二十四、Hadoop学记笔记————Spark的架构
master为主节点

一个集群中可能运行多个application,因此也可能会有多个driver

DAG Scheduler就是讲RDD Graph拆分成一个个stage
一个Task对应一个SparkEnv
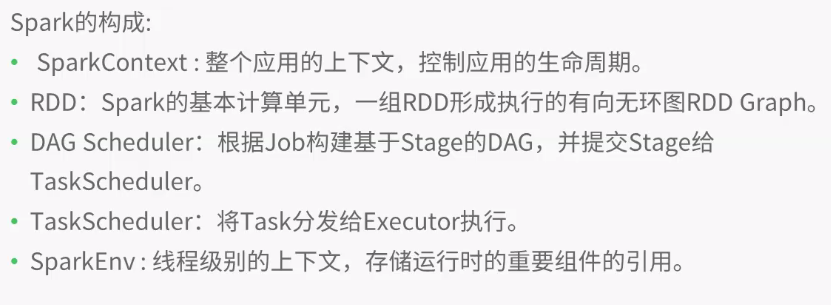
客户端提交请求,然后master生成driver,生成对应的SparkContext,然后将任务拆分为多个RDD,对应上述流程
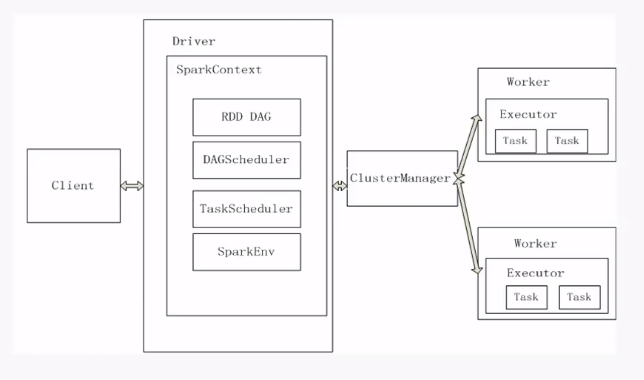

用户自定义Spark程序并且提交后,生成Driver Program,然后生成多个Job,每个JOB根据RDD的宽依赖关系来生成多个stage,一个stage对应一个taskset,taskset只一个stage下所有的task,每个task对应一个block数据块,执行并运算


