spark踩坑--WARN ProcfsMetricsGetter: Exception when trying to compute pagesize的最全解法
spark踩坑--WARN ProcfsMetricsGetter: Exception when trying to compute pagesize的最全解法
问题描述
大概是今年上半年的时候装了spark(windows环境/spark-3.0.0-preview2/hadoop2.7),装完环境之后就一直没管,今天用的时候出现了这个错误:
20/12/17 12:06:34 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:382)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:397)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:390)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:80)
at org.apache.hadoop.security.SecurityUtil.getAuthenticationMethod(SecurityUtil.java:611)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:274)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:262)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:807)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:777)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:650)
at org.apache.spark.util.Utils$.$anonfun$getCurrentUserName$1(Utils.scala:2412)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2412)
at org.apache.spark.SecurityManager.<init>(SecurityManager.scala:79)
at org.apache.spark.deploy.SparkSubmit.secMgr$lzycompute$1(SparkSubmit.scala:368)
at org.apache.spark.deploy.SparkSubmit.secMgr$1(SparkSubmit.scala:368)
at org.apache.spark.deploy.SparkSubmit.$anonfun$prepareSubmitEnvironment$8(SparkSubmit.scala:376)
at scala.Option.map(Option.scala:230)
at org.apache.spark.deploy.SparkSubmit.prepareSubmitEnvironment(SparkSubmit.scala:376)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:871)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1007)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1016)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
