爬虫(三)之scrapy核心组件
01-核心组件
·五大核心组件的工作流程:
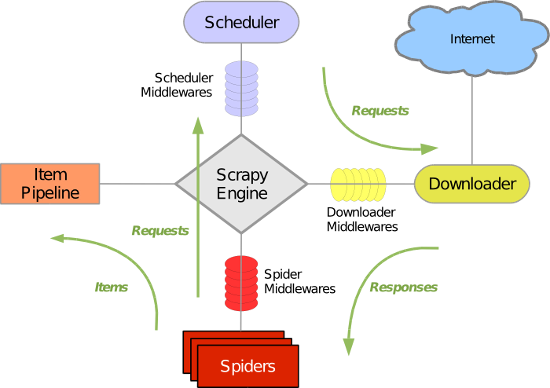
引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
02-post请求
# postPro/postPro/spiders/postDemo.py # -*- coding: utf-8 -*-
import scrapy
# 需求:百度翻译中指定词条对应的翻译结果进行获取 class PostdemoSpider(scrapy.Spider):
name = 'postDemo'
# allowed_domains = ['www.baidu.com']
start_urls = ['https://fanyi.baidu.com/sug']
# start_requests 该方法其实是父类中的一个方法:该方法可以对 start_urls 列表中的元素进行get请求的发送
# 发起post请求的方式:① 将Request 方法中method参数赋值成post(不建议);② FormRequest()可以发起post请求(推荐)
# 要想发起post请求,一定要对父类中的 start_requests 进行重写。 def start_requests(self):
print("执行了start_requests")
# post的请求参数
data = {
'kw': 'dog',
}
for url in self.start_urls:
# formdata: 请求参数对应的字典
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse) def parse(self, response):
print(response.text)
03-cookie操作
# doubanPro/doubanPro/spiders/douban.py # -*- coding: utf-8 -*-
import scrapy class DoubanSpider(scrapy.Spider):
name = 'douban'
# allowed_domains = ['www.baidu.com']
start_urls = ['https://accounts.douban.com/login'] def start_requests(self):
data = {
"source": "index_nav",
"redir": "https: // www.douban.com/",
"form_email": "18844170520@163.com",
"form_password": "******",
"login": "登录",
}
for url in self.start_urls:
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse) def parseBySecondPage(self, response):
# 针对个人主页面数据进行解析操作
fp = open('./second.html', 'w', encoding='utf-8')
fp.write(response.text) def parse(self, response):
# 登陆成功后的页面进行存储
fp = open('./main.html', 'w', encoding='utf-8')
fp.write(response.text) # 获取当前用户的个人主页
url = 'https://www.douban.com/people/187468735/'
yield scrapy.Request(url=url, callback=self.parseBySecondPage)
04-代理
下载中间件的作用: 拦截请求, 可以将IP的请求进行更换。 流程:
1.下载中间件类的自制定
class MyProxy(object):
def process_request(self, request, spider):
# 请求IP的更换
request.meta['proxy'] = "http://120.76.77.152:9999"
2.配置文件中进行下载中间件的开启。
# proxyPro/settings.py
# 打开配置文件中的下载中间件,并配置自定义中间件
# 下载中间件
DOWNLOADER_MIDDLEWARES = {
# 'proxyPro.middlewares.ProxyproDownloaderMiddleware': 543,
'proxyPro.middlewares.MyProxy': 543,
}
# proxyPro/middlewares.py from scrapy import signals # 自定义一个下载中间件的类,在类中事先process_request(处理中间件拦截到的请求) 方法
class MyProxy(object):
def process_request(self, request, spider):
# 请求IP的更换
request.meta['proxy'] = "http://120.76.77.152:9999"
# proxyPro/proxyDemo.py # -*- coding: utf-8 -*-
import scrapy class ProxydemoSpider(scrapy.Spider):
name = 'proxyDemo'
# allowed_domains = ['www.baidu.com/s?wd=ip']
start_urls = ['http://www.baidu.com/s?wd=ip'] def parse(self, response):
fp = open('./proxy.html', 'w', encoding='utf-8')
fp.write(response.text)
05-日志等级

# settings.py # 指定终端输出日志等级
LOG_LEVEL = 'ERROR' # 把终端输出的日志信息写入到log.txt文件中
LOG_FILE = 'log.txt'
06-请求传参(meta)
解决问题:爬取的数据值不在同一个页面。
需求:将id97电影网站中的电影详情数据进行爬取
# moviePro/spiders/movie.py # -*- coding: utf-8 -*-
import scrapy
from moviePro.items import MovieproItem class MovieSpider(scrapy.Spider):
name = 'movie'
# allowed_domains = ['www.id97.com']
start_urls = ['http://www.id97.com/movie'] # 专门对二级页面进行解析
def parseBySecondPage(self, response):
# 导演
actor = response.xpath('/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[1]/td[2]/a/text()').extract_first()
# 语言
language = response.xpath('/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[6]/td[2]/text()').extract_first()
# 片长
longTime = response.xpath('/html/body/div[1]/div/div/div[1]/div[1]/div[2]/table/tbody/tr[8]/td[2]/text()').extract_first() # 取出Request 方法的meta 参数传递过来的字典(request.meta)
