大数据小白系列——HDFS(4)
这里是大数据小白系列,这是本系列的第四篇,来看一个真实世界Hadoop集群的规模,以及我们为什么需要Hadoop Federation。
首先,我们先要来个直观的印象,这是你以为的Hadoop集群:
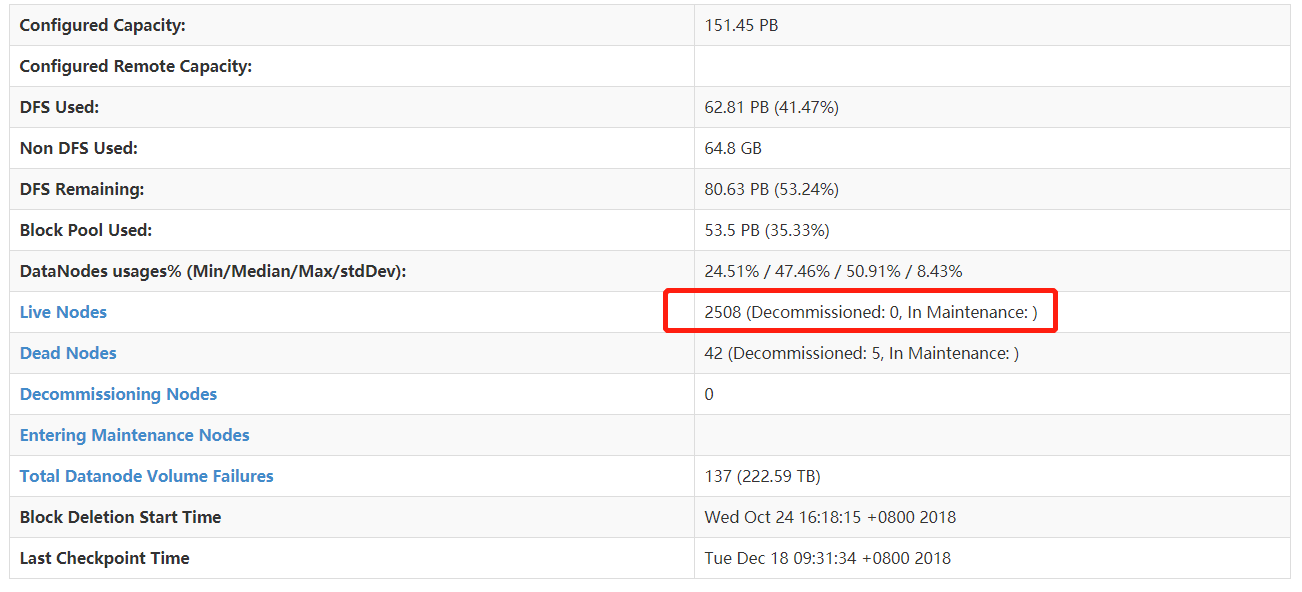
这是真实世界的Hadoop集群:
因为,NameNode(下称NN)中的元数据记录了各个数据块的存储位置。
所以,元数据的大小,与数据块的数量成正比。
当集群存储的数据规模到达一定程度时,NN将成为整套系统中的瓶颈所在。NN的存储能力是有限的,不管是磁盘存储还是内存存储。
为了解决这个问题,HDFS中引入了联邦(Federation)的概念。
联邦:由若干具有国家性质的行政区域(有国、邦、州等不同名称)联合而成的统一国家,各行政区域有自己的宪法、立法机关和政府,联邦也有统一的宪法、立法机关和政府。—— 维基百科
