深度学习-tensorflow学习笔记(2)-MNIST手写字体识别
深度学习-tensorflow学习笔记(2)-MNIST手写字体识别超级详细版
这是tf入门的第一个例子。minst应该是内置的数据集。
前置知识在学习笔记(1)里面讲过了
这里直接上代码
# -*- coding: utf-8 -*-
"""
Created on Fri May 25 14:09:45 2018 @author: Administrator
"""
#导入数据集
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets("MNIST_data/",one_hot=True)
#打印数据集的详情
print(mnist.train.images.shape,mnist.train.labels.shape)
print(mnist.test.images.shape,mnist.test.labels.shape)
print(mnist.validation.images.shape,mnist.validation.labels.shape)
打印结果如下
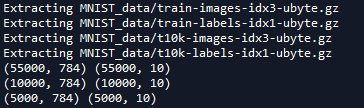
第一个是训练集的特征值和标签,第二个是测试集,第三个是验证集
MNIST数据集的特征值是28*28的
先看下一个CNN的过程
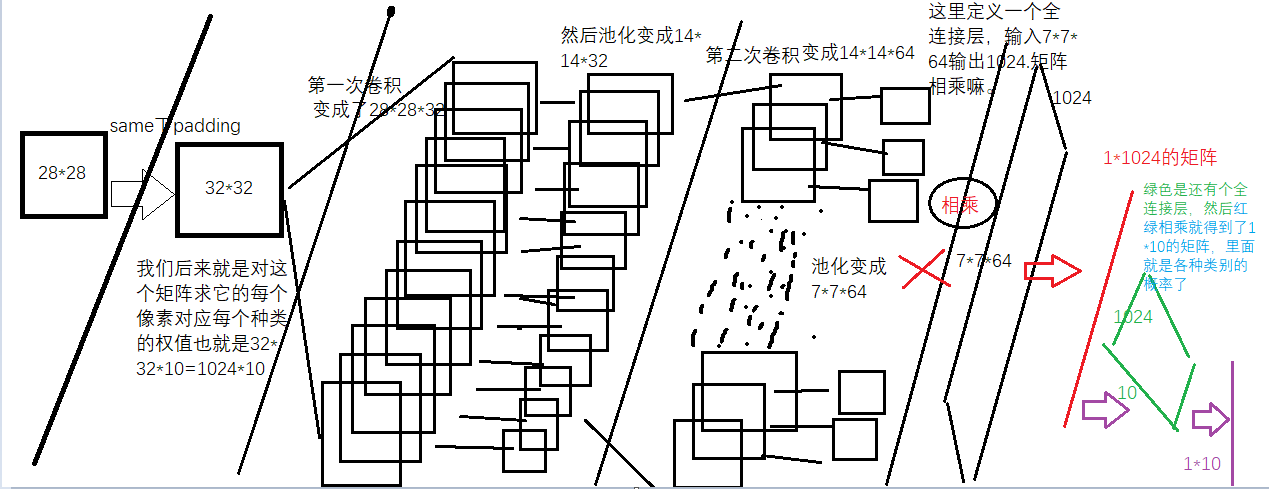
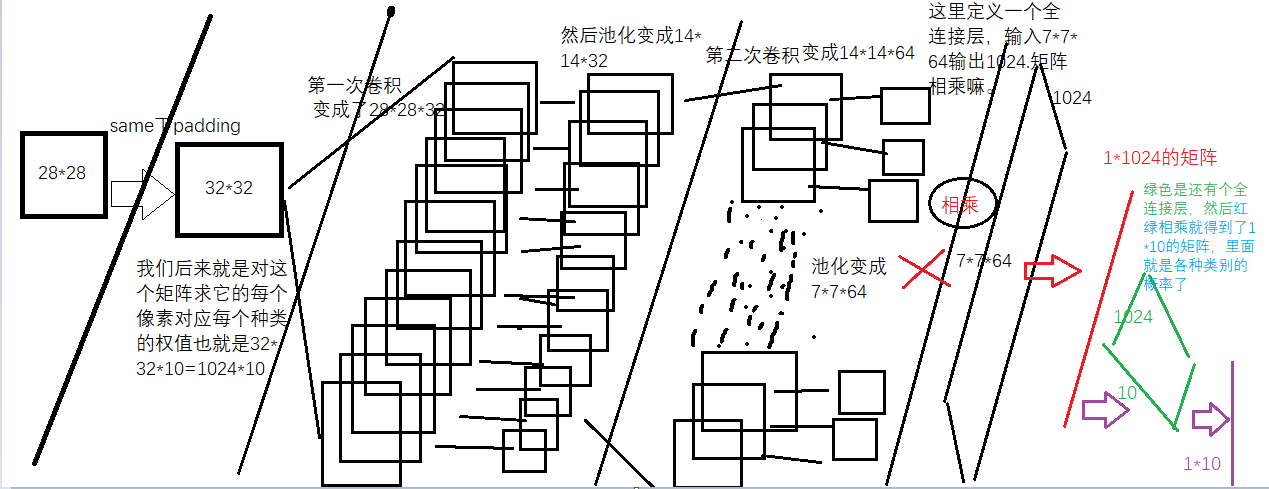
过程的文字描述如下-导入数据集-对特征值卷积-池化-激活-卷积-池化-激活-全连接-全连接-计算损失-计算精度
接下来开始通过代码讲
首先我们声明占位符-训练集特征值和标签,NONE表示自适应维度
x=tf.placeholder(tf.float32,[None,784])
#训练集真实标签
y_=tf.placeholder(tf.float32,[None,10])
导入的数据集是1*784维度的,原图像是28*28的
为了卷积运算我们把一位数据变成28*28的这里用的是tf.reshape函数
这里解释下reshape的参数,x是输入数据,[batch,weight,height,depth]
x_image=tf.reshape(x,[-1,28,28,1]
为了方便我们操作,定义了生成权重,偏置的函数
#生成权重,高斯分布,方差为0.1
def weight_variabel(shape):
initial=tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial) #生成shape大小的偏置,偏置初时为0.1
def bias_variable(shape):
initial=tf.constant(0.1,shape=shape)
return tf.Variable(initial)
另外还定义了卷积和池化的操作
'''
卷积操作
conv2d(输入图像,卷积核,在各个维度的滑动步长,SAME-or-VALID)
VALID当卷积核超出边缘了,就会直接丢弃
SAME的话会给padding 0来满足
'''
def conv2d(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME') '''