20/12/17 12:06:34 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://LAPTOP-G0A3PQME:4040
Spark context available as 'sc' (master = local[*], app id = local-1608178002520).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0-preview2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_211)
Type in expressions to have them evaluated.
Type :help for more information.
scala> 20/12/17 12:06:59 WARN ProcfsMetricsGetter: Exception when trying to compute pagesize, as a result reporting of ProcessTree metrics is stopped
WARN ProcfsMetricsGetter: Exception when trying to compute pagesize, as a result reporting of ProcessTree metrics is stopped,跳出了warn之后进入了阻塞状态,只能ctrlc关闭。试了一圈别人总结的方法,发现都没有解决,所以把我的方法总结在下面:
解决方法
1 建议首先先检查下pyspark和scala
我回忆了一下,可能是因为上半年我重新配了一遍各种环境,所以导致了问题。命令行看一下
scala -version
检查pyspark已经下载,检查scala已经安装并且版本合适。(不同版本的spark对于hadoop和scala有要求,官网上有介绍,比如下图)
在我重新安装了scala之后,已经不会再进入阻塞状态,可以正常输入了,大概是这个样子:
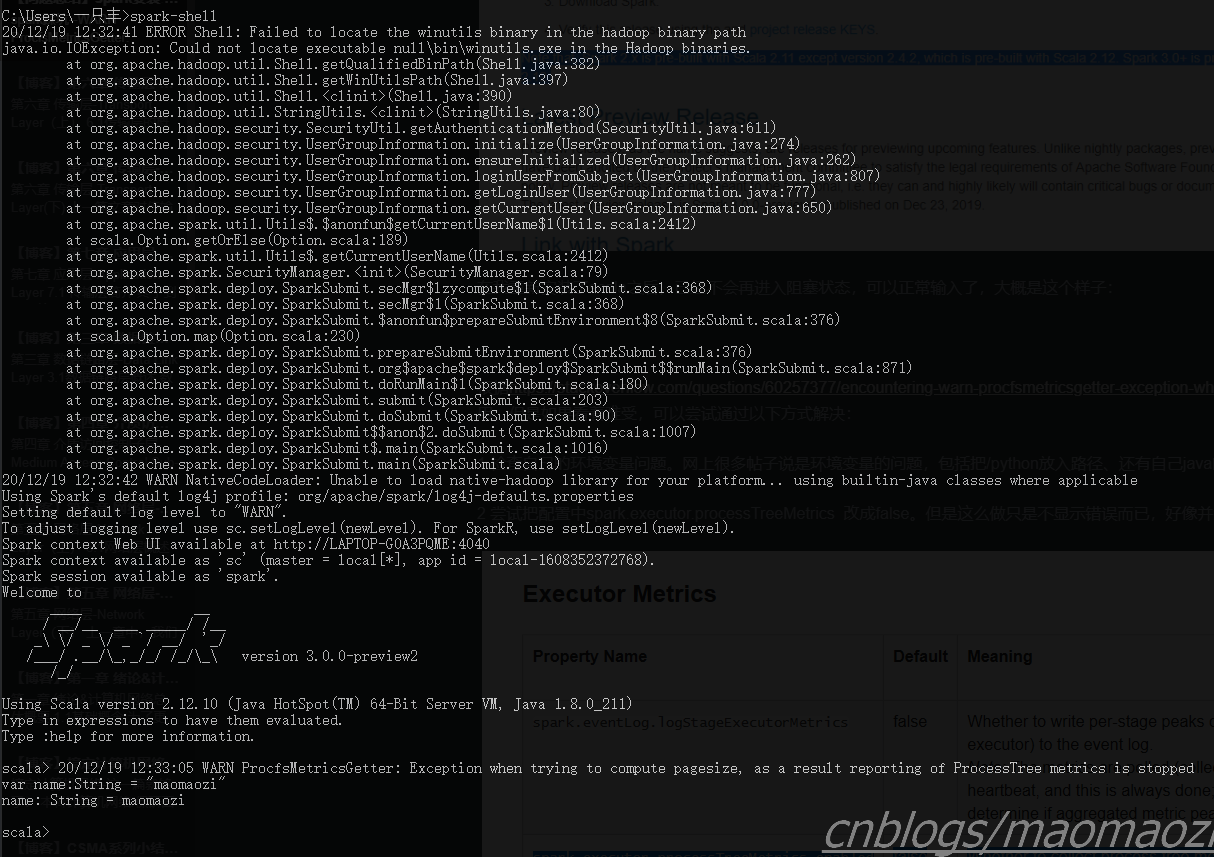
这个时候应该就可以正常使用了,到目前为止我也没有遇到什么明显的问题。且根据https://stackoverflow.com/questions/60257377/encountering-warn-procfsmetricsgetter-exception-when-trying-to-compute-pagesi,这个WARN本身应该不影响正常使用。但是如果看着难受,也可以尝试通过以下方式解决:
2 检查自己的环境变量问题
网上很多帖子说是环境变量的问题,包括把%SPARK_HOME%\python放入路径、还有自己java的路径没写对、以及/bin和/sbin(我尝试了还是没有解决,但读者们还是可以试一下)

注意都放到系统变量里面。
3 把配置中spark.executor.processTreeMetrics 改成false
去git上看了一下这个错误位置,应该是这个地方抛出的:
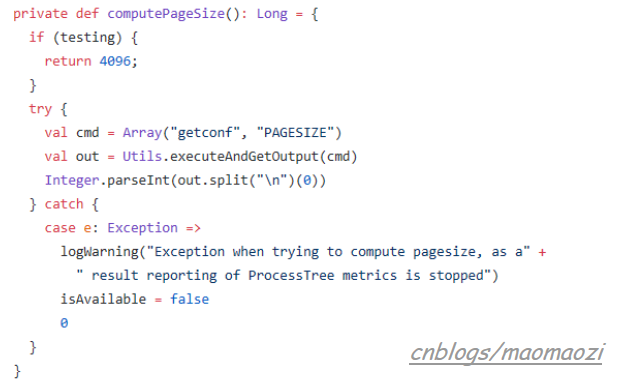