体现在HDFS上,就是“集权”到“分权”的过程,引入了多对NN(Active NN + Standby NN这里称为一对),让他们各自实现“区域自治”。
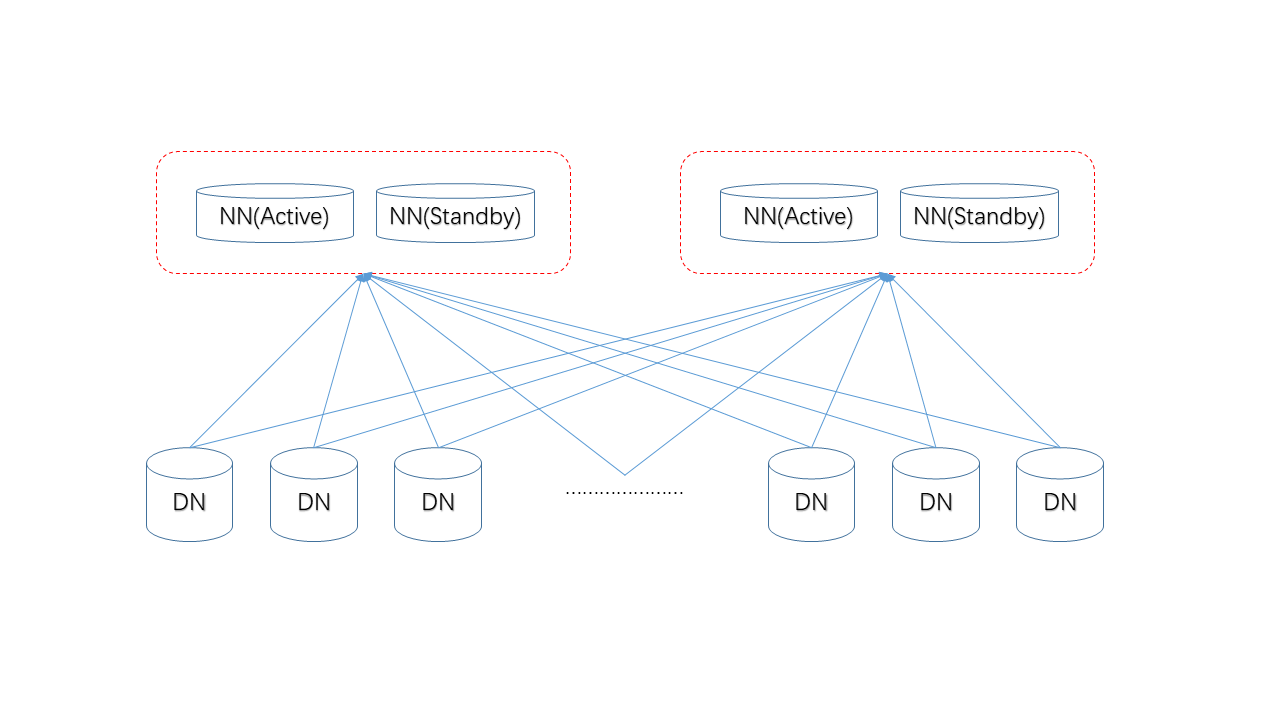
物理上是这样的,所有的DN(DataNode)需向所有的NN汇报状态。
逻辑上是这样的,一对NN只负责管理属于自己名称空间下的目录。
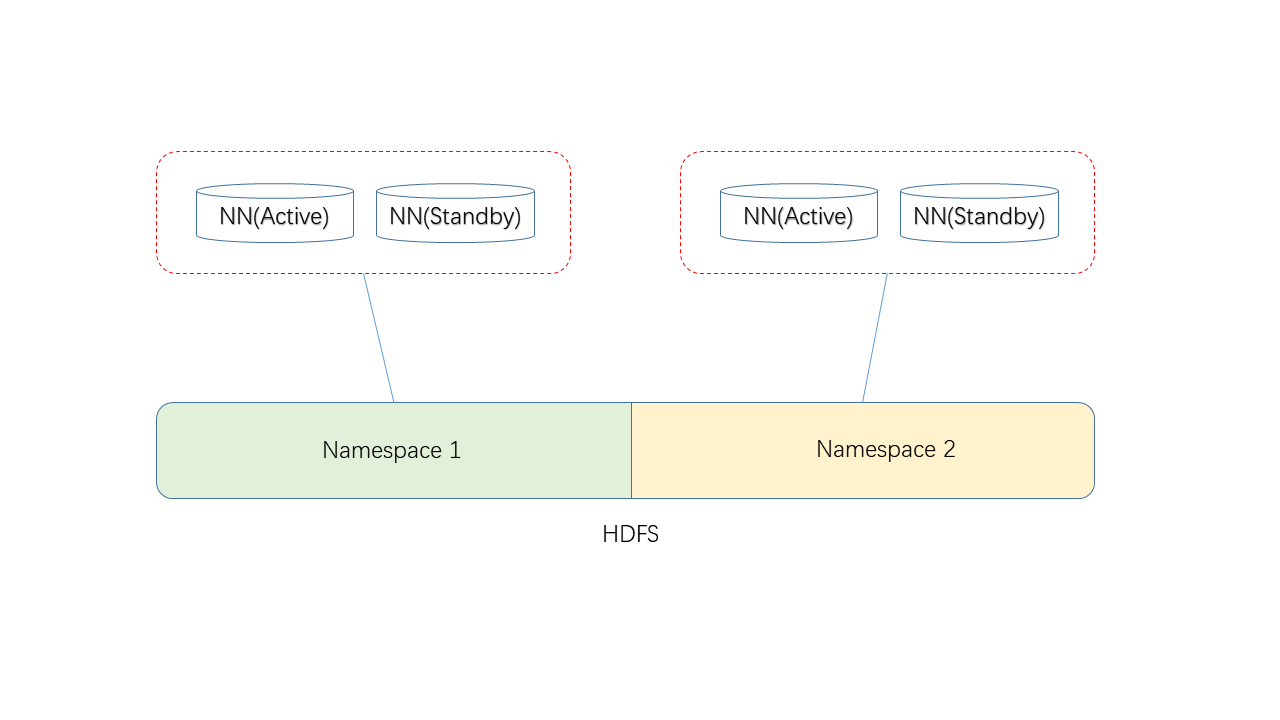
因此,并不是某对NN管理某些DN,而是对HDFS进行划分,即逻辑划分。
上面这样规模的集群,有可能划分出数十个“邦”,各自管理“邦”内的数据,这样就基本实现了NN的水平扩展,同时,还对提高整个系统的可用性有帮助,毕竟,某一对NN宕机,只会对系统产生局部影响。
注:HDFS联邦并不强制要求各NN都做HA,只是通常是这样配置的,即每个“邦”的NN都是成对出现的。
好了,关于HDFS的所有介绍就先到这,那些没讲到的,都不重要(误),下期我们将开始介绍新的内容:MapReduce的基本概念。Cheers!
