吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets,ensemble
from sklearn.model_selection import train_test_split def load_data_classification():
'''
加载用于分类问题的数据集
'''
# 使用 scikit-learn 自带的 digits 数据集
digits=datasets.load_digits()
# 分层采样拆分成训练集和测试集,测试集大小为原始数据集大小的 1/4
return train_test_split(digits.data,digits.target,test_size=0.25,random_state=0,stratify=digits.target) #集成学习AdaBoost算法分类模型
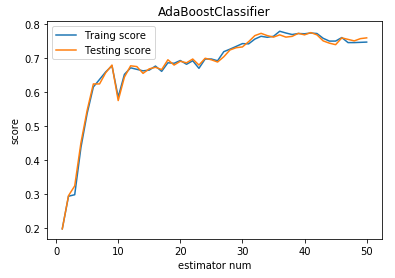
def test_AdaBoostClassifier(*data):
'''
测试 AdaBoostClassifier 的用法,绘制 AdaBoostClassifier 的预测性能随基础分类器数量的影响
'''
X_train,X_test,y_train,y_test=data
clf=ensemble.AdaBoostClassifier(learning_rate=0.1)
clf.fit(X_train,y_train)
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
estimators_num=len(clf.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(clf.staged_score(X_train,y_train)),label="Traing score")
ax.plot(list(X),list(clf.staged_score(X_test,y_test)),label="Testing score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="best")
ax.set_title("AdaBoostClassifier")
plt.show() # 获取分类数据
X_train,X_test,y_train,y_test=load_data_classification()
# 调用 test_AdaBoostClassifier
test_AdaBoostClassifier(X_train,X_test,y_train,y_test)
def test_AdaBoostClassifier_base_classifier(*data):
'''
测试 AdaBoostClassifier 的预测性能随基础分类器数量和基础分类器的类型的影响
'''
from sklearn.naive_bayes import GaussianNB X_train,X_test,y_train,y_test=data
fig=plt.figure()
ax=fig.add_subplot(2,1,1)
########### 默认的个体分类器 #############
clf=ensemble.AdaBoostClassifier(learning_rate=0.1)
clf.fit(X_train,y_train)
## 绘图
estimators_num=len(clf.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(clf.staged_score(X_train,y_train)),label="Traing score")
ax.plot(list(X),list(clf.staged_score(X_test,y_test)),label="Testing score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1)
ax.set_title("AdaBoostClassifier with Decision Tree")
####### Gaussian Naive Bayes 个体分类器 ########
ax=fig.add_subplot(2,1,2)
clf=ensemble.AdaBoostClassifier(learning_rate=0.1,base_estimator=GaussianNB())
clf.fit(X_train,y_train)
## 绘图
estimators_num=len(clf.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(clf.staged_score(X_train,y_train)),label="Traing score")
ax.plot(list(X),list(clf.staged_score(X_test,y_test)),label="Testing score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1)
ax.set_title("AdaBoostClassifier with Gaussian Naive Bayes")
plt.show() # 调用 test_AdaBoostClassifier_base_classifier
test_AdaBoostClassifier_base_classifier(X_train,X_test,y_train,y_test)

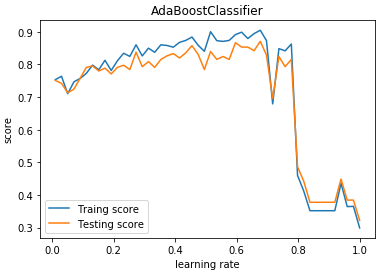
def test_AdaBoostClassifier_learning_rate(*data):
'''
测试 AdaBoostClassifier 的预测性能随学习率的影响
'''
X_train,X_test,y_train,y_test=data
learning_rates=np.linspace(0.01,1)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
traing_scores=[]
testing_scores=[]
for learning_rate in learning_rates:
clf=ensemble.AdaBoostClassifier(learning_rate=learning_rate,n_estimators=500)
clf.fit(X_train,y_train)
traing_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(learning_rates,traing_scores,label="Traing score")
