Scrapy模拟登录信息
携带cookie模拟登录
- 需要在爬虫里面自定义一个
start_requests()的函数- 里面的内容:
def start_requests(self):
cookies = '真实有效的cookie'
yield scrapy.Request(
self.start_urls[0],
callback = self.paese,
cookies = cookies
)
下载中间件
- 只需在文件最下面定义自己的中间件即可
下载中间键里可以做很多内容:携带登录信息,设置user-agent,添加代理等
- 使用前要在settings里面设置一下
- 数字代表权重
projectname.middlewares.DownloadMiddlewareName
DOWNLOADER_MIDDLEWARES = {
'superspider.middlewares.SuperspiderDownloaderMiddleware': 543,
}
- 设置user-agent
process_request
定义一个名为RandomUserAgentMiddleware的下载中间件
from fake_useragent import UserAgent
class RandomUserAgentMiddleware:
def process_request(self, request, spider):
##### 还可以为不同爬虫指定不同的中间件
if spider.name == 'spider1':
ua = UserAgent()
request.headers["User-Agent"] = ua.random
在settings里导入
DOWNLOADER_MIDDLEWARES = {
'superspider.middlewares.RandomUserAgentMiddleware': 543
}
- 审核user-agent
process_response- 需要返回response
- 在settings里导入
class UserAgentCheck:
def process_response(self, request, response, spider):
print(request.headers['User-Agent'])
return response
DOWNLOADER_MIDDLEWARES = {
'superspider.middlewares.RandomUserAgentMiddleware': 543,
'superspider.middlewares.UserAgentCheck': 544
}
- 设置代理
- 需要在request的meta信息中添加proxy字段
- 添加代理的形式:协议+IP+端口
- settings里导入
class ProxyMiddleware:
def process_request(self, request, spider):
if spider.name == 'spider0':
request.meta["proxy"] = "http://ip:port"
模拟登录GitHub
自己构造表单模拟登录 使用 FormRequest
- 明确要yield的内容,并交给下一个函数处理
# -*- coding: utf-8 -*-
import scrapy
class Spider0Spider(scrapy.Spider):
name = 'spider0'
allowed_domains = ['github.com']
start_urls = ['https://github.com/session']
def parse(self, response):
yield scrapy.FormRequest(
"https://github.com/session",
formdata=,
callback=self.after_login
)
def after_login(self, response):
pass
- formdate的构造
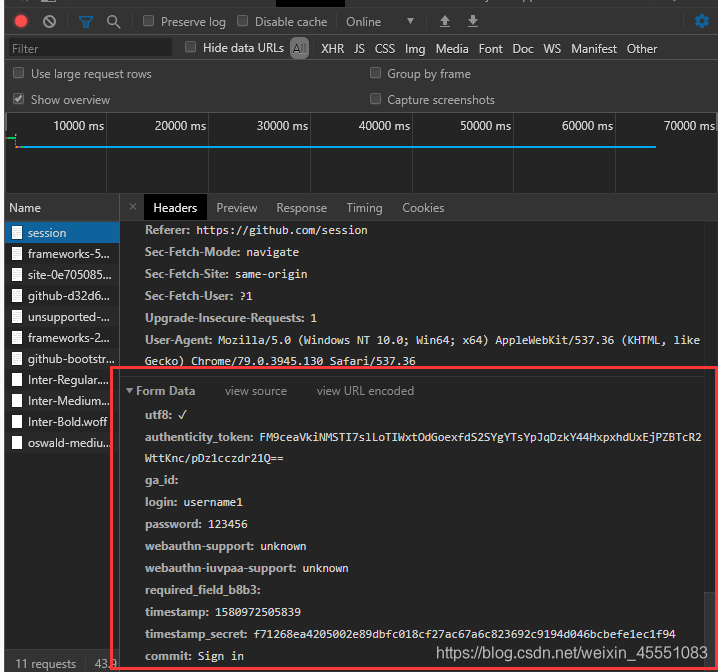
# -*- coding: utf-8 -*-
import scrapy
class Spider0Spider(scrapy.Spider):
name = 'spider0'
allowed_domains = ['github.com']
start_urls = ['https://github.com/session']
def parse(self, response):
form = {
'utf8': "✓",
'authenticity_token': response.xpath(
"//*[@id='unsupported-browser']/div/div/div[2]/form/input[2]/text()").extract_first(),
'ga_id': response.xpath('//*[@id="login"]/form/input[3]/@value').extract_first(),
'login': "",
'password': "",
'webauthn-support': 'supported',
'webauthn-iuvpaa-support': 'supported',
response.xpath('//*[@id="login"]/form/div[3]/input[5]/@name').extract_first(): "",
'timestamp': response.xpath("//*[@id='login']/form/div[3]/input[6]/@value").extract_first(),
"timestamp_secret": response.xpath("//*[@id='login'']/form/div[3]/input[7]/@value").extract_first(),
"commit": "Sign in"
}
print(form)
yield scrapy.FormRequest(
"https://github.com/session",
formdata=form,
callback=self.after_login
)
def after_login(self, response):
pass
自动寻找form表单中的信息
# -*- coding: utf-8 -*-
import scrapy
class Spider0Spider(scrapy.Spider):
name = 'spider0'
allowed_domains = ['github.com']
start_urls = ['https://github.com/session']
def parse(self, response):
yield scrapy.FormRequest.from_response(
response,
formdata={"login": "", "password":""},
callback=self.after_login
)
def after_login(self, response):
print(response.text)
Scrapy模拟登录信息的更多相关文章
- scrapy模拟登录微博
http://blog.csdn.net/pipisorry/article/details/47008981 这篇文章是介绍使用scrapy模拟登录微博,并爬取微博相关内容.关于登录流程为嘛如此设置 ...
