利用Python进行数据分析_Pandas_处理缺失数据
申明:本系列文章是自己在学习《利用Python进行数据分析》这本书的过程中,为了方便后期自己巩固知识而整理。
1 读取excel数据
import pandas as pd
import numpy as np
file = 'D:\example.xls'
df = pd.DataFrame(pd.read_excel(file))
df

2 检测缺失值
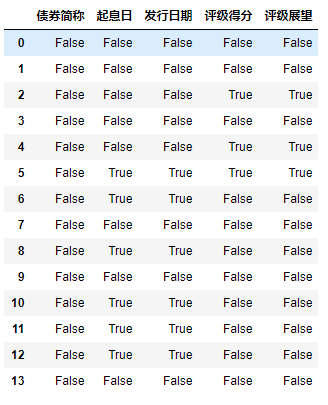
2.1 isnull返回一个含有布尔值的对象
import pandas as pd
import numpy as np
file = 'D:\example.xls'
df = pd.DataFrame(pd.read_excel(file))
df = df.isnull()
df
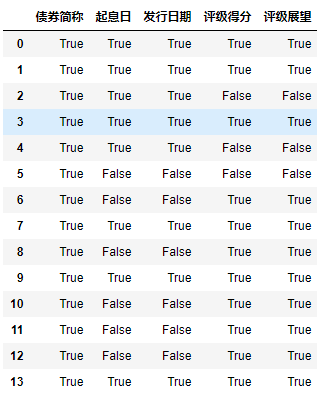
2.2 notnull 是isnull 的否定式
import pandas as pd
import numpy as np
file = 'D:\example.xls'
df = pd.DataFrame(pd.read_excel(file))
df = df.notnull()
df
3 滤除缺失数据
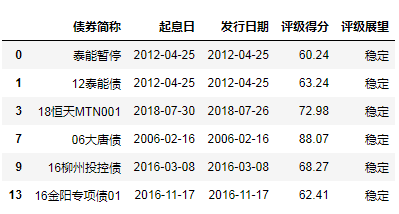
3.1 滤除所有包含缺失值的行
df.dropna()
3.2 查看不含缺失值的所有行、列
df.dropna(thresh=4)

4 填充缺失数据
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
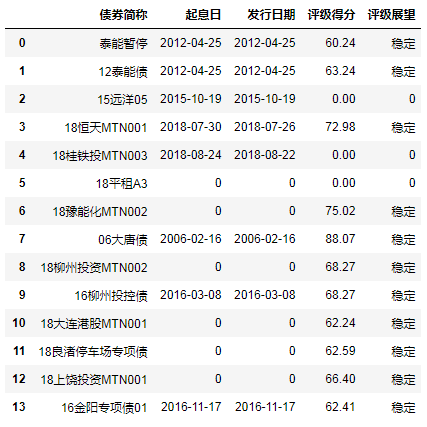
4.1 统一填充某一个值value
df.fillna(0)或df.fillna(value=0)
4.2 用前面的值填充缺失部分
df.fillna(method='ffill')
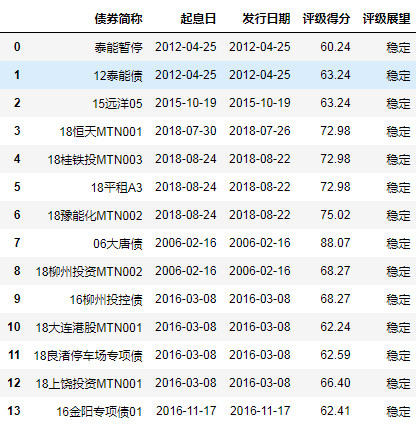
4.3 用后面的值填充缺失部分
df.fillna(method='bfill')
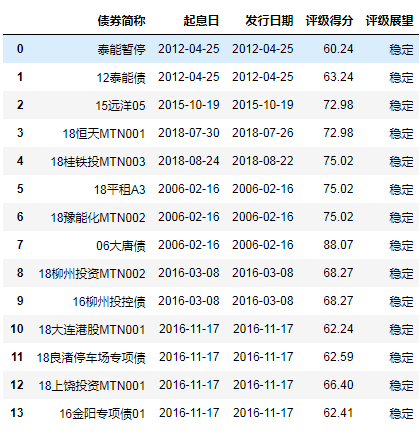
4.3 某N列用特定的值填充缺失部分
df.fillna({'起息日':'2018-12-11','评级得分':''})
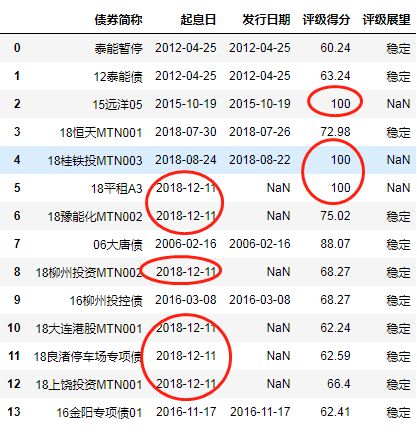
4.4 指定一整个轴的值填充缺失部分
df.fillna(method='ffill',axis=1)

