JVM 学习笔记(五)
前言:
前面的文件介绍了JVM的内存模型以及各个区域存放了那些内容,本编文章将介绍JVM中的垃圾回收Garbage Collector,和大家一起探讨一下。
如何确定一个对象是垃圾:
这里介绍两种方法:
引用计数法
可达性分析
垃圾回收算法:
标记-清除(Mark-Sweep)
标记
找出内存中需要回收的对象,并且把它们标记出来。此时堆中所有的对象都会被扫描一遍,从而才能确定需要回收的对象,比较耗时。
如图:绿色的区域表示当前存活的对象,灰色表示垃圾对象,白色表示没有用到的内存碎片。

2. 清除
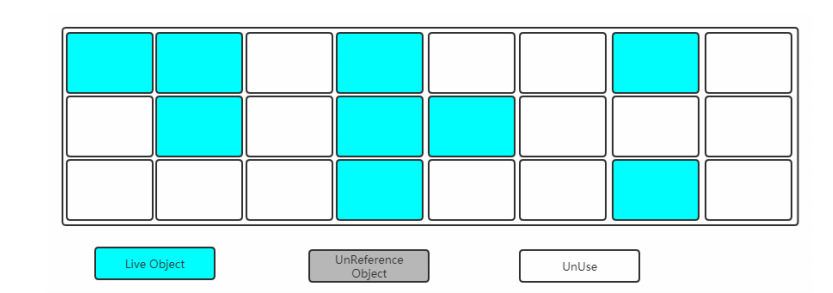
有以下缺点:
复制(Copying)
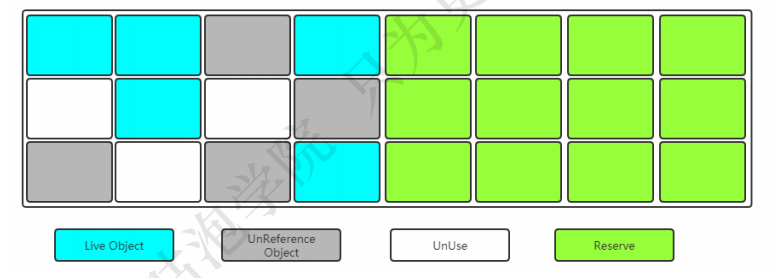
当其中一块内存使用完了,就将还存活的对象复制到另外一块上面,然后把已经使用过的内存空间一次清除掉。
下图的清理过后的内存模型:
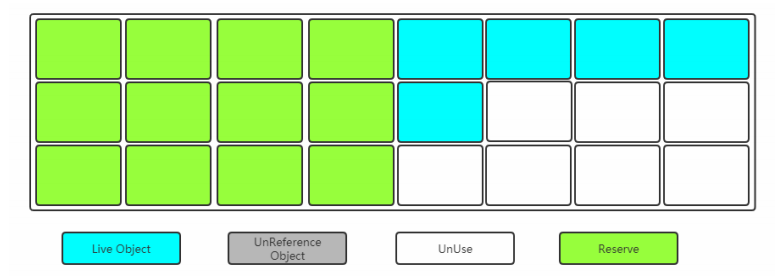
缺点:
因为这种方法保留的两个大小一样的内存区域,而同一时刻只会用到其中的一个,所以该方法内存的空间利用率比较低。
标记-整理(Mark-Compact)
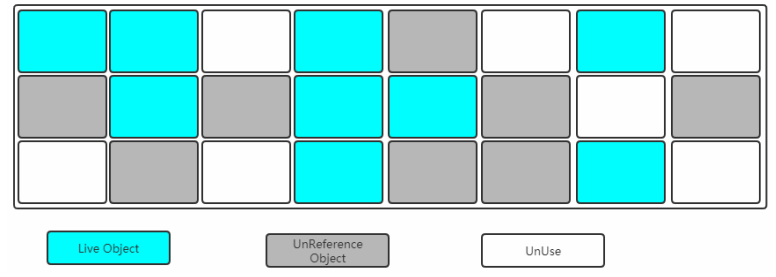
下图是整理阶段,该阶段会将被标记的区域清除,并把存活的对象往一端移动,这样内存区域就会连续化,不会有空间碎片。
分代收集算法:
垃圾收集器的介绍:
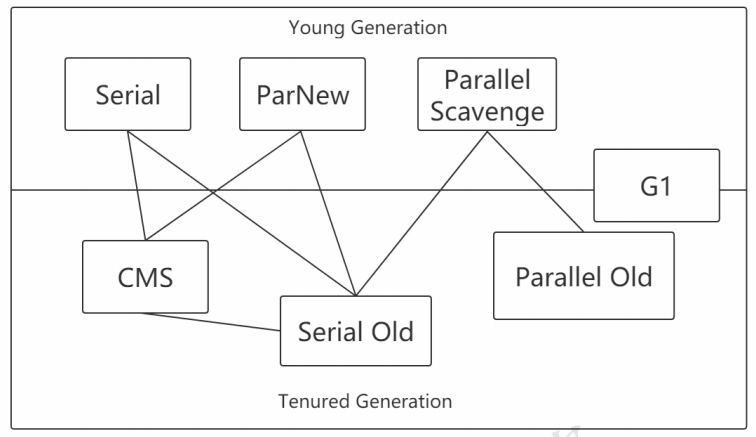
下面来介绍这几种垃圾收集器:
