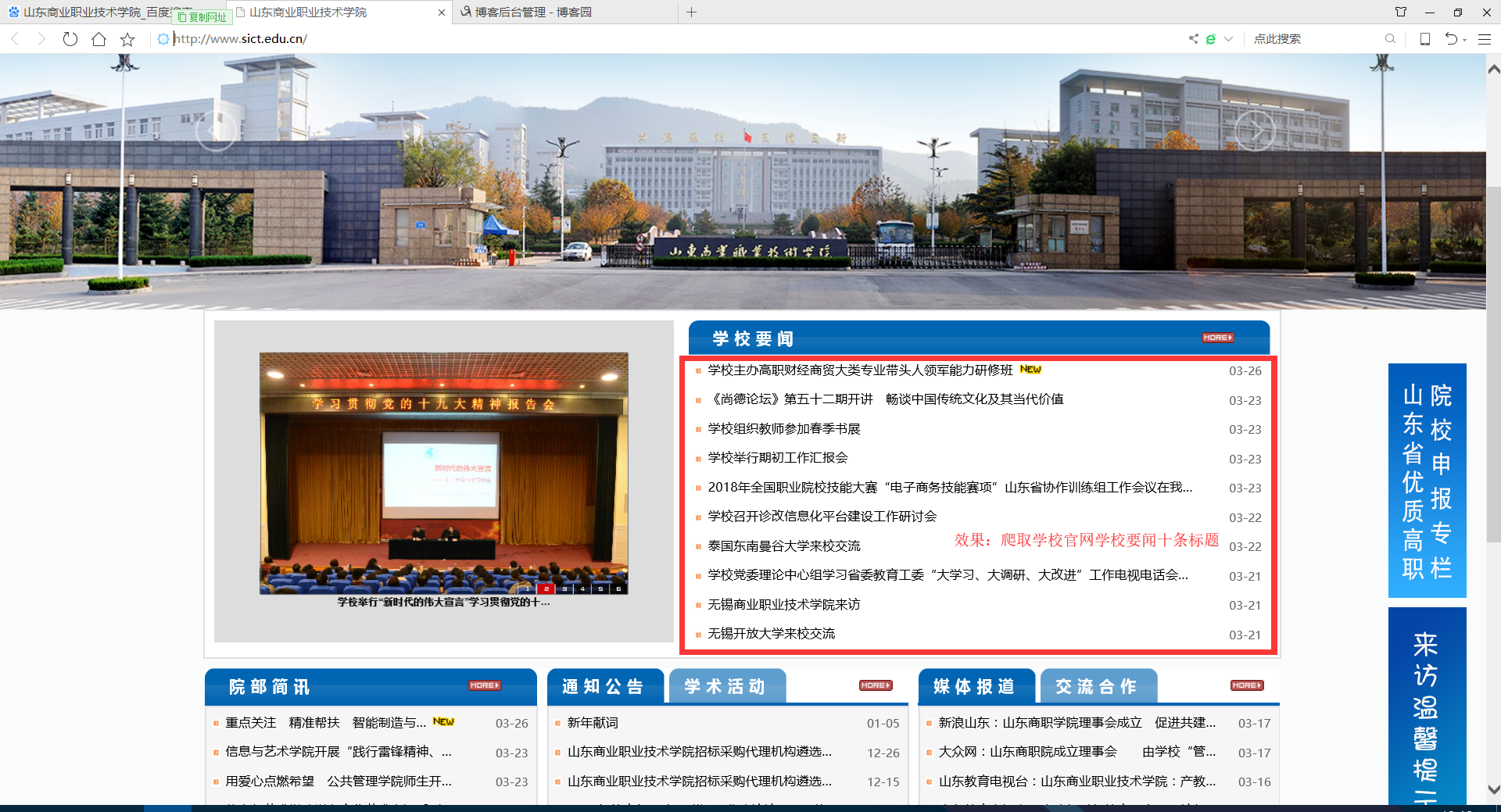
利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题
案例代码:
# __author : "J"
# date : 2018-03-06 # 导入需要用到的库文件
import urllib.request
import re
import pymysql # 创建一个类用于获取学校官网的十条标题
class GetNewsTitle: # 构造函数 初始化
def __init__(self):
self.request = urllib.request.Request("http://www.sict.edu.cn/") # 需要爬取的网址
# 利用正则表达式筛选数据
self.my_re = re.compile(
r'学校要闻.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'"a2" >(.*?)</a>.*?' +
r'院部简讯') # 创建一个方法
def get_html(self):
try:
response = urllib.request.urlopen(self.request)
# 获取目标网页源码
my_html = response.read().decode('GB2312').replace("\r\n", "")
return my_html
except urllib.request.HTTPError as e:
print(e.code)
print(e.reason)
return # 创建一个函数,利用正则获取指定标题
def get_titles(self, my_html):
news_titles = re.findall(self.my_re, my_html)
return news_titles # 创建一个方法,把获取到的标题存入mysql数据库
def into_mysql(self, titles):
for num in range(10):
connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='******', db='school',
charset='utf8')
cursor = connection.cursor()
sql = "INSERT INTO `newsTitles` (`title`) VALUES ('" + titles[0][num] + "')"
cursor.execute(sql)
connection.commit()
cursor.close()
connection.close() # 执行函数的入口
def start(self):
self.into_mysql(self.get_titles(self.get_html()))
print("存储成功!") # 实例化类
s = GetNewsTitle()
# 调用方法开始执行
s.start()
效果:

利用Python网络爬虫爬取学校官网十条标题的更多相关文章
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例
前几天给大家分享了利用Python网络爬虫抓取微信朋友圈的动态(上)和利用Python网络爬虫爬取微信朋友圈动态——附代码(下),并且对抓取到的数据进行了Python词云和wordart可视化,感兴趣 ...
