Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林
随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果。
导入标准程序库
随机森林的诱因: 决策树
随机森林是建立在决策树 基础上 的集成学习器
建一颗决策树
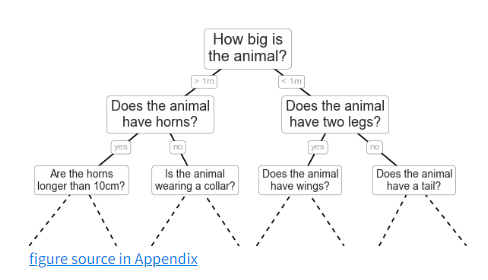
二叉决策树
在一颗合理的决策书中。每个问题基本上都可将种类的可能性减半。
决策树的难点在于如何设计每一步的问题。
- 创建一颗决策树
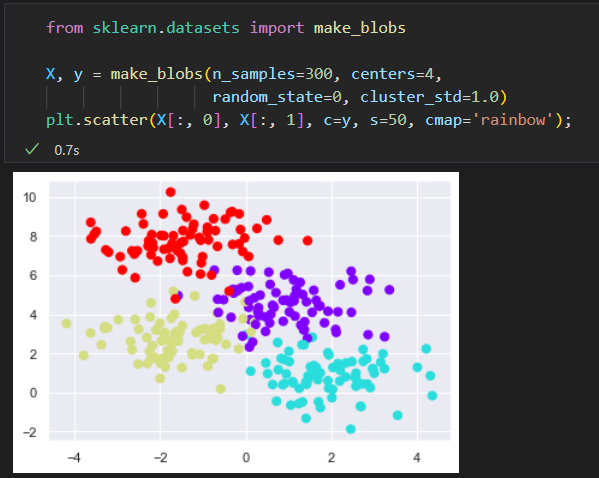
原始数据: 四种标签
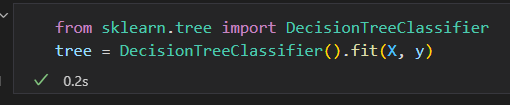
使用DecisionTreeClassifier评估器
辅助函数,分类器结果可视化
检查决策树分类的结果
在深度为5的时候,在黄色与蓝色区域中间有一个浅紫色区域,这显然不是根据数据本身的分布情况生成的正确分类结果,
而更像是一个特殊的数据样本或数据噪音 形成的干扰结果。 也就是数据出现了 过拟合
- 决策树和过拟合