公众号 程序员杂书馆,大数据内容持续更新中,欢迎关注!

大数据小白系列——HDFS(4)的更多相关文章
- 大数据小白系列——HDFS(3)
这里是大数据小白系列,这是本系列的第三篇,介绍HDFS中NameNode选举,JournalNode等概念. 上一期我们说到了为解决NameNode(下称NN)单点失败问题,HDFS中使用了双NN的机 ...
- 大数据小白系列——HDFS(2)
这里是大数据小白系列,这是本系列的第二篇,介绍一下HDFS中SecondaryNameNode.单点失败(SPOF).以及高可用(HA)等概念. 上一篇我们说到了大数据.分布式存储,以及HDFS中的一 ...
- 大数据小白系列——HDFS(1)
[注1:结尾有大福利!] [注2:想写一个大数据小白系列,介绍大数据生态系统中的主要成员,理解其原理,明白其用途,万一有用呢,对不对.] 大数据是什么?抛开那些高大上但笼统的说法,其实大数据说的是两件 ...
- 大数据小白系列——MR(1)
一部编程发展史就是一部程序员偷懒史,MapReduce(下称MR)同样是程序员们用来偷懒的工具. 来了一份大数据,我们写了一个程序准备分析它,需要怎么做? 老式的处理方法不行,数据量太大时,所需的时间 ...
- 大数据小白系列 —— MapReduce流程的深入说明
上一期我们介绍了MR的基本流程与概念,本期稍微深入了解一下这个流程,尤其是比较重要但相对较少被提及的Shuffling过程. Mapping 上期我们说过,每一个mapper进程接收并处理一块数据,这 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
随机推荐
- Confluence 6 布局高级自定义
重载 Velocity 模板 velocity 目录是 Confluence Velocity 模板文件进行搜索时候需要的文件夹.例如,你可以通过将你的 Velocity 文件使用正确的文件名放置到正 ...
- Confluence 6 上传站点图标后重置你的配色方案
当你上传一个站点标识图片后,Confluence 会根据你上传的图片文件自动侦测使用的颜色,并为你设置自动配色方案. 你可以按照上面描述的方法修改色彩配色方案,或者你也可以重置配色方案为默认的配色方案 ...
- day07 元组类型 字典类型 集合
元组:元组就是一个不可变的列表 1.用途:当我们需要记录多个同种属性的值,并且只有读的需求,没有改的需求,应该用元组. 2.定义方式:在()内用逗号分隔开多个任意类型的元素 t=(‘egon’)#注意 ...
- java和python对比----1:
对计算来说: java 除法: 3/4 ==0; pyhton 除法: 3/4 ==0 3//4==0.75
- 统计nginx日志里访问次数最多的前十个IP
awk '{print $1}' /var/log/nginx/access.log | sort | uniq -c | sort -nr -k1 | head -n 10
- appium获取APP控件信息
uiautomatorviewer.bat 该文件位于SDK安装目录tools下,如笔者在“C:\Program Files (x86)\Android\android-sdk\tools”下,双击u ...
- jenkins权限管理,实现不同用户组显示对应视图views中不同的jobs
如何分组管理权限,如何实现不同用户组显示对应视图views中不同的jobs,建议使用Role Strategy Plugin插件. 1.安装Role Strategy Plugin插件. 2.“系统管 ...
- AI-DRF权限、频率
权限 权限逻辑 权限逻辑 权限组件可以设置在三个地方:写在每个类下边表示,访问这个类的数据时,没有权限就不能访问:写在全局,表示访问每个字段的数据都需要权限:还有默认已经也写好了. 写在每个类中:写一 ...
- C++ Primer 笔记——lambda表达式
1.一个lambda表达式表示一个可调用的代码单元,可以理解为一个未命名的内联函数,但是与函数不同,lambda表达式可能定义在函数内部.其形式如下: [capture list] (paramete ...
- spring cloud Eureka注册中心集群搭建
1.创建springcloud-eureka maven项目 pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0&quo ...