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
- 利用Python网络爬虫抓取微信好友的所在省位和城市分布及其可视化
前几天给大家分享了如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,感兴趣的小伙伴可以点击链接进行查看.今天小编给大家介绍如何利用Python网络爬虫抓取微信好友的省位和城市,并且将 ...
- 利用Python网络爬虫抓取微信好友的签名及其可视化展示
前几天给大家分享了如何利用Python词云和wordart可视化工具对朋友圈数据进行可视化,利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,以及利用Python网络爬虫抓取微信好友的所 ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- Python网络爬虫-爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库 url=https://s.weibo.com/top/summary?Refer=top_hot&topnav=1& ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
- python网络爬虫&&爬取网易云音乐
#爬取网易云音乐 url="https://music.163.com/discover/toplist" #歌单连接地址 url2 = 'http://music.163.com ...
随机推荐
- 2018牛客网暑期ACM多校训练营(第一场) J - Different Integers - [莫队算法]
题目链接:https://www.nowcoder.com/acm/contest/139/J 题目描述 Given a sequence of integers a1, a2, ..., an a ...
- POJ 1273 - Drainage Ditches - [最大流模板题] - [EK算法模板][Dinic算法模板 - 邻接表型]
题目链接:http://poj.org/problem?id=1273 Time Limit: 1000MS Memory Limit: 10000K Description Every time i ...
- Oracle备份恢复之断电导致控制文件和日志文件损坏修复
Oracle数据库遭遇断电遭遇ora-00214.ora-00314.ora-00312错误恢复案例一枚 1.数据库在17日21:19启动开始报错ora-214错误: Tue Jan 17 21:19 ...
- 做一个完整的Java Web项目需要掌握的技能[转]
转自:http://blog.csdn.net/JasonLiuLJX/article/details/51494048 最近自己做了几个Java Web项目,有公司的商业项目,也有个人做着玩的小项目 ...
- AWTK 全称为 Toolkit AnyWhere,是 ZLG 倾心打造的一套基于 C 语言开发的 GUI 框架(三平台+2个手机平台+嵌入式)
最终目标: 支持开发嵌入式软件. 支持开发Linux应用程序. 支持开发MacOS应用程序. 支持开发Windows应用程序. 支持开发Android应用程序. 支持开发iOS应用程序. 支持开发2D ...
- Python开发【笔记】:what?进程queue还能生产出线程!
进程queue底层用线程传输数据 import threading import multiprocessing def main(): queue = multiprocessing.Queue() ...
- 借用HTML5 插入视频。音频
HTML5 规定了一种通过 video 元素来包含视频的标准方法. 插入视频 <video width="320" height="240" contro ...
- Bug笔记:Google Map第一次缩放位置偏移
这是个让人蛋疼的bug,认真查看Google maps API文档的童鞋们一定不会碰到. 我的同事为项目写了个针对map这块的jQuery plugin,然后在项目测试中发现,刚加载完页面时,直接点击 ...
- hdu2159FATE(二维背包)
http://acm.hdu.edu.cn/showproblem.php?pid=2159 Problem Description 最近xhd正在玩一款叫做FATE的游戏,为了得到极品装备,xhd在 ...
- data.frame和matrix的一些操作
编写脚本的时候经常会涉及到对data.frame或matrix类型数据的操作,比如取指定列.取指定行.排除指定列或行.根据条件取满足条件的列或行等.在R中,这些操作都是可以通过简单的一条语句就能够实现 ...