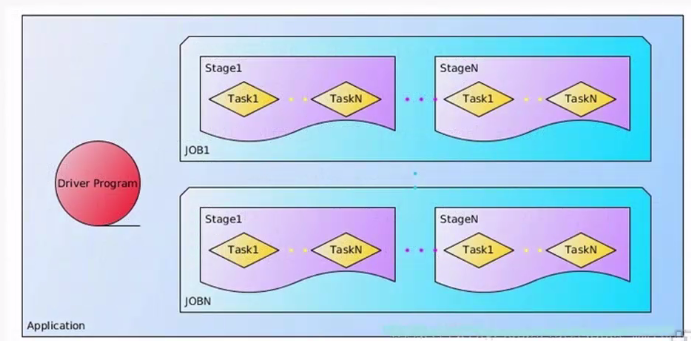

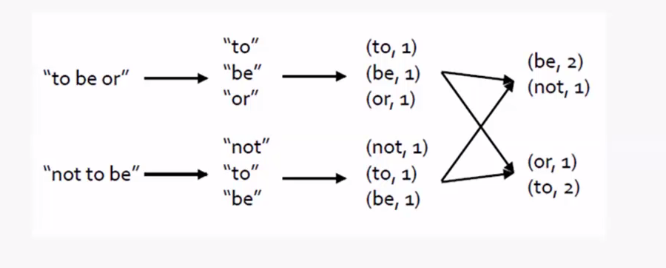





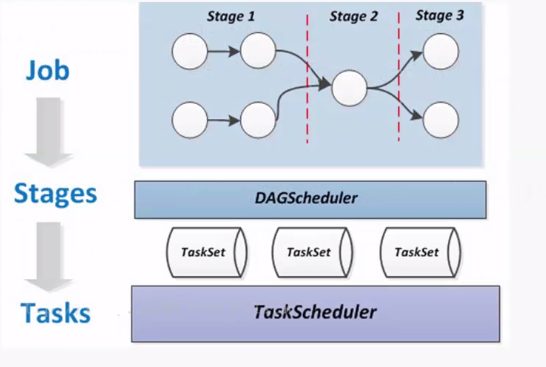


一个block块就有128,如果频繁的IO读取数据将造成大量的网络延时

二十四、Hadoop学记笔记————Spark的架构的更多相关文章
- 二十三、Hadoop学记笔记————Spark简介与计算模型
spark优势在于基于内存计算,速度很快,计算的中间结果也缓存在内存,同时spark也支持streaming流运算和sql运算 Mesos是资源管理框架,作为资源管理和任务调度,类似Hadoop中的Y ...
- 二十、Hadoop学记笔记————Hive On Hbase
Hive架构图: 一般用户接口采用命令行操作, hive与hbase整合之后架构图: 使用场景 场景一:通过insert语句,将文件或者table中的内容加入到hive中,由于hive和hbase已经 ...
- 二十一、Hadoop学记笔记————kafka的初识
这些场景的共同点就是数据由上层框架产生,需要由下层框架计算,其中间层就需要有一个消息队列传输系统 Apache flume系统,用于日志收集 Apache storm系统,用于实时数据处理 Spark ...
- 二十二、Hadoop学记笔记————Kafka 基础实战 :消费者和生产者实例
kafka的客户端也支持其他语言,这里主要介绍python和java的实现,这两门语言比较主流和热门 图中有四个分区,每个图形对应一个consumer,任意一对一即可 获取topic的分区数,每个分区 ...
- 二十五、Hadoop学记笔记————Hive复习与深入
Hive主要为了简化MapReduce流程,使非编程人员也能进行数据的梳理,即直接使用sql语句代替MapReduce程序 Hive建表的时候元数据(表明,字段信息等)存于关系型数据库中,数据存于HD ...
- 十九、Hadoop学记笔记————Hbase和MapReduce
概要: hadoop和hbase导入环境变量: 要运行Hbase中自带的MapReduce程序,需要运行如下指令,可在官网中找到: 如果遇到如下问题,则说明Hadoop的MapReduce没有权限访问 ...
- 十八、Hadoop学记笔记————Hbase架构
Hbase结构图: Client,Zookeeper,Hmaster和HRegionServer相互交互协调,各个组件作用如下: 这几个组件在实际使用过程中操作如下所示: Region定位,先读取zo ...
- 十七、Hadoop学记笔记————Hbase入门
简而言之,Hbase就是一个建立在Hdfs文件系统上的数据库(mysql,orecle等),不同的是Hbase是针对列的数据库 Hbase和普通的关系型数据库区别如下: Hbase有一些基本的术语,主 ...
- python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法
python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法window安装redis,下载Redis的压缩包https://git ...
随机推荐
- Unity3D学习笔记(四)Unity的网络基础(C#)
一 网络下载可以使用WWW类下载资源用法:以下载图片为例WWW date = new WWW("<url>");yield return date;texture = ...
- Oracle Service Bus 11g 的三种方案
使用<Oracle Service Bus 11g Development Cookbook>中的方案迅速推出一批全新的面向服务和消息的解决方案 2012 年 3 月 (单击图像了解更 ...
- mysql进阶(十五) mysql批量删除大量数据
mysql批量删除大量数据 假设有一个表(syslogs)有1000万条记录,需要在业务不停止的情况下删除其中statusid=1的所有记录,差不多有600万条, 直接执行 DELETE FROM s ...
- Android进阶(十九)AndroidAPP开发问题汇总(三)
Android进阶(十九)AndroidAPP开发问题汇总(三) Java解析XML的几种方式: http://inotgaoshou.iteye.com/blog/1012188 从线程返回数据的两 ...
- ffdshow 源代码分析 4: 位图覆盖滤镜(滤镜部分Filter)
===================================================== ffdshow源代码分析系列文章列表: ffdshow 源代码分析 1: 整体结构 ffds ...
- HDFS APPEND性能测试
hbase在写入数据之前会先写hlog,hlog目前是sequencefile格式,采用append的方式往里追加数据.之前团队的同学测试关闭hlog会一定程序上提升写hbase的稳定性.而在我之前的 ...
- 为什么我们要使用ssh框架技术,及感想
前言: 在公司从C++转向Java Web方向大概有3个月(11月初-1月底)了.三个月前对Java和Web还几乎是零基础.然后从安装Eclipse,MySQL,tomcat开始,到学习HTML/CS ...
- LeetCode(33)-Pascal's Triangle II
题目: Given an index k, return the kth row of the Pascal's triangle. For example, given k = 3, Return ...
- obj-c编程13:归档
这篇归档内容的博文也挺有趣的,笨猫对好玩的东西一向感兴趣啊!如果用过ruby就会知道,obj-c里的归档类似于ruby中的序列化概念,不过从语法的简洁度来说,我只能又一次呵呵了. 下面大家将会看到2种 ...
- 基于Redis的分布式锁两种实现方式
最近有一个竞拍的项目会用到分布式锁,网上查到的结果是有三种途径可以实现.1.数据库锁机制,2.redis的锁,3.zookeeper.考虑到使用mysql实现会在性能这一块会受影响,zookeeper ...