ax.plot(learning_rates,testing_scores,label="Testing score")
ax.set_xlabel("learning rate")
ax.set_ylabel("score")
ax.legend(loc="best")
ax.set_title("AdaBoostClassifier")
plt.show() # 调用 test_AdaBoostClassifier_learning_rate
test_AdaBoostClassifier_learning_rate(X_train,X_test,y_train,y_test)
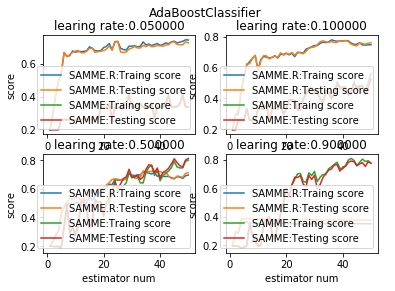
def test_AdaBoostClassifier_algorithm(*data):
'''
测试 AdaBoostClassifier 的预测性能随学习率和 algorithm 参数的影响
'''
X_train,X_test,y_train,y_test=data
algorithms=['SAMME.R','SAMME']
fig=plt.figure()
learning_rates=[0.05,0.1,0.5,0.9]
for i,learning_rate in enumerate(learning_rates):
ax=fig.add_subplot(2,2,i+1)
for i ,algorithm in enumerate(algorithms):
clf=ensemble.AdaBoostClassifier(learning_rate=learning_rate,algorithm=algorithm)
clf.fit(X_train,y_train)
## 绘图
estimators_num=len(clf.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(clf.staged_score(X_train,y_train)),label="%s:Traing score"%algorithms[i])
ax.plot(list(X),list(clf.staged_score(X_test,y_test)),label="%s:Testing score"%algorithms[i])
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_title("learing rate:%f"%learning_rate)
fig.suptitle("AdaBoostClassifier")
plt.show() # 调用 test_AdaBoostClassifier_algorithm
test_AdaBoostClassifier_algorithm(X_train,X_test,y_train,y_test)
吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型的更多相关文章
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——人工神经网络与原始感知机模型
import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D from ...
- 吴裕雄 python 机器学习——等度量映射Isomap降维模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多维缩放降维MDS模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多项式贝叶斯分类器MultinomialNB模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from skl ...
- 吴裕雄 python 机器学习——数据预处理二元化OneHotEncoder模型
from sklearn.preprocessing import OneHotEncoder #数据预处理二元化OneHotEncoder模型 def test_OneHotEncoder(): X ...
随机推荐
- MongoDB geonear和文本命令驱动程序2.0
文本查询,q作为查询字符串: coll.FindAsync<Foo>(Builders<Foo>.Filter.Text(q)); 文本查询需要一个文本索引.要从C#创建代码, ...
- 备份Sql Server中的某些表
第一步:右键需要备份表的数据库 第二步:选择=>选择特定数据库对象,在下方选择你需要备份的数据表. 第三步,点击高级,在要编写脚本的数据的类型中选择架构和数据(看个人需要),根据需要可更换生成的 ...
- jquery tagsinput监听输入、修改、删除事件
个人博客 地址:http://www.wenhaofan.com/article/20181118192458 由于度娘上的根本搜不到对应的操作,连该插件对应的文档介绍都没有,不得已debug了源码才 ...
- JVM学习-环境构建
想学习JVM,java虚拟机的底层原理.下面介绍下怎么将Java文件compiler成字节码,然后反编译为二进制查看分析. 一.JavaClass.java文件: package com.gqz.ja ...
- 二分-B - Dating with girls(1)
B - Dating with girls(1) Everyone in the HDU knows that the number of boys is larger than the number ...
- 如来十三掌-关于不断解密的密码学,佛语解密,rot-13(根据13掌),base64
得到MzkuM3gvMUAwnzuvn3cgozMlMTuvqzAenJchMUAeqzWenzEmLJW9 然后尝试嘛 base64不太行 那根据十三掌??rot-13 得到ZmxhZ3tiZHNj ...
- OpenCV3+VS2015 经常出现debug error abort()has been called问题
方案1:图片路径错误:查看imread的路径
- Entry小部件:
导入tkinter import Tkinter from Tinter import * import tkinter from tinter import * 实例化Tk类 root=tkinte ...
- 【Python】浮点数用科学计数法表示
- codeforces 1269D. Domino for Young (二分图证明/结论题)
链接:https://codeforces.com/contest/1269/problem/D 题意:给一个不规则的网格,在上面放置多米诺骨牌,多米诺骨牌长度要么是1x2,要么是2x1大小,问最多放 ...