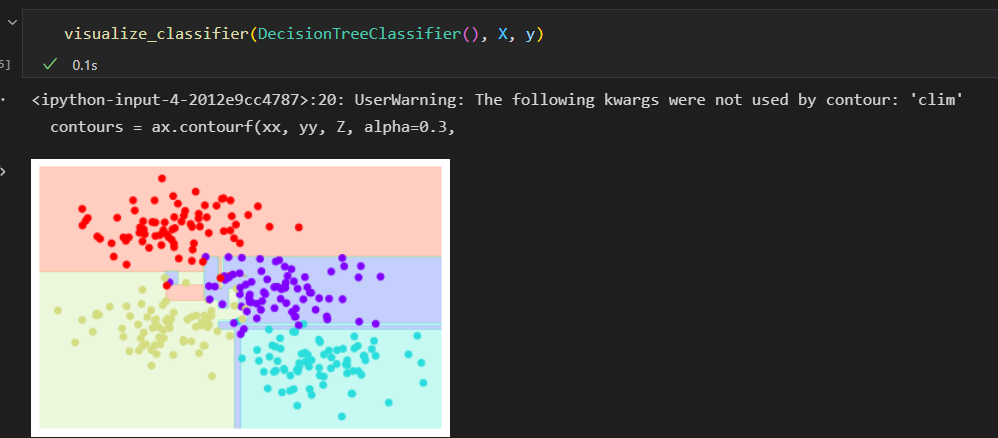
训练俩颗不同的决策树,每颗树拟合一半数据。
在一些区域,俩颗树产生了一致的结果,将俩颗树的结果组合起来。会获得更好的结果
评估器集成算法: 随机森林
通过组合多个过拟合评估器来降低过拟合 成都的想法其实是一种集成学习方法,称为装袋算法。
每个评估器都对数据过拟合,通过求均值可以获得更好的分类结果。
随机决策树的集成算法 就是 随机森林
使用BaggingClassifier元评估器来实现这种装袋分类器
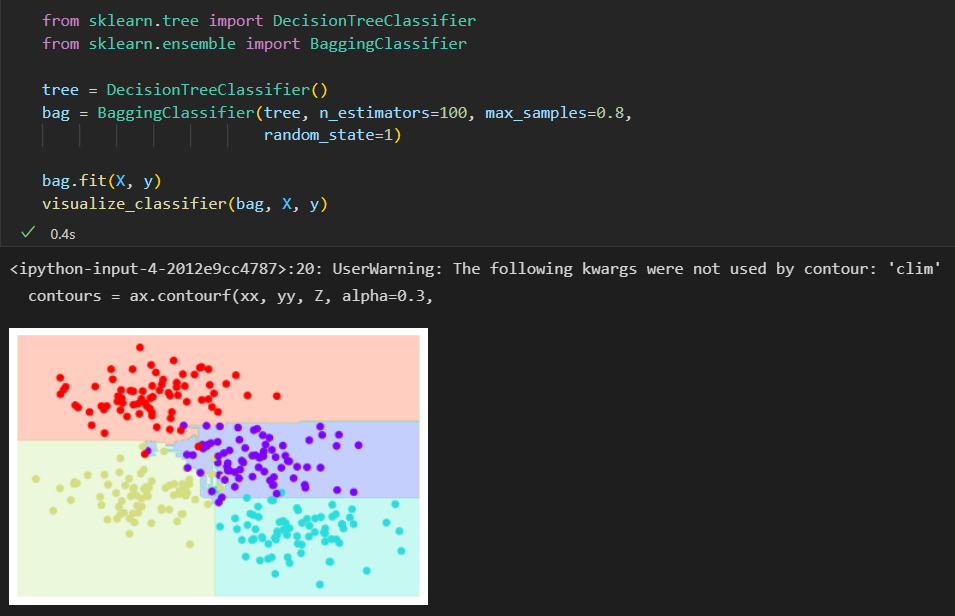
每个评估器拟合样本80%的随机数, 其实如果我们用随机方法确定数据的分割方式,决策树拟合的随机性会更有型。 这样可以让所有数据在每次训练时都被拟合,但拟合的结果 却仍然是随机的。
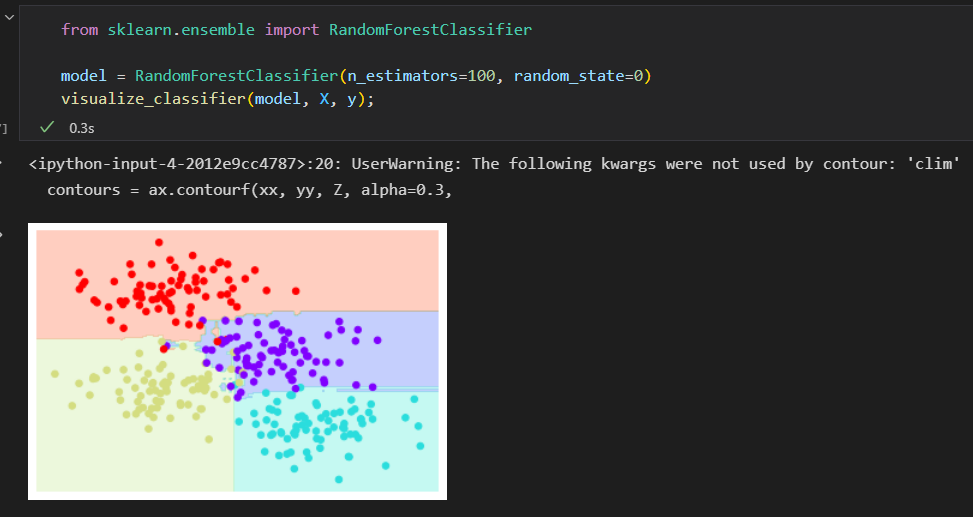
使用RandomForestClassifier评估器,会自动进行随机化决策。
随机森林回归
随机森林可以用作回归,处理连续变量,不是离散变量。
评估器是 RandomForestRegressor .
