python爬虫:爬取网站视频
python爬取百思不得姐网站视频:http://www.budejie.com/video/
新建一个py文件,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
#!/usr/bin/python# -*- coding: UTF-8 -*-import urllib,re,requestsimport sysreload(sys)sys.setdefaultencoding('utf-8')url_name = [] #url namedef get(): #获取源码 hd = {"User-Agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"} url = 'http://www.budejie.com/video/' html = requests.get(url,headers=hd).text url_content = re.compile(r'(<div class="j-r-list-c">.*?</div>.*?</div>)',re.S) #编译 url_contents = re.findall(url_content,html) #匹配 for i in url_contents: #匹配视频 url_reg = r'data-mp4="(.*?)"' #视频地址 url_items = re.findall(url_reg,i) #print url_items if url_items: #判断视频是否存在 name_reg = re.compile(r'<a href="/detail-.{8}?.html">(.*?)</a>',re.S) name_items = re.findall(name_reg,i) #print name_items[0] for i,k in zip(name_items,url_items): url_name.append([i,k]) print i,k for i in url_name: #i[1]=url i[0]=name urllib.urlretrieve(i[1],'video\\%s.mp4' % (i[0].decode('utf-8')))if __name__ == "__main__": get() |
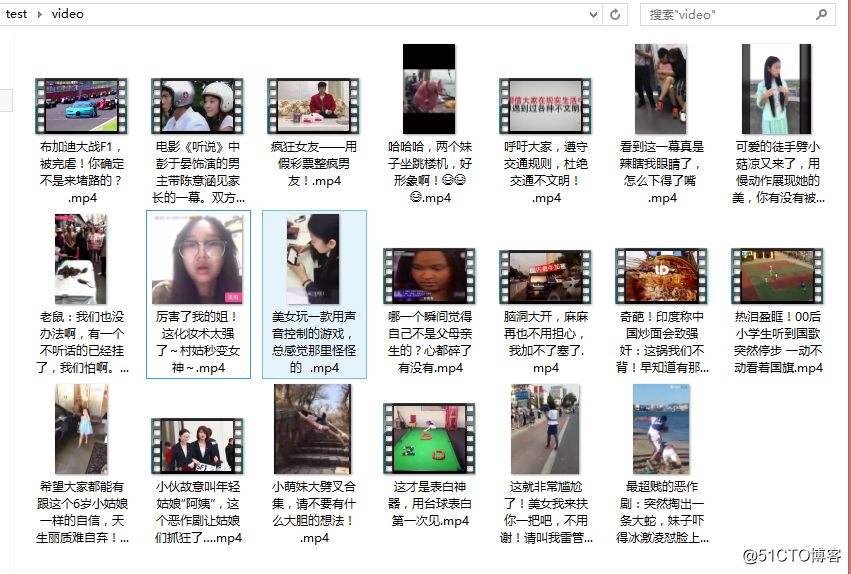
在 py 文件下新建一个 video 文件夹,执行后结果如下:
在 video 文件夹可以看到下载好的视频
注意报错:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-9: ordinal not in range(128)
解决:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
转载:http://blog.51cto.com/xiaogongju/2061754
python爬虫:爬取网站视频的更多相关文章
- Python爬虫爬取qq视频等动态网页全代码
环境:py3.4.4 32位 需要插件:selenium BeautifulSoup xlwt # coding = utf-8 from selenium import webdriverfrom ...
- 1.记我的第一次python爬虫爬取网页视频
It is my first time to public some notes on this platform, and I just want to improve myself by reco ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
随机推荐
- python兵器谱之re模块与正则表达式
一.正则表达式 ·1.正则表达式的应用场景: 应用特有的规则,给我需要的符合规则的字符串,在字符串中只有符合条件的才会被匹配和从大段的字符串中提取需要的数据 ·匹配字符串的规则: ·1.字符串:用户输 ...
- 嘿,C语言(持续更新中...)
---恢复内容开始--- 上次简单介绍了一下C语言,这次说说数据与计算程序,那么话不多说,进来看看. 第二章 数据与简单的计算程序 一:数据 既然说到了数据,那么说说什么是写数据呢? 表面意 ...
- mac下使用git的冲突的解决方案
博主之前一直是在windows系统下进行软件代码的开发,window下有很多git的使用工具,如tortoisegit等是个很好的git项目管理工具.而再mac版下的git项目代码管理工具,本人找了好 ...
- BAPIを使用のODATA作成
入力: AIRLINE テーブル: FLIGHT_LIST Step 1: TCode: SEGW ⇒新規作成ボタンを押す Step 2: オブジェクト名など入力 Step 3: オブジェクト作成完了 ...
- SpaceVim 发布 v0.8.0
This project exists thanks to all the people who have contributed. The last release v0.7.0 is target ...
- pix2code开发笔记
1.软件安装 首先需要安装Python3和pip (1) Python3 环境搭建 Window 平台安装 Python: https://www.python.org/downloads/wind ...
- zookeeper的图形化展示
1.ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件,提供 ...
- 无法嵌入互操作类型“ADOX.CatalogClass”。请改用适用的接口。
编译环境:vs2013 系统报错:无法嵌入互操作类型"ADOX.CatalogClass".请改用适用的接口. 解决方法:选中项目中引入的dll(本例中为Microsoft ADO ...
- explain获得使用的key的数据
bool Explain_join::explain_key_and_len() { if (tab->ref.key_parts) return explain_key_and_len_ind ...
- 初识c++模板元编程
模板元编程(Template metaprogramming,简称TMP)是编译器内执行的程序,编译器读入template,编译输出的结果再与其他源码一起经过普通编译过程生成目标文件.通俗来说,普通运 ...