初识python 之 爬虫:爬取某电影网站信息
注:此代码仅用于个人爱好学习使用,不涉及任何商业行为!
话不多说,直接上代码:
1 #!/user/bin env python
2 # author:Simple-Sir
3 # time:2019/7/20 20:36
4 # 获取电影天堂详细信息
5 import requests
6 from lxml import etree
7
8 # 伪装浏览器
9 HEADERS ={
10 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
11 }
12 # 定义全局变量
13 BASE_DOMAIN = 'https://www.dytt8.net'
14 # 获取首页网页信息并解析
15 def getUrlText(url,coding):
16 respons = requests.get(url,headers=HEADERS) # 获取网页信息
17 # enc = respons.encoding
18 # urlText = respons.content.decode('gbk')
19 if(coding=='c'):
20 urlText = respons.content.decode('gbk')
21 html = etree.HTML(urlText) # 使用lxml解析网页
22 else:
23 urlText = respons.text
24 html = etree.HTML(urlText) # 使用lxml解析网页
25 return html
26
27 # 获取电影详情页的href,text解析
28 def getHref(url):
29 html = getUrlText(url,'t')
30 aHref = html.xpath('//table[@class="tbspan"]//a/@href')
31 htmlAll = map(lambda url:BASE_DOMAIN+url,aHref) # 给每个href补充BASE_DOMAIN
32 return htmlAll
33
34 # 使用content解析电影详情页,并获取详细信息数据
35 def getPage(url):
36 html = getUrlText(url,'c')
37 moveInfo = {} # 定义电影信息字典
38 mName = html.xpath('//div[@class="title_all"]//font[@color="#07519a"]/text()')[0]
39 moveInfo['电影名字'] = mName
40 mDiv = html.xpath('//div[@id="Zoom"]')[0]
41 mImgSrc = mDiv.xpath('.//img/@src')
42 moveInfo['海报地址'] = mImgSrc[0] # 获取海报src地址
43 if len(mImgSrc) >= 2:
44 moveInfo['电影截图地址'] = mImgSrc[1] # 获取电影截图src地址
45 mContnent = mDiv.xpath('.//text()')
46 def pares_info(info,rule):
47 '''
48 :param info: 字符串
49 :param rule: 替换字串
50 :return: 指定字符串替换为空,并剔除左右空格
51 '''
52 return info.replace(rule,'').strip()
53 for index,t in enumerate(mContnent):
54 if t.startswith('◎译 名'):
55 name = pares_info(t,'◎译 名')
56 moveInfo['译名']=name
57 elif t.startswith('◎片 名'):
58 name = pares_info(t,'◎片 名')
59 moveInfo['片名']=name
60 elif t.startswith('◎年 代'):
61 name = pares_info(t,'◎年 代')
62 moveInfo['年代']=name
63 elif t.startswith('◎产 地'):
64 name = pares_info(t,'◎产 地')
65 moveInfo['产地']=name
66 elif t.startswith('◎类 别'):
67 name = pares_info(t,'◎类 别')
68 moveInfo['类别']=name
69 elif t.startswith('◎语 言'):
70 name = pares_info(t,'◎语 言')
71 moveInfo['语言']=name
72 elif t.startswith('◎字 幕'):
73 name = pares_info(t,'◎字 幕')
74 moveInfo['字幕']=name
75 elif t.startswith('◎上映日期'):
76 name = pares_info(t,'◎上映日期')
77 moveInfo['上映日期']=name
78 elif t.startswith('◎IMDb评分'):