池化的输入,池化窗口大小,步长
第二个参数[batchs,height,width,channels]
返回[batch,height,width,channels]
池化方式-mean-pooling 求平均-对背景保留更好
-max-pooling 求特征点最大,对纹理保留最好
-stochastic_pooling两者之间,通过对像素点按照数值大小赋予概率
'''
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
接下来开始第一层卷积操作
这里输入参数为input=28*28 用5*5*1的32个不同的卷积核 卷积后遍历后 得到 28*28*32的图像
下面再生成32个偏置,这里的偏置应该是对图的每一个深度加的偏置
w_conv1=weight_variable([5,5,1,32])
b_conv1=bias_variable([32])
然后我们用激活函数来修正线性单元
这里用的激活函数relu
h_conv1=tf.nn.relu(conv2d(x_image,w_conv1)+b_conv1)#relu激励函数+卷积
这里执行了卷积和激励的操作-
由于是SAME所以padding后为32*32(28+4嘛)
然后我们对这个32*32进行卷积 卷积核为5*5,所以卷积后是28*28*32(很符合我们对卷积后大小不变得期望)
然后我们开始池化操作
卷积是为了提取特征值,多层不同的filter就是为了获取不同的特征值,池化就是为了压缩特征,减少运算量
h_pool1=max_pool_2x2(h_conv1)#池化操作
用2*2的max_pool池化后得到了14*14*32的图
然后我们开始第二层卷积
#第二层卷积
w_conv2=weight_variable([5,5,32,64])
b_conv2=bias_variable([64])
h_conv2=tf.nn.relu(conv2d(h_pool1,w_conv2)+b_conv2)
h_pool2=max_pool_2x2(h_conv2)
这里同样用5*5的卷积层对32深度的卷积----这里运算非常复杂每次都要对5*5*32的矩阵和5*5*1的64个不同的矩阵相乘
然后池化后为7*7*64的矩阵
池化后为全连接层操作了
w_fc1=weight_variable([7*7*64,1024])
b_fc1=bias_variable([1024])
这里 定义全连接层的权重和偏置
7*7*64就是输入 1024为输出 为啥是1024呢? 因为输入是32*32---手写字体是28*28由于paading=SAME所以成了32*32-然后对每个像素计算权重和偏置-自然就是32*32=1024了。
h_pool2_flat=tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,w_fc1)+b_fc1)
这里把池化层的输出变成了7*7*64的一纬度向量
便于输入全连接层-全连接层的输出是1024*1维度的向量
然后执行relu激活函数,做线性修正
#dropout防止过度拟合,随机去掉某些连接
keep_prob=tf.placeholder(tf.float32)