原始数据:快慢震荡组合
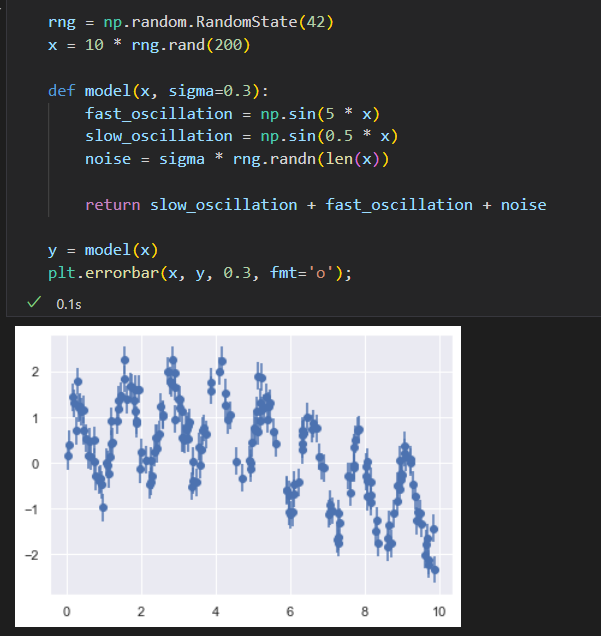
使用随机森林回归器,可以获得下面的最佳拟合曲线
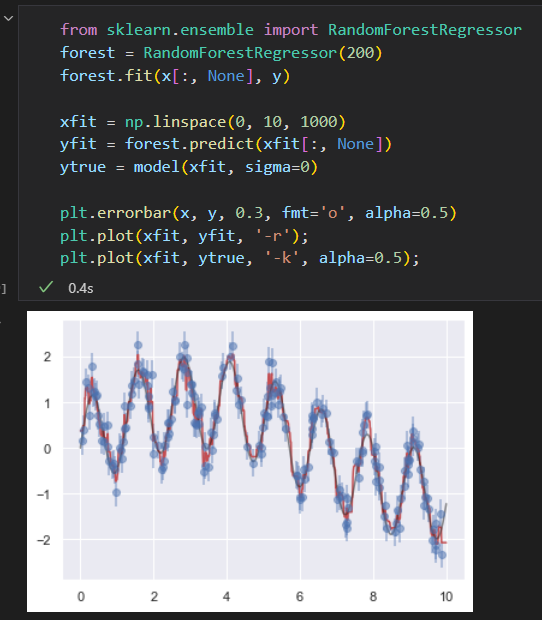
真实模型是平滑曲线。随机森林模型是锯齿线,
案例:用随机森林识别手写数字

用随机森林快速对数字进行分类
查看分类报告
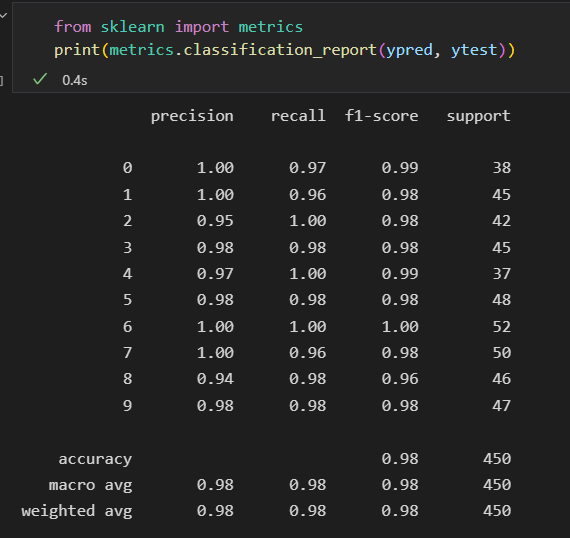
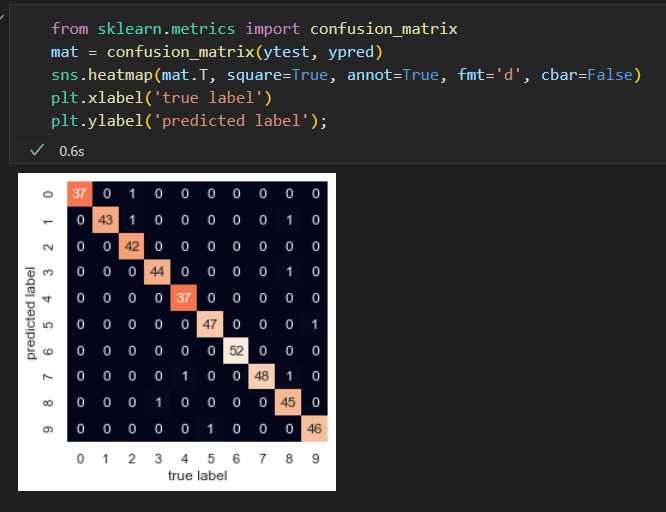
混淆矩阵
Python数据科学手册-机器学习: 决策树与随机森林的更多相关文章
- Python数据科学手册-机器学习:朴素贝叶斯分类
朴素贝叶斯模型 朴素贝叶斯模型是一组非常简单快速的分类方法,通常适用于维度非常高的数据集.因为运行速度快,可调参数少.是一个快速粗糙的分类基本方案. naive Bayes classifiers 贝 ...
- Python数据科学手册-机器学习介绍
机器学习分为俩类: 有监督学习 supervised learning 和 无监督学习 unsupervised learning 有监督学习: 对数据的若干特征与若干标签之间 的关联性 进行建模的过 ...