79 name = pares_info(t,'◎IMDb评分')
80 moveInfo['IMDb评分']=name
81 elif t.startswith('◎豆瓣评分'):
82 name = pares_info(t,'◎豆瓣评分')
83 moveInfo['豆瓣评分']=name
84 elif t.startswith('◎文件格式'):
85 name = pares_info(t,'◎文件格式')
86 moveInfo['文件格式']=name
87 elif t.startswith('◎视频尺寸'):
88 name = pares_info(t,'◎视频尺寸')
89 moveInfo['视频尺寸']=name
90 elif t.startswith('◎文件大小'):
91 name = pares_info(t,'◎文件大小')
92 moveInfo['文件大小']=name
93 elif t.startswith('◎片 长'):
94 name = pares_info(t,'◎片 长')
95 moveInfo['片长']=name
96 elif t.startswith('◎导 演'):
97 name = pares_info(t,'◎导 演')
98 moveInfo['导演']=name
99 elif t.startswith('◎编 剧'):
100 name = pares_info(t, '◎编 剧')
101 writers = [name]
102 for i in range(index + 1, len(mContnent)):
103 writer = mContnent[i].strip()
104 if writer.startswith('◎'):
105 break
106 writers.append(writer)
107 moveInfo['编剧'] = writers
108 elif t.startswith('◎主 演'):
109 name = pares_info(t, '◎主 演')
110 actors = [name]
111 for i in range(index+1,len(mContnent)):
112 actor = mContnent[i].strip()
113 if actor.startswith('◎'):
114 break
115 actors.append(actor)
116 moveInfo['主演'] = actors
117 elif t.startswith('◎标 签'):
118 name = pares_info(t,'◎标 签')
119 moveInfo['标签']=name
120 elif t.startswith('◎简 介'):
121 name = pares_info(t,'◎简 介')
122 profiles = []
123 for i in range(index + 1, len(mContnent)):
124 profile = mContnent[i].strip()
125 if profile.startswith('◎获奖情况') or '【下载地址】' in profile:
126 break
127 profiles.append(profile)
128 moveInfo['简介']=profiles
129 elif t.startswith('◎获奖情况'):
130 name = pares_info(t,'◎获奖情况')
131 awards = []
132 for i in range(index + 1, len(mContnent)):
133 award = mContnent[i].strip()
134 if '【下载地址】' in award:
135 break
136 awards.append(award)
137 moveInfo['获奖情况']=awards
138 downUrl = html.xpath('//td[@bgcolor="#fdfddf"]/a/@href')[0]
139 moveInfo['下载地址'] = downUrl
140 return moveInfo
141
142 # 获取前n页所有电影的详情页href
143 def spider():
144 base_url = 'https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html'
145 moves = []
146 m = int(input('请输入您要获取的开始页:'))
147 n = int(input('请输入您要获取的结束页:'))
148 print('即将写入第{}页到第{}页的电影信息,请稍后...'.format(m, n))
149 for i in range(m,n+1):
150 print('******* 第{}页电影 正在写入 ********'.format(i))
151 url = base_url.format(i)
152 moveHref = getHref(url)
153 for index,mhref in enumerate(moveHref):
154 print('---- 第{}部电影 正在写入----'.format(index+1))