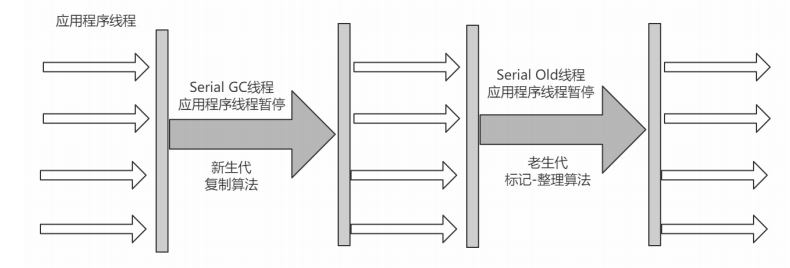
1.Serial收集器
优点:简单高效,拥有很高的单线程收集效率
缺点:收集过程需要暂停所有线程
算法:复制算法
适用范围:新生代
应用:Client模式下的默认新生代收集器
下图是该模式下的应用线程状态图:

2. ParNew收集器
简单理解为是Serial收集器的多线程版本。
简单总结一下该收集器:
优点:在多CPU时,比Serial效率高。
缺点:收集过程暂停所有应用程序线程,单CPU时比Serial效率差。
算法:复制算法
适用范围:新生代
应用:运行在Server模式下的虚拟机中首选的新生代收集器
3. Parallel Scavenge收集器
这里解释一下什么是吞吐量:
4. Serial Old收集器
下图是该模式下的应用线程状态图:
5. Parallel Old收集器
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和"标记-整理算法"进行垃圾回收。
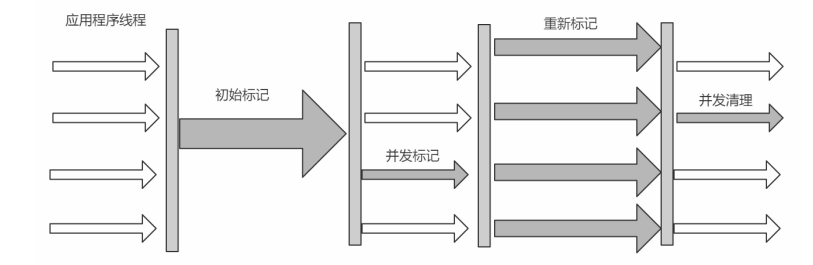
6. CMS收集器
7. G1收集器
G1 (Garbage-First)是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足GC停顿时间要求的同时,还具备高吞吐量性能特征. 在Oracle JDK 7 update 4 及以上版本中得到完全支持, 专为以下应用程序设计:
- 可以像CMS收集器一样,GC操作与应用的线程一起并发执行
- 紧凑的空闲内存区间且没有很长的GC停顿时间.