item = response.meta['item']
item['actor'] = actor
item['language'] = language
item['longTime'] = longTime # 将item提交给管道
yield item def parse(self, response):
# 名称,类型,导演,语言,片长
div_list = response.xpath('/html/body/div[1]/div[1]/div[2]/div') for div in div_list:
# 片名
name = div.xpath('.//div[@class="meta"]/h1/a/text()').extract_first()
# 类型 如下方法返回的是一个列表,且列表元素为4
kind = div.xpath('.//div[@class="otherinfo"]//text()').extract()
# 转化为字符串
kind = "".join(kind)
# 详情页的url
url = div.xpath('.//div[@class="meta"]/h1/a/@href').extract_first() # 创建item对象
item = MovieproItem()
item['name'] = name
item['kind'] = kind # 问题:如何将剩下的电影详情数据存储到item对象(meta参数) # 需要对url发起请求,获取页面数据,进行指定的数据解析, meta会将字典传递给回调函数
# meta 只可以赋值为 一个字典
yield scrapy.Request(url=url, callback=self.parseBySecondPage, meta={'item': item})
07-CrawlSpider

# 创建项目文件 scrapy startproject crawlSpiderPro scrapy genspider -t crawl chouti https://dig.chouti.com
# spiders/chouti.py # -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
'''
LinkExtractor : 链接提取器对应的类
LinkExtractor(allow=r'Items/') 实例化
作用:用来提取指定的url,allow参数:赋值一个正则表达式,就可以根据正则在页面中提取指定的url
提取到的链接url 会全部交给 规则解析器Rule,
Rule : 规则解析器对应的类
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
Rule 接受了 LinkExtractor 发送的链接url后,就会对链接发起请求,获取url对应的页面内容,
然后就会根据 指定的规则 对页面内容进行指定的页面解析, callback:指定了一个解析规则 parse_item(方法/函数)
follow:是否将 链接提取器 继续作用到 链接提取器提取出的链接 所表示的页面数据中
''' class ChoutiSpider(CrawlSpider):
name = 'chouti'
# allowed_domains = ['https://dig.chouti.com']
start_urls = ['https://dig.chouti.com/'] rules = (
# 实例化了一个规则解析器对象
Rule(LinkExtractor(allow=r'/all/hot/recent/\d+'), callback='parse_item', follow=True),
) def parse_item(self, response):
print(response)
# 再进行数据解析......... # i = {}
# # i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
# # i['name'] = response.xpath('//div[@id="name"]').extract()
# # i['description'] = response.xpath('//div[@id="description"]').extract()
# return i
爬虫(三)之scrapy核心组件的更多相关文章
- scrapy爬虫学习系列三:scrapy部署到scrapyhub上
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
随机推荐
- MYSQL中默认隐式事务及利用事务DML
一:默认情况下,MySQL采用autocommit模式运行.这意味着,当您执行一个用于更新(修改)表的语句之后,MySQL立刻把更新存储到磁盘中.默认级别为不可重复读. 二:会造成隐式提交的语句以下语 ...
- 转:EditPuls 5.0 注册码
EditPlus5.0注册码 注册名 Vovan 注册码 3AG46-JJ48E-CEACC-8E6EW-ECUAW EditPlus3.x注册码 EditPlus注册码生成器链接 http://ww ...
- 内核线程的进程描述符task_struct中的mm和active_mm
task_struct进程描述符中包含两个跟进程地址空间相关的字段mm, active_mm, struct task_struct { // ... struct mm_struct *mm; st ...
- scrapy中pipeline的一点综合知识
初次学习scrapy ,觉得spider代码才是最重要的,越往后学,发现pipeline中的代码也很有趣, 今天顺便把pipeline中三种储存方法写下来,算是对自己学习的一点鼓励吧,也可以为后来者的 ...
- python3+正则表达式爬取 猫眼电影
'''Request+正则表达式抓取猫眼电影TOP100内容''' import requests from requests.exceptions import RequestException i ...
- C# -- 正则表达式匹配字符之含义
C#正则表达式匹配字符之含义 1.正则表达式的作用:用来描述字符串的特征. 2.各个匹配字符的含义: . :表示除\n以外的单个字符 [ ] :表示在字符数组[]中罗列出来的字符任意取单个 | ...
- node.js cluster模式启用方式
众所周知,Node.js运行在Chrome的JavaScript运行时平台上,我们把该平台优雅地称之为V8引擎.不论是V8引擎,还是之后的Node.js,都是以单线程的方式运行的,因此,在多核心处理器 ...
- FCM算法的matlab程序
FCM算法的matlab程序 在“FCM算法的matlab程序(初步)”这篇文章中已经用matlab程序对iris数据库进行简单的实现,下面的程序最终的目的是求准确度. 作者:凯鲁嘎吉 - 博客园 h ...
- python list和tuple
list列表简介:列表是python的基础数据类型之⼀ ,其他编程语⾔也有类似的数据类型. 比如JS中的数组, java中的数组等等. 它是以[ ]括起来, 每个元素⽤' , '隔开⽽且可以存放各种数 ...
- gRPC奇怪的编译命令protoc
举个栗子: protoc -I helloworld/ helloworld/helloworld.proto --go_out=plugins=grpc:helloworld 大神说得没错,读文档就 ...