scrapy爬虫案例:用MongoDB保存数据
用Pymongo保存数据
爬取豆瓣电影top250movie.douban.com/top250的电影数据,并保存在MongoDB中。
items.py
class DoubanspiderItem(scrapy.Item):
# 电影标题
title = scrapy.Field()
# 电影评分
score = scrapy.Field()
# 电影信息
content = scrapy.Field()
# 简介
info = scrapy.Field()
spiders/douban.py
import scrapy
from doubanSpider.items import DoubanspiderItem class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["movie.douban.com"]
start = 0
url = 'https://movie.douban.com/top250?start='
end = '&filter='
start_urls = [url + str(start) + end] def parse(self, response): item = DoubanspiderItem() movies = response.xpath("//div[@class=\'info\']") for each in movies:
title = each.xpath('div[@class="hd"]/a/span[@class="title"]/text()').extract()
content = each.xpath('div[@class="bd"]/p/text()').extract()
score = each.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract()
info = each.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract() item['title'] = title[0]
# 以;作为分隔,将content列表里所有元素合并成一个新的字符串
item['content'] = ';'.join(content)
item['score'] = score[0]
item['info'] = info[0]
# 提交item yield item if self.start <= 225:
self.start += 25
yield scrapy.Request(self.url + str(self.start) + self.end, callback=self.parse)
pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json import pymongo
from scrapy.utils.project import get_project_settings class DoubanspiderPipeline(object):
def __init__(self):
settings = get_project_settings()
# 获取setting主机名、端口号和数据库名
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
dbname = settings['MONGODB_DBNAME'] # pymongo.MongoClient(host, port) 创建MongoDB链接
client = pymongo.MongoClient(host=host, port=port) # 指向指定的数据库
mdb = client[dbname]
# 获取数据库里存放数据的表名
self.post = mdb[settings['MONGODB_DOCNAME']] def process_item(self, item, spider):
data = dict(item)
# 向指定的表里添加数据
self.post.insert(data)
return item
BOT_NAME = 'doubanSpider' SPIDER_MODULES = ['doubanSpider.spiders']
NEWSPIDER_MODULE = 'doubanSpider.spiders' ITEM_PIPELINES = {
'doubanSpider.pipelines.DoubanspiderPipeline' : 300
} # Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36' # MONGODB 主机环回地址127.0.0.1
MONGODB_HOST = '127.0.0.1'
# 端口号,默认是27017
MONGODB_PORT = 27017
# 设置数据库名称
MONGODB_DBNAME = 'DouBan'
# 存放本次数据的表名称
MONGODB_DOCNAME = 'DouBanMovies'
效果:
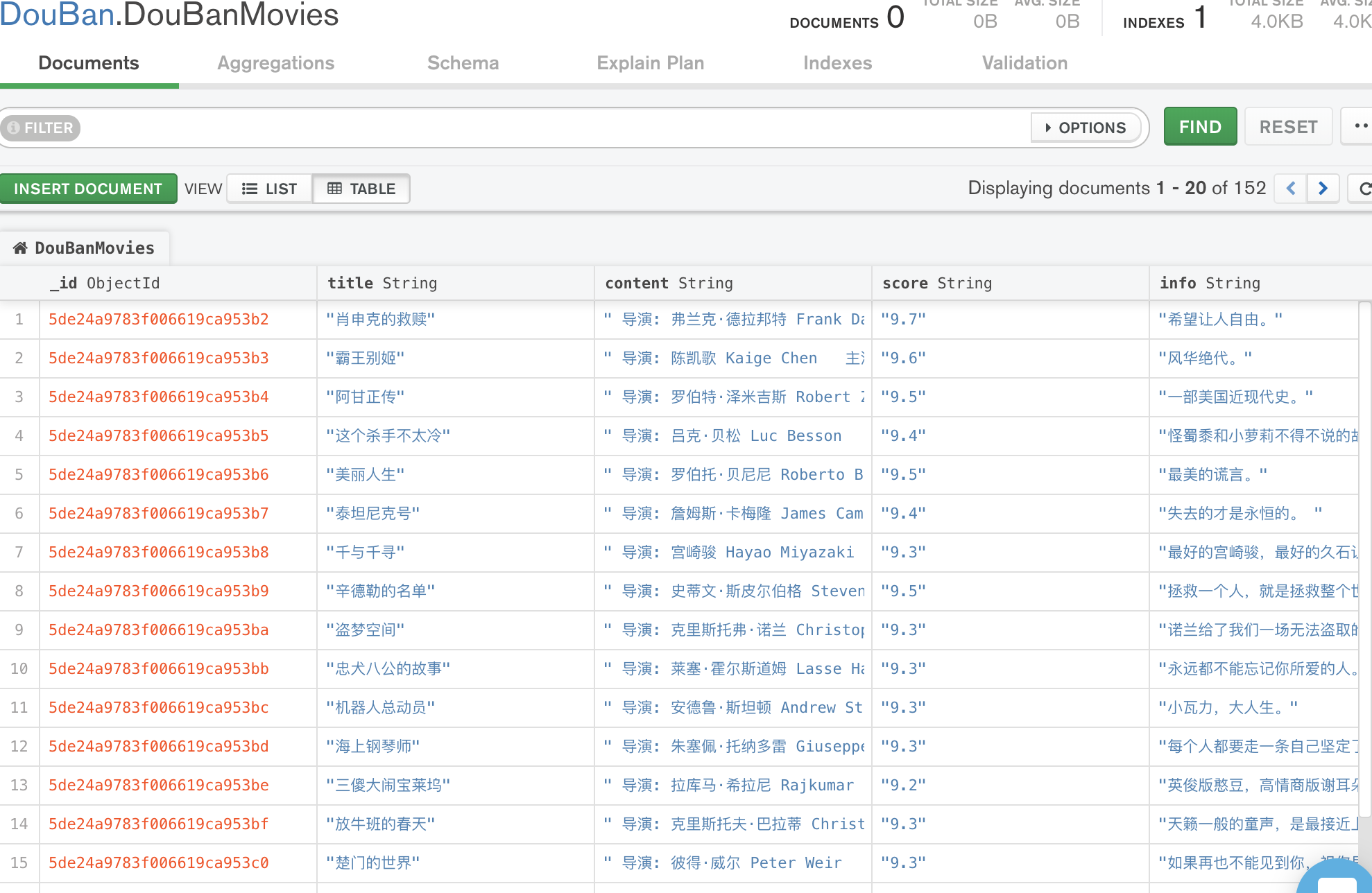
scrapy爬虫案例:用MongoDB保存数据的更多相关文章
- 【mongodb系统学习之九】mongodb保存数据
九.mongodb保存数据: 1).插入.保存数据:insert:语法db.collectionName.insert({"key":value}),key是字段名,必须是字符串( ...