- 需要可预测的GC暂停耗时.
- 不想牺牲太多吞吐量性能.
- 启动后不需要请求更大的Java堆.
G1的长期目标是取代CMS(Concurrent Mark-Sweep Collector, 并发标记-清除). 因为特性的不同使G1成为比CMS更好的解决方案. 一个区别是,G1是一款压缩型的收集器.G1通过有效的压缩完全避免了对细微空闲内存空间的分配,不用依赖于regions,这不仅大大简化了收集器,而且还消除了潜在的内存碎片问题。除压缩以外,G1的垃圾收集停顿也比CMS容易估计,也允许用户自定义所希望的停顿参数(pause targets)
归纳总结一下G1收集器的特点:
1.并行与并发
2.分代收集(仍然保留了分代的概念)
3.空间整合(整体上属于“标记-整理”算法,不会导致空间碎片)
4.可预测的停顿(比CMS更先进的地方在于能让使用者明确指定一个长度为M毫秒的时间片段内,消耗在垃圾收集 上的时间不得超过N毫秒)。
初始标记(Initial Marking) 标记一下GC Roots能够关联的对象,并且修改TAMS的值,需要暂 停用户线程
并发标记(Concurrent Marking) 从GC Roots进行可达性分析,找出存活的对象,与用户线程并发 执行
最终标记(Final Marking) 修正在并发标记阶段因为用户程序的并发执行导致变动的数据,需 暂停用户线程
筛选回收(Live Data Counting and Evacuation) 对各个Region的回收价值和成本进行排序,根据 用户所期望的GC停顿时间制定回收计划
垃圾收集器分类:
串行收集器->Serial和Serial Old
并行收集器[吞吐量优先]->Parallel Scanvenge、Parallel Old
并发收集器[停顿时间优先]->CMS、G1
理解吞吐量和停顿时间:
如何选择合适的垃圾收集器:
首先我们了解一下官网是如何建议的:

简单翻译一下就是:
1.优先调整堆的大小让服务器自己来选择
2.如果内存小于100M,使用串行收集器
3.如果是单核,并且没有停顿时间要求,使用串行或JVM自己选
4.如果允许停顿时间超过1秒,选择并行或JVM自己选
5.如果响应时间最重要,并且不能超过1秒,使用并发收集器
JVM 学习笔记(五)的更多相关文章
- java之jvm学习笔记五(实践写自己的类装载器)
java之jvm学习笔记五(实践写自己的类装载器) 课程源码:http://download.csdn.net/detail/yfqnihao/4866501 前面第三和第四节我们一直在强调一句话,类 ...
- java jvm学习笔记五(实践自己写的类装载器)
欢迎装载请说明出处:http://blog.csdn.net/yfqnihao 课程源码:http://download.csdn.net/detail/yfqnihao/4866501 前面第三和 ...
- JVM学习笔记五:虚拟机类加载机制
类加载生命周期 类加载生命周期:加载.验证.准备.解析.初始化.使用.卸载 类加载或初始化过程什么时候开始? 遇到new.getstatic.putstatic或invokestatic这4条字节码指 ...
- java之jvm学习笔记六-十二(实践写自己的安全管理器)(jar包的代码认证和签名) (实践对jar包的代码签名) (策略文件)(策略和保护域) (访问控制器) (访问控制器的栈校验机制) (jvm基本结构)
java之jvm学习笔记六(实践写自己的安全管理器) 安全管理器SecurityManager里设计的内容实在是非常的庞大,它的核心方法就是checkPerssiom这个方法里又调用 AccessCo ...
- java之jvm学习笔记十三(jvm基本结构)
java之jvm学习笔记十三(jvm基本结构) 这一节,主要来学习jvm的基本结构,也就是概述.说是概述,内容很多,而且概念量也很大,不过关于概念方面,你不用担心,我完全有信心,让概念在你的脑子里变成 ...
- JVM学习笔记-第六章-类文件结构
JVM学习笔记-第六章-类文件结构 6.3 Class类文件的结构 本章中,笔者只是通俗地将任意一个有效的类或接口锁应当满足的格式称为"Class文件格式",实际上它完全不需要以磁 ...