h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob)
这里为了防止过度拟合丢弃了一些连接
# 把1024维的向量转换成10维,对应10个类别
#每个类别的每个像素都有自己的权重。所有一共一1024*10个
#然后矩阵相乘下面用1*1024 和1024*10matmul出对应10个类别的概率+偏置
w_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, w_fc2) + b_fc2
#这里的y_conv就是我们的概率,是个1*10的矩阵
然后我们再定义误差和训练步骤
这里的adamoptimizer是快速随机梯度下降,
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
# 同样定义train_step-让cross-entropy最小化
train_step =tf.train.AdamOptimizer(1e4).minimize(cross_entropy)
再定义测试的准确率
#argmax获取最大值得下标,equal判断是否相等,y_是真实值,y_conv是预测的值
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
#cast把True变成1,flase变0然后reduce_mean求平均值
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
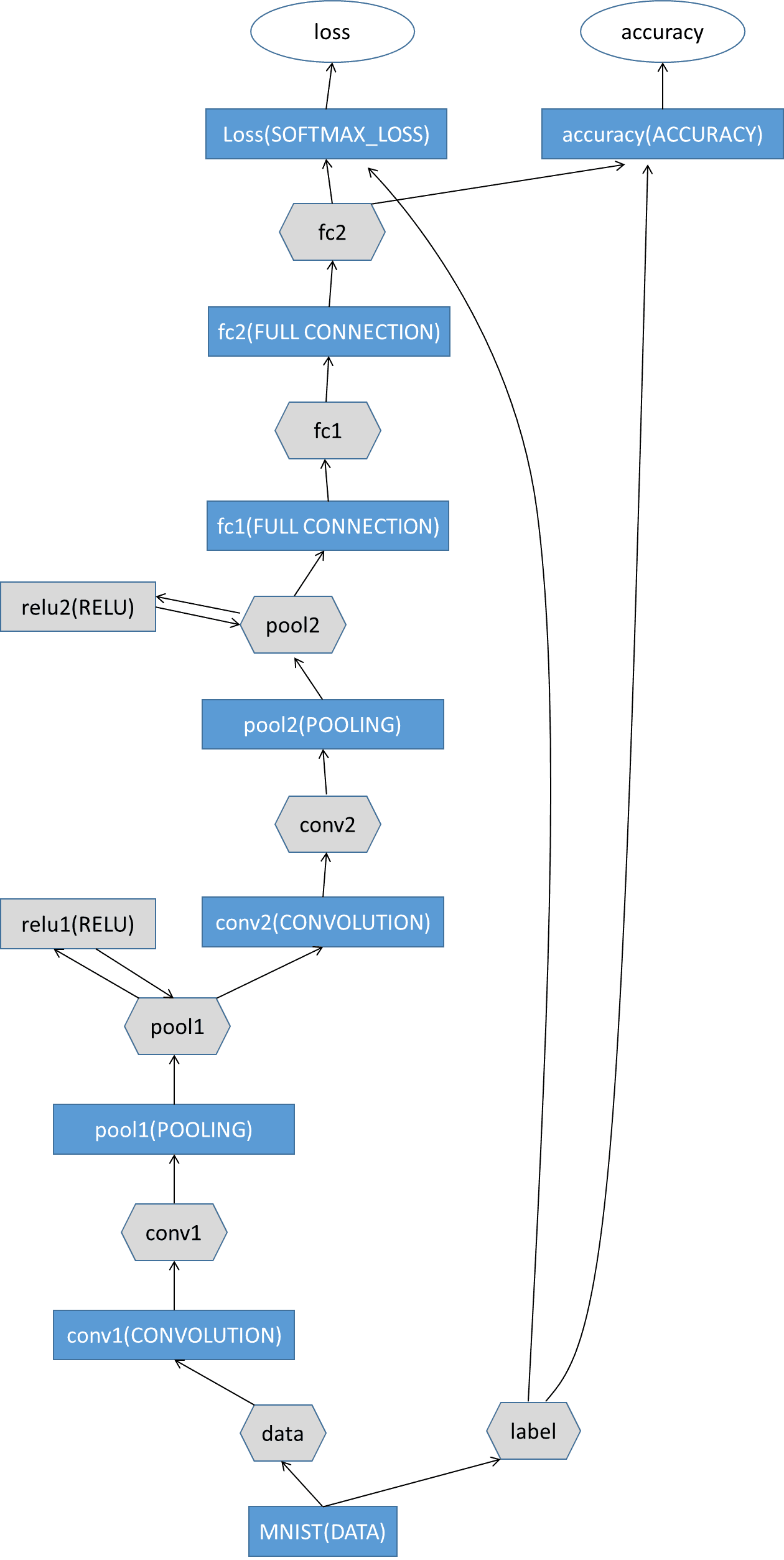
此时我们模型以及建立完毕
我们用图来看下,我画了一张垃圾图,希望自己以后能看的懂。
到这里为止
我们的模型已经建立好了,我们现在要开始训练了
首先初始化所有值,建立会话
# 创建Session和变量初始化
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
开始训练
# 训练2000步
for i in range(2000):
batch = mnist.train.next_batch(50)#一次取50个数据
# 每100步报告一次在验证集上的准确度
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g" % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
最后报告精确度
# 训练结束后报告在测试集上的准确度
print("test accuracy %g" % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
友情提示cpu会跑很久。。。大概几分钟。
深度学习-tensorflow学习笔记(2)-MNIST手写字体识别的更多相关文章
- 深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识
深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识 在tf第一个例子的时候需要很多预备知识. tf基本知识 香农熵 交叉熵代价函数cross-entropy 卷积神经网络 s ...
