argument with key [1]; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'osgiPluginFactory' defined in class
path resource [services/pluginServiceContext.xml]: Cannot resolve reference to bean 'osgiPersistentCache' while setting constructor argument; nested exception is org.springframework.
beans.factory.BeanCreationException: Error creating bean with name 'osgiPersistentCache': FactoryBean threw exception on object creation; nested exception is com.atlassian.plugin.osgi.
container.OsgiContainerException: Unable to clean the cache directory: /var/atlassian/application-data/confluence/plugins-osgi-cache/felix 通过上面的日志错误信息可知,是由于cache缓存目录的权限不对造成的:
[root@file-server ~]# ll -d /var/atlassian/application-data/confluence/plugins-osgi-cache
drwxr-xr-x 5 root root 4096 Nov 9 10:54 /var/atlassian/application-data/confluence/plugins-osgi-cache plugins-osgi-cache目前权限是root,confluence程序权限是confluence,所以不能创建缓存数据。将其权限修改为confluence即可!
建议可以将/var/atlassian/application-data/confluence下的目录权限全部修改为confluence.confluence。
[root@file-server ~]# chown -R confluence.confluence /var/atlassian/application-data/confluence/plugins-osgi-cache
[root@file-server ~]# ll -d /var/atlassian/application-data/confluence/plugins-osgi-cache
drwxr-xr-x 5 confluence confluence 4096 Nov 9 10:54 /var/atlassian/application-data/confluence/plugins-osgi-cache 如上修改后,访问confluence就正常了(可以不用重启confluence)
-------------------------------------------------------------------------------------------------------------- 问题三:
confluence登陆后,上传附件报错:Could not upload the file to Confluence. The server may be unavailable 查看日志:
[root@file-server ~]# tail -f /var/atlassian/application-data/confluence/logs/atlassian-confluence.log
......
javax.servlet.jsp.jspException: java.lang.RuntimeException: Error creating temp file in folder: /var/atlassian/application-data/confluence/attachments/ver003/21/87/4587521/92/247/3997842/5144597
javax.servlet.error.exception: java.lang.RuntimeException: Error creating temp file in folder: /var/atlassian/application-data/confluence/attachments/ver003/21/87/4587521/92/247/3997842/5144597 由此可以看出,附件不能上传的原因是由于权限问题导致的,解决如下:
[root@file-server ~]# ll -d /var/atlassian/application-data/confluence/attachments/ver003/
drwxr-xr-x 11 root root 4096 Jan 9 09:14 /var/atlassian/application-data/confluence/attachments/ver003/
[root@file-server ~]# chown -R confluence.confluence /var/atlassian/application-data/confluence/attachments
[root@file-server ~]# ll -d /var/atlassian/application-data/confluence/attachments/ver003/
drwxr-xr-x 11 confluence confluence 4096 Jan 9 09:14 /var/atlassian/application-data/confluence/attachments/ver003/
Python-json 和 pickle的更多相关文章
- Python json和pickle模块
用于序列化的两个模块 json,用于字符串 和 python数据类型间进行转换 pickle,用于python特有的类型 和 python的数据类型间进行转换 Json模块提供了四个功能:dumps. ...
- python json、pickle
文章部分转自:https://www.cnblogs.com/lincappu/p/8296078.html json:用于字符串和Python数据类型间进行转换pickle: 用于python特有的 ...
- Python json与pickle
这是用于序列化的两个模块: • json: 用于字符串和python数据类型间进行转换 • pickle: 用于python特有的类型和python的数据类型间进行转换 Json模块提供了四个功能:d ...
- python json、 pickle 、shelve 模块
json 模块 用于序列化的模块 json,用于字符串 和 python数据类型间进行转换 Json模块提供了四个功能:dumps.dump.loads.load #!/usr/bin/env pyt ...
- python模块(json和pickle模块)
json和pickle模块,两个都是用于序列化的模块 • json模块,用于字符串与python数据类型之间的转换 • pickle模块,用于python特有类型与python数据类型之间的转换 两个 ...
- python学习之day5,装饰器,生成器,迭代器,json,pickle
1.装饰器 import os import time def auth(type): def timeer(func): def inner(*args,**kwargs): start = tim ...
- Python序列化之json与pickle
1.json介绍 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式. 易于人阅读和编写.同时也易于机器解析和生成. 它基于JavaScript Progra ...
- python序列化模块json和pickle
序列化相关 1. json 应用场景: json模块主要用于处理json格式的数据,可以将json格式的数据转化为python的字典,便于python处理,同时也可以将python的字典或列表等对象转 ...
- python 序列化之JSON和pickle详解
JSON模块 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.它基于ECMAScript的一个子集. JSON采用完全独立于语言的文本格式,但是也使用了类 ...
- Python常用模块 (2) (loging、configparser、json、pickle、subprocess)
logging 简单应用 将日志打印到屏幕 import logging logging.debug('debug message') logging.info('info message') log ...
随机推荐
- EntityFramework学习
本文档主要介绍.NET开发中两项新技术,.NET平台语言中的语言集成查询技术 - LINQ,与ADO.NET中新增的数据访问层设计技术ADO.NET Entity Framework.ADO.NET的 ...
- access的逻辑类型
Alter TABLE [表名] ADD [新增字段] BOOLEAN或者Alter TABLE [表名] ADD [新增字段] YESNO 或者Alter TABLE [表名] ADD [新增字段] ...
- C迷途指针
在计算机编程领域中,迷途指针,或称悬空指针.野指针,指的是不指向任何合法的对象的指针. 当所指向的对象被释放或者收回,但是对该指针没有作任何的修改,以至于该指针仍旧指向已经回收的内存地址,此情况下该指 ...
- C语言柔性数组
结构中最后一个元素允许是未知大小的数组,这个数组就是柔性数组.但结构中的柔性数组前面必须至少一个其他成员,柔性数组成员允许结构中包含一个大小可变的数组,sizeof返回的这种结构大小不包括柔性数组的内 ...
- Android开发, 如何看logcat
有如下log: android.view.InflateException: Binary XML file line #2: Error inflating class com.hankkin. ...
- KVC实现原理简介
KVC,全称:Key-Value-Coding. KVC运用了isa-swizzling技术.isa-swizzling就是类型混合指针机制.KVC主要通过isa-swizzling来实现其内部定位查 ...
- App开发流程之数据持久化和编译静态链接库
先记录数据持久化. iOS客户端提供的常用数据持久化方案:NSUserDefaults代表的用户设置,NSKeydArchiver代表的归档,plist文件存储,SQLite数据库(包括上层使用的Co ...
- 基础学习day01--JAVA入门和JDK的安装与配置
一.软件是什么 软件按照一定顺序组成的计算机指令和数据集合. 二.什么是软件开发 软件开发是使用计算机的语言制作的软件.如迅雷,Windows系统,Linux,QQ等. 三.DOS常用命令 cd..: ...
- Mac 下使用sourcetree操作git教程
SourceTree 是 Windows 和Mac OS X 下免费的 Git 和 Hg 客户端,同时也是Mercurial和Subversion版本控制系统工具.支持创建.克隆.提交.push.pu ...
- Jmeter组件执行顺序与作用域
一.Jmeter重要组件: 1)配置元件---Config Element: 用于初始化默认值和变量,以便后续采样器使用.配置元件大其作用域的初始阶段处理,配置元件仅对其所在的测试树分支有效,如,在同 ...