- 利用scrapy模拟登录知乎
闲来无事,写一个模拟登录知乎的小demo. 分析网页发现:登录需要的手机号,密码,_xsrf参数,验证码 实现思路: 1.获取验证码 2.获取_xsrf 参数 3.携带参数,请求登录 验证码url : ...
- scrapy模拟登录
对于scrapy来说,也是有两个方法模拟登陆: 直接携带cookie 找到发送post请求的url地址,带上信息,发送请求 scrapy模拟登陆之携带cookie 应用场景: cookie过期时间很长 ...
- python爬虫之scrapy模拟登录
背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML.json数据,但是忽略了很多的一个问题,有很多的网站为了反爬虫,除了需要高可用代理IP地址池外,还需要登录.例如知乎 ...
- Scrapy模拟登录赶集网
1.打开赶集网登录界面,先模拟登录并抓包,获得post请求的request参数 2. 我们只需构造出上面的参数传入formdata即可 参数分析: setcookie:为自动登录所传的值,不勾选时默认 ...
- scrapy 基础组件专题(十二):scrapy 模拟登录
1. scrapy有三种方法模拟登陆 1.1直接携带cookies 1.2找url地址,发送post请求存储cookie 1.3找到对应的form表单,自动解析input标签,自动解析post请求的u ...
- Scrapy模拟登录知乎
建立项目 scrapy startproject zhihu_login scrapy genspider zhihu www.zhihu.com 编写spider 知乎的登录页url是http:// ...
- Scrapy模拟登录GitHub
d: 进入D盘 scrapy startproject GitHub 创建项目 scrapy genspider github github.com 创建爬虫 编辑github.py: # -*- c ...
- scrapy 模拟登录后再抓取
深度好文: from scrapy.contrib.spiders.init import InitSpider from scrapy.http import Request, FormReques ...
随机推荐
- Java多线程问题40个
1.多线程有什么用? 一个可能在很多人看来很扯淡的一个问题:我会用多线程就好了,还管它有什么用?在我看来,这个回答更扯淡.所谓”知其然知其所以然”,”会用”只是”知其然”,”为什么用”才是”知其所以然 ...
- P1044 栈(递归、递推、卡特兰、打表)
P1044 栈 题目背景 栈是计算机中经典的数据结构,简单的说,栈就是限制在一端进行插入删除操作的线性表. 栈有两种最重要的操作,即pop(从栈顶弹出一个元素)和push(将一个元素进栈). 栈的重要 ...
- Vertica的这些事(三)——Vertica中实现Oracle中的ws_concat功能
vertica中没有类似Oracle中的ws_concat函数功能,需要开发UDF,自己对C++不熟悉,所有只有想其他方法解决了. 上代码: SELECT node_state, MAX(DECODE ...
- 老技术新谈,Java应用监控利器JMX(2)
各位坐稳扶好,我们要开车了.不过在开车之前,我们还是例行回顾一下上期分享的要点. 上期由于架不住来自于程序员内心的灵魂的拷问,于是我们潜心修炼,与 Java 应用监控利器 JMX 正式打了个照面. J ...
- CCF题库刷题编译错误
最近在CCF上刷题,因为C语言更合适,就使用了devc编译器,选择C语言但是却报编译错误 后来查了一下,发现在提交时选择C++语言就能满分通过,问题得以解决.
- div实现富文本编辑框
ocument.execCommand()方法处理Html数据时常用语法格式如下:document.execCommand(sCommand[,交互方式, 动态参数]) 其中:sCommand为指令参 ...
- R语言—如何安装Github包的解决方法,亲测有效
R语言—如何安装Github包的解决方法,亲测有效 准备安装材料: R包-REmap GitHub下载地址:https://github.com/lchiffon/REmap R包-baidumap ...
- transaction 用tx事务 测试时 报错:Unable to locate Spring NamespaceHandler for XML schema namespace [http://www.springframework.org/schema/mvc]
Unable to locate Spring NamespaceHandler for XML schema namespace [http://www.springframework.org/sc ...
- java解惑之常常忘记的事
java解惑之常常忘记的事 2012-10-17 18:38:57| 分类: JAVA | 标签:基础知识 软件开发 |举报|字号 订阅 针对刚接触java的菜鸟来说,java基础知识 ...
- synchronized 与 volatile 区别 还有 volatile 的含义
熟悉并发的同学一定知道在java中处理并发主要有两种方式: 1,synchronized关键字,这个大家应当都各种面试和笔试中经常遇到. 2,volatile修饰符的使用,相信这个修饰符大家平时在项目 ...