利用Python进行数据分析_Pandas_处理缺失数据的更多相关文章
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析_Pandas_数据加载、存储与文件格式
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 1 pandas读取文件的解析函数 read_csv 读取带分隔符的数据,默认 ...
- 利用Python进行数据分析_Pandas_基本功能
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 第一 重新索引 Series的reindex方法 In [15]: obj = ...
- 利用Python进行数据分析_Pandas_数据结构
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 首先,需要导入pandas库的Series和DataFrame In [21] ...
- 利用Python进行数据分析_Pandas_层次化索引
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 层次化索引主要解决低纬度形式处理高纬度数据的问题 import pandas ...
- 利用Python进行数据分析_Pandas_汇总和计算描述统计
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. In [1]: import numpy as np In [2]: impo ...
- 利用Python进行数据分析_Pandas_数据清理、转换、合并、重塑
1 合并数据集 pandas.merge pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, le ...
- 利用Python进行数据分析 第6章 数据加载、存储与文件格式(2)
6.2 二进制数据格式 实现数据的高效二进制格式存储最简单的办法之一,是使用Python内置的pickle序列化. pandas对象都有一个用于将数据以pickle格式保存到磁盘上的to_pickle ...
- 利用Python进行数据分析 第8章 数据规整:聚合、合并和重塑.md
学习时间:2019/11/03 周日晚上23点半开始,计划1110学完 学习目标:Page218-249,共32页:目标6天学完(按每页20min.每天1小时/每天3页,需10天) 实际反馈:实际XX ...
随机推荐
- ZR#997
ZR#997 解法: 找找规律就出来了,全场最简单的一道题. CODE: #include<iostream> #include<cstdio> #include<cst ...
- Hbase 错误记录分析(1) region超时问题
错误现象: 默认等待时间是60秒,超过这个时间就报超时问题了.因此需调整超时时间,默认为60秒,在配置文件 hbase-site.xml中: 调整成10分钟 <property> & ...
- 数据库——JavaWEB数据库连接
一.数据库连接的发展 1.数据库连接 用户每次请求都需要向数据库获得链接,而数据库创建连接通常需要消耗相对较大的资源,创建时间也较长.假设网站一天10万访问量,数据库服务器就需要创建10万次连接,极大 ...
- IntelliJ IDEA 2017.3 配置Tomcat运行web项目教程(多图)
小白一枚,借鉴了好多人的博客,然后自己总结了一些图,尽量的详细.在配置的过程中,有许多疑问.如果读者看到后能给我解答的,请留言.Idea请各位自己安装好,还需要安装Maven和Tomcat,各自配置好 ...
- JSP(工作原理,组成部分,指令标签,动作标签,隐式对象)
目录 JSP JSP 什么是JSP JSP全名为Java Server Pages 中文名叫java服务器页面 它是在传统的网页HTML文件(.htm,.html)中插入Java程序段和JSP标记 后 ...
- SSH 三大框架整合
Spring整合web项目 在Servlet当中直接加载配置文件,获取对象 存在问题 每次请求都会创建一个Spring的工厂,这样浪费服务器资源,应该一个项目只有一个Spring的工厂. 在服务器启动 ...
- js 检测链接是否有效(包含跨域)
const checkUrl = function (url) { const promise = new Promise(function (resolve, reject) { if (!url) ...
- 环境初始化 Build and Install the Apache Thrift IDL Compiler Install the Platform Development Tools
Apache Thrift - Centos 6.5 Install http://thrift.apache.org/docs/install/centos Building Apache Thri ...
- 批量转换Excel转CSV文件
本文为Excel VBA代码,可以实现将某一文件夹内的Excel文件(xls或者xlsx)另存为“逗号分隔的csv文件”. 使用条件: 1. Windows系统: 2. 已安装 MS 2007或以 ...
- 前端表格插件datatables
下载datatables datatables官网:https://www.datatables.net/ datatables下载地址:https://www.datatables.net/down ...