- 【OpenCV】opencv3.0中的SVM训练 mnist 手写字体识别
前言: SVM(支持向量机)一种训练分类器的学习方法 mnist 是一个手写字体图像数据库,训练样本有60000个,测试样本有10000个 LibSVM 一个常用的SVM框架 OpenCV3.0 中的 ...
- TensorFlow—多层感知器—MNIST手写数字识别
1 import tensorflow as tf import tensorflow.examples.tutorials.mnist.input_data as input_data import ...
- 第二节,mnist手写字体识别
1.获取mnist数据集,得到正确的数据格式 mnist = input_data.read_data_sets('MNIST_data',one_hot=True) 2.定义网络大小:图片的大小是2 ...
- mnist手写数字识别——深度学习入门项目(tensorflow+keras+Sequential模型)
前言 今天记录一下深度学习的另外一个入门项目——<mnist数据集手写数字识别>,这是一个入门必备的学习案例,主要使用了tensorflow下的keras网络结构的Sequential模型 ...
- 深度学习之 mnist 手写数字识别
深度学习之 mnist 手写数字识别 开始学习深度学习,先来一个手写数字的程序 import numpy as np import os import codecs import torch from ...
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别 http://phunter.farbox.com/post/mxnet-tutorial1 用MXnet实战深度学 ...
- 深度学习---手写字体识别程序分析(python)
我想大部分程序员的第一个程序应该都是“hello world”,在深度学习领域,这个“hello world”程序就是手写字体识别程序. 这次我们详细的分析下手写字体识别程序,从而可以对深度学习建立一 ...
- Android+TensorFlow+CNN+MNIST 手写数字识别实现
Android+TensorFlow+CNN+MNIST 手写数字识别实现 SkySeraph 2018 Email:skyseraph00#163.com 更多精彩请直接访问SkySeraph个人站 ...
随机推荐
- 【原创】如何设置Virtual Box虚拟机CentOS7为静态IP地址
如何设置Virtual Box虚拟机CentOS7为静态IP地址 最近要搭建一个Kubernetes集群,需要设置虚拟机为静态IP地址不变.翻了一些资料,参差不齐,有些也比较过时了.自己实测总结了一下 ...
- [iOS]为git设置代理
查看本地git配置信息 git config --global -e 查看自己***的代理地址和端口信息 为git添加代理 git config --global http.proxy https:/ ...
- JS-instanceof 与typeof
通常来讲,使用 instanceof 就是判断一个实例是否属于某种类型 而typeof 无论引用的是什么类型的对象,它都返回 "object" var arr=[1,2,3]; ...
- mysql如何批量删除数据表
-- 注意这里的`是英文输入法状态下,主键盘数字1的左边的键.drop table `user`,`c_class`;
- armv7学习记录
ARM架构支持跨大范围性能点的实现.ARM处理器的架构简单性导致了非常小的实现,而小的实现意味着设备可以具有非常低的功耗.实现大小.性能和非常低的功耗是ARM体系结构的关键属性. ARM架构是一个精简 ...
- 【转】ruby rake执行rspec
RSpec 是Ruby的一个行为驱动开发(BDD)工具,当前的版本是 2.10.根据其入门文档,安装好之后,可以使用 rspec 命令来运行“测试”.但在某些情况下,如果参数较多,使用该命令并不方便: ...
- LeetCode——数组篇:659. 分割数组为连续子序列
659. 分割数组为连续子序列 输入一个按升序排序的整数数组(可能包含重复数字),你需要将它们分割成几个子序列,其中每个子序列至少包含三个连续整数.返回你是否能做出这样的分割? 示例 1: 输入: [ ...
- 安装虚拟机与初触linux心得
安装虚拟机与初触linux心得 安装虚拟机 不知道是电脑问题还是软件问题,我安装虚拟机的过程异常坎坷,首先我在官网,360,太平洋等地方下载的virtualbox5.0以后的软件普遍有问题,问题是打不 ...
- 20155322 2017-2018-1 《信息安全系统设计》第五周 MyBash实现
#20155322 2017-2018-1<信息安全系统设计>第五周 MyBash实现 [博客目录] 实现要求 相关知识 bash fork exec wait 相关问题 fork返回两次 ...
- (The application/json Media Type for JavaScript Object Notation (JSON))RFC4627-JSON格式定义
原文 http://laichendong.com/rfc4627-zh_cn/ 摘要 JavaScript Object Notation (JSON)是一个轻量级的,基于文本的,跨语言的数据交换 ...