- Scrapy爬虫案例 | 数据存储至MongoDB
豆瓣电影TOP 250网址 要求: 1.爬取豆瓣top 250电影名字.演员列表.评分和简介 2.设置随机UserAgent和Proxy 3.爬取到的数据保存到MongoDB数据库 items.py ...
- Scrapy爬虫案例 | 数据存储至MySQL
首先,MySQL创建好数据库和表 然后编写各个模块 item.py import scrapy class JianliItem(scrapy.Item): name = scrapy.Field() ...
- scrapy爬虫案例--爬取阳关热线问政平台
阳光热线问政平台:http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1 爬取最新问政帖子的编号.投诉标题.投诉内容以 ...
- python scrapy 实战简书网站保存数据到mysql
1:创建项目 2:创建爬虫 3:编写start.py文件用于运行爬虫程序 # -*- coding:utf-8 -*- #作者: baikai #创建时间: 2018/12/14 14:09 #文件: ...
- 爬虫案例(js动态生成数据)
需求:爬取https://www.xuexi.cn/f997e76a890b0e5a053c57b19f468436/018d244441062d8916dd472a4c6a0a0b.html页面中的 ...
- scrapy爬虫案例:问政平台
问政平台 http://wz.sun0769.com/index.php/question/questionType?type=4 爬取投诉帖子的编号.帖子的url.帖子的标题,和帖子里的内容. it ...
- python3+Scrapy爬虫使用pipeline数据保存到文本和数据库,数据少或者数据重复问题
爬取的数据结果是没有错的,但是在保存数据的时候出错了,出现重复数据或者数据少问题.那为什么会造成这种结果呢? 其原因是由于Spider的速率比较快,而scapy操作数据库操作比较慢,导致pipelin ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
随机推荐
- kill 命令在Java应用中使用注意事项
前言 我们都知道,kill在linux系统中是用于杀死进程. kill pid [..] kill命令可将指定的信号发送给相应的进程或工作. kill命令默认使用信号为15,用于结束进程或工作.如果进 ...
- 解锁 redis 锁的正确姿势
redis 是 php 的好朋友,在 php 写业务过程中,有时候会使用到锁的概念,同时只能有一个人可以操作某个行为.这个时候我们就要用到锁.锁的方式有好几种,php 不能在内存中用锁,不能使用 zo ...
- python url合并与分离
#!/bin/python3 from urllib import parse parse.urlsplit() 将url分为6个部分,返回一个包含6个字符串项目的元组:协议.位置.路径.参数.查询 ...
- Mac下Mysql配置
安装 http://www.mirrorservice.org/sites/ftp.mysql.com/Downloads/MySQL-5.6/mysql-5.6.41-macos10.13-x86_ ...
- Centos 7.3 镜像制作
1.在KVM环境上准备虚拟机磁盘 [root@localhost ~]# qemu-img create -f qcow2 -o size=50G /opt/CentOS---x86_64_50G.q ...
- hexo的jacman主题设置语言为英文后偶尔出现中文
发现这个问题也好久了.问题的具体表现是在根目录下的_config.yml设置了语言为英文,但是每次发布后都会更换一次语言.今天看了文件结构,知道了,每换一次语言“英文.简体中文.繁体中文”,就是这三种 ...
- 项目Beta冲刺(5/7)(追光的人)(2019.5.27)
所属课程 软件工程1916 作业要求 Beta冲刺博客汇总 团队名称 追光的人 作业目标 描述Beta冲刺每日的scrum和PM报告两部分 队员学号 队员博客 221600219 小墨 https:/ ...
- discuz x3.3门户出现关键词和描述显示“首页”的解决方法
Discuz社区在后台设置好门户标题.关键字.描述,更新缓存,发现用户登录状态下,门户首页的关键字和描述正常显示:但在游客状态下不显示,在某工具中查看到的情况是只显示首页,这对SEO是致命打击. 找到 ...
- 22、pandas表格、文件和数据库模块
pandas官方文档:https://pandas.pydata.org/pandas-docs/stable/?v=20190307135750 pandas基于Numpy,可以看成是处理文本或者表 ...
- wordpress调用文章摘要,若无摘要则自动截取文章内容字数做为摘要
以下是调用指定分类文章列表的一个方法,作者如果有填写文章摘要则直接调用摘要:如果文章摘要忘记写了则自动截取文章内容字数做为摘要.这个方法也适用于调用description标签 <ul> & ...