- Python数据科学手册-机器学习: 支持向量机
support vector machine SVM 是非常强大. 灵活的有监督学习算法, 可以用于分类和回归. 贝叶斯分类器,对每个类进行了随机分布的假设,用生成的模型估计 新数据点 的标签.是属于 ...
- Python数据科学手册-机器学习: k-means聚类/高斯混合模型
前面学习的无监督学习模型:降维 另一种无监督学习模型:聚类算法. 聚类算法直接冲数据的内在性质中学习最优的划分结果或者确定离散标签类型. 最简单最容易理解的聚类算法可能是 k-means聚类算法了. ...
- Python数据科学手册-机器学习: 流形学习
PCA对非线性的数据集处理效果不太好. 另一种方法 流形学习 manifold learning 是一种无监督评估器,试图将一个低维度流形嵌入到一个高纬度 空间来描述数据集 . 类似 一张纸 (二维) ...
- Python数据科学手册-机器学习: 主成分分析
PCA principal component analysis 主成分分析是一个快速灵活的数据降维无监督方法, 可视化一个包含200个数据点的二维数据集 x 和 y有线性关系,无监督学习希望探索x值 ...
- Python数据科学手册-机器学习:线性回归
朴素贝叶斯是解决分类任务的好起点,线性回归是解决回归任务的好起点. 简单线性回归 将数据拟合成一条直线. y = ax + b , a 是斜率, b是直线截距 原始数据如下: 使用LinearRegr ...
- Python数据科学手册-机器学习之特征工程
特征工程常见示例: 分类数据.文本.图像. 还有提高模型复杂度的 衍生特征 和 处理 缺失数据的填充 方法.这个过程被叫做向量化.把任意格式的数据 转换成具有良好特性的向量形式. 分类特征 比如房屋数 ...
- Python数据科学手册-机器学习之模型验证
模型验证 model validation 就是在选择 模型 和 超参数 之后.通过对训练数据进行学习.对比模型对 已知 数据的预测值和实际值 的差异. 错误的模型验证方法. 用同一套数据训练 和 评 ...
随机推荐
- 719. 找出第 K 小的数对距离
719. 找出第 K 小的数对距离 这道题其实有那么一点二分猜答案的意思,也有很多类似题目,只不过这道题确实表达的不是很清晰不容易想到,题没问题,我的问题.既然是猜答案,那么二分边界自然就是距离最大值 ...
- PostgreSQL的查询技巧: 零除, GENERATED STORED, COUNT DISTINCT, JOIN和数组LIKE
零除的处理 用NULLIF(col, 0)可以避免复杂的WHEN...CASE判断, 例如 ROUND(COUNT(view_50.amount_in)::NUMERIC / NULLIF(COUNT ...
- 【python】自动更新pu口袋校园活动
[python]自动更新pu口袋校园活动 脚本目标: 1. 自动爬取pu口袋校园活动,筛选出需要的活动,此处我的筛选条件是线上活动,因为可以不用去就可以白嫖学时 2. 自动发送邮件到QQ邮箱,每次只发 ...
- java geteway 手机返回数据
import lombok.extern.slf4j.Slf4j; import org.reactivestreams.Publisher; import org.springframework.c ...
- AOV网的实现(数据结构)
#include <stdio.h> #include <stdlib.h> #include <string.h>//我这里的头以及尾巴与书上的不一样. int ...
- AtCoder Beginner Contest 261 F // 树状数组
题目链接:F - Sorting Color Balls (atcoder.jp) 题意: 有n个球,球有颜色和数字.对相邻的两球进行交换时,若颜色不同,需要花费1的代价.求将球排成数字不降的顺序,所 ...
- 常用的函数式接口_Function接口练习_自定义函数模型拼接
package com.yang.Test.FunctionStudy; import java.util.function.Function; /** * 练习:自定义函数模型拼接 * 题目: * ...
- 表单中设置了 `keyup.enter.native` 的按键事件,但是回车后没有执行查询,反而会刷新页面
场景 添加属性对话框中,input输入后点击 enter,不会执行绑定的 handleDialogQuery 事件,反而会刷新整个页面: 如果不点击 enter,点击搜索按钮,则是正常的. 又测试:在 ...
- BACnet MS/TP转MQTT网关金鸽BL103
BACnet MS/TP转MQTT网关金鸽BL103BL103是一款BACnet路由器,实现 BACnet MS/TP 总线和以太网 BACnetIP 之间通信路由功能,同时也是一款Modbus RT ...
- YII地址切换
以/开头表示跳出当前控制器 例如 return $this->render('/code/login'// 跳出当前控制器,进入Code下login视图 ,['model' => $mod ...