- JVM学习笔记-第七章-虚拟机类加载机制
JVM学习笔记-第七章-虚拟机类加载机制 7.1 概述 Java虚拟机描述类的数据从Class文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这个过程被 ...
- JVM学习笔记——垃圾回收篇
JVM学习笔记--垃圾回收篇 在本系列内容中我们会对JVM做一个系统的学习,本片将会介绍JVM的垃圾回收部分 我们会分为以下几部分进行介绍: 判断垃圾回收对象 垃圾回收算法 分代垃圾回收 垃圾回收器 ...
- JVM学习笔记——类加载和字节码技术篇
JVM学习笔记--类加载和字节码技术篇 在本系列内容中我们会对JVM做一个系统的学习,本片将会介绍JVM的类加载和字节码技术部分 我们会分为以下几部分进行介绍: 类文件结构 字节码指令 编译期处理 类 ...
- C#可扩展编程之MEF学习笔记(五):MEF高级进阶
好久没有写博客了,今天抽空继续写MEF系列的文章.有园友提出这种系列的文章要做个目录,看起来方便,所以就抽空做了一个,放到每篇文章的最后. 前面四篇讲了MEF的基础知识,学完了前四篇,MEF中比较常用 ...
随机推荐
- qt程序添加文件版本号
1.需要一个 *.rc 文件,用以保存相关信息.比如添加一个 app.rc 里面内容如下所示: IDI_ICON1 ICON DISCARDABLE "app.ico" ----- ...
- ASP.NET Core Blazor WebAssembly 之 .NET JavaScript互调
Blazor WebAssembly可以在浏览器上跑C#代码,但是很多时候显然还是需要跟JavaScript打交道.比如操作dom,当然跟angular.vue一样不提倡直接操作dom:比如浏览器的后 ...
- Iterable对象
''' 我们已经知道,可以直接作用于for循环的数据类型有以下几种: 一类是集合数据类型,如list.tuple.dict.set.str等: 一类是generator,包括生成器和带yield的ge ...
- 图解MySQL索引(三)—如何正确使用索引?
MySQL使用了B+Tree作为底层数据结构,能够实现快速高效的数据查询功能.工作中可怕的是没有建立索引,比这更可怕的是建好了索引又没有使用到.本文将围绕着如何优雅的使用索引,图文并茂地和大家一起探讨 ...
- Java容器面试总结
1.List,Set,Map三者的区别? List:用于存储一个有序元素的集合. Set:用于存储一组不重复的元素. Map:使用键值对存储.Map会维护与Key有关联的值.两个Key可以引用相同的对 ...
- Jmeter系列(26)- 详解 JSON 提取器
果你想从头学习Jmeter,可以看看这个系列的文章哦 https://www.cnblogs.com/poloyy/category/1746599.html 为什么要用 JSON 提取器 JSON ...
- 网站搬家之mysql 5.7 date类型默认值不能设置‘0000-00-00’的问题
网站搬家,mysql版本由5.6升级到5.7,遇到问题: mysql 5.7之后版本datetime默认值设置'0000-00-00',出现异常:Invalid default value for ' ...
- sklearn机器学习算法--K近邻
K近邻 构建模型只需要保存训练数据集即可.想要对新数据点做出预测,算法会在训练数据集中找到最近的数据点,也就是它的“最近邻”. 1.K近邻分类 #第三步导入K近邻模型并实例化KN对象 from skl ...
- 入门大数据---Hive的搭建
本博客主要介绍Hive和MySql的搭建: 学习视频一天就讲完了,我看完了自己搭建MySql遇到了一堆坑,然后花了快两天才解决完,终于把MySql搭建好了.然后又去搭建Hive,又遇到了很多坑,就这 ...
- 入门大数据---Hbase搭建
环境介绍 tuge1 tuge2 tuge3 tuge4 NameNode NameNode DataNode DataNode ZooKeeper ZooKeeper ZooKeeper ZooKe ...