155 move = getPage(mhref)
156 moves.append(move)
157 # 将电影信息写入本地本件
158 for i in moves:
159 with open('电影天堂电影信息.txt', 'a+', encoding='utf-8') as f:
160 f.write('\n********* {} ***************\n'.format(i['电影名字']))
161 for info in i:
162 with open('电影天堂电影信息.txt','a+',encoding='utf-8') as f:
163 f.write('{}:{}\n'.format(info,i[info]))
164 print('写入完成!')
165
166 if __name__ == '__main__':
167 spider()
获取电影天堂详细信息
执行情况:
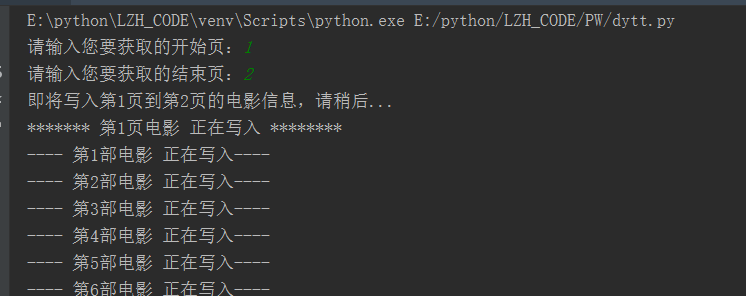

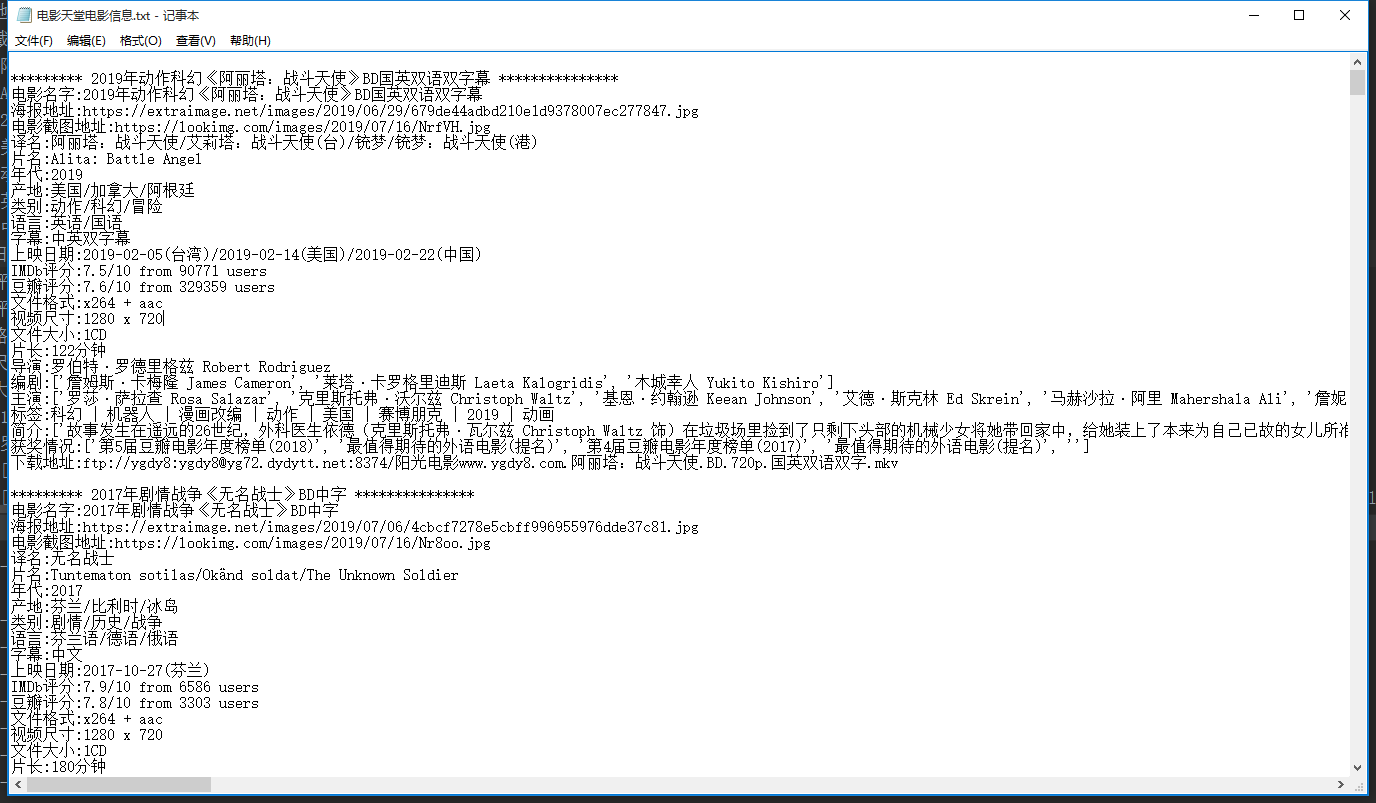
结果文件:
初识python 之 爬虫:爬取某电影网站信息的更多相关文章
- 利用python实现爬虫爬取某招聘网站,北京地区岗位名称包含某关键字的所有岗位平均月薪
#通过输入的关键字,爬取北京地区某岗位的平均月薪 # -*- coding: utf-8 -*- import re import requests import time import lxml.h ...
- python爬虫爬取ip记录网站信息并存入数据库
import requests import re import pymysql #10页 仔细观察路由 db = pymysql.connect("localhost",&quo ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
- python制作爬虫爬取京东商品评论教程
作者:蓝鲸 类型:转载 本文是继前2篇Python爬虫系列文章的后续篇,给大家介绍的是如何使用Python爬取京东商品评论信息的方法,并根据数据绘制成各种统计图表,非常的细致,有需要的小伙伴可以参考下 ...
随机推荐
- numpy基础教程--浅拷贝和深拷贝
在numpy中,使用等号(=)直接赋值返回的是一个视图,属于浅拷贝:要完整的拷贝一个numpy.ndarray类型的数据的话,只能调用copy()函数 # coding = utf-8 import ...
- uWSGI和WSGI之间的关系
一.WSGI 协议 WSGI:是一种协议规范,起到规范参数的作用,就像告诉公路一样,规定超车靠右行,速度不低于90km/h,等.但这一切都是对双方进行沟通,比如,重庆到武汉这条高速路,这儿重庆和武汉就 ...
- android 基于dex的插件化开发
安卓里边可以用DexClassLoader实现动态加载dex文件,通过访问dex文件访问dex中封装的方法,如果dex文件本身还调用了native方法,也就间接实现了runtime调用native方法 ...
- CF31A Worms Evolution 题解
Content 有一个长度为 \(n\) 的数组 \(a_1,a_2,a_3,...,a_n\),试找出一个三元组 \((i,j,k)\),使得 \(a_i=a_j+a_k\). 数据范围:\(3\l ...
- linux安装软件系列之yum安装
自动搜索最快镜像插件: yum install yum-fastestmirror 安装yum图形窗口插件: yum install yumex 1.安装 yum install 全部安装 yum i ...
- JAVA实现office文档(word、excel、ppt等)、压缩包在线预览,支持禁止下载功能、支持PC和手机
我们使用的是永中的第三方服务.支持直接转换文档的线上地址,也可以直接把文档上传到官方服务器上 官方文档地址:https://www.yozodcs.com/page/help.html#link152 ...
- nim_duilib(14)之xml配置半透明窗体控件不透明
before starting note 截至目前,我只能用xml写一些简单的布局和设置控件属性,循序渐进吧. 正在学习nim_duilib的xml的一些属性. xml配置半透明 GTAV中就有很多控 ...
- 【九度OJ】题目1441:人见人爱 A ^ B 解题报告
[九度OJ]题目1441:人见人爱 A ^ B 解题报告 标签(空格分隔): 九度OJ 原题地址:http://ac.jobdu.com/problem.php?pid=1441 题目描述: 求A^B ...
- 【LeetCode】274. H-Index 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址: https://leetcode.com/problems/h-index/ ...
- 【剑指Offer】连续子数组的最大和 解题报告(Python)
[剑指Offer]连续子数组的最大和 解题报告(Python) 标签(空格分隔): 剑指Offer 题目地址:https://www.nowcoder.com/ta/coding-interviews ...