所以把配置中spark.executor.processTreeMetrics 改成false应该就可以了,但是这么做大概相当于屏蔽掉问题。我看了一下目前网上的相似问题,能查到的基本都是spark3.0才才会出现的问题。并且根据apache发的公告来说,这是一个3.0版本后才发布的改动(https://spark.apache.org/docs/3.0.1/configuration.html)。当把这个改成true的时候,spark可以高频率的收集执行指标。(if spark.executor.processTreeMetrics.enabled=true; The optional configuration spark.executor.metrics.pollingInterval allows to gather executor metrics at high frequency, see doc. )
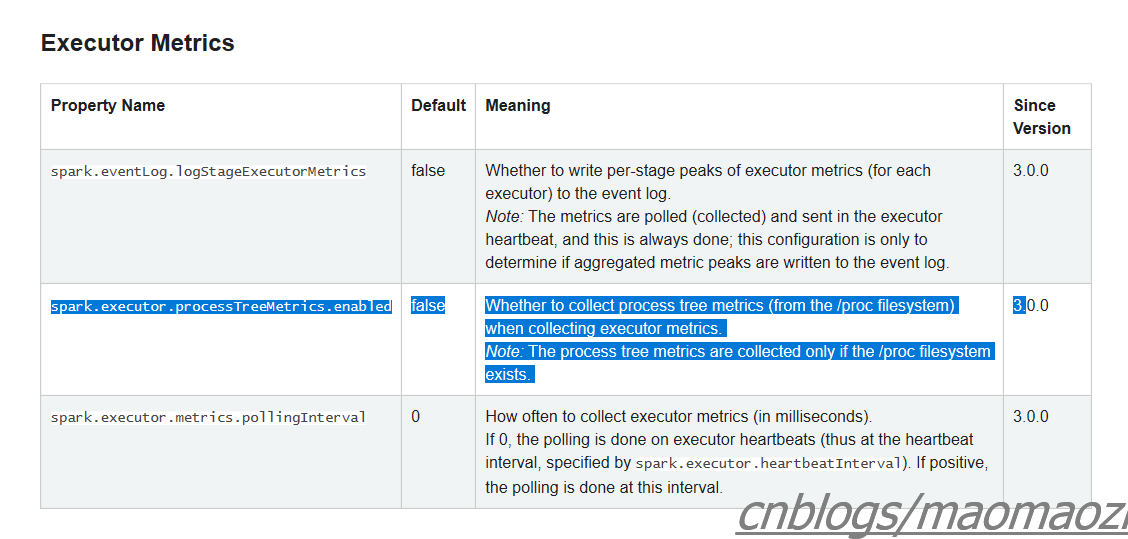
4 如果还是不行,换一个旧点的版本。
因为是3.0.0才发布的改动,如果还是不行的话应该只能换个旧一点的版本了(比如2.4.6)。如果不是企业级开发的话,也不会有太大问题。毕竟spark配置也不算很繁琐。
内容参考
https://www.aws-senior.com/apache-spark-3-0-memory-monitoring-improvements/
https://blog.csdn.net/qq_36888550/article/details/106971949
spark踩坑--WARN ProcfsMetricsGetter: Exception when trying to compute pagesize的最全解法的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark踩坑记——从RDD看集群调度
[TOC] 前言 在Spark的使用中,性能的调优配置过程中,查阅了很多资料,之前自己总结过两篇小博文Spark踩坑记--初试和Spark踩坑记--数据库(Hbase+Mysql),第一篇概况的归纳了 ...
- [转]Spark 踩坑记:数据库(Hbase+Mysql)
https://cloud.tencent.com/developer/article/1004820 Spark 踩坑记:数据库(Hbase+Mysql) 前言 在使用Spark Streaming ...
- Spark踩坑记——数据库(Hbase+Mysql)转
转自:http://www.cnblogs.com/xlturing/p/spark.html 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库 ...
- Spark踩坑记:Spark Streaming+kafka应用及调优
前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从k ...
- Spark踩坑记——共享变量
[TOC] 前言 Spark踩坑记--初试 Spark踩坑记--数据库(Hbase+Mysql) Spark踩坑记--Spark Streaming+kafka应用及调优 在前面总结的几篇spark踩 ...
- Spark踩坑记:共享变量
收录待用,修改转载已取得腾讯云授权 前言 前面总结的几篇spark踩坑博文中,我总结了自己在使用spark过程当中踩过的一些坑和经验.我们知道Spark是多机器集群部署的,分为Driver/Maste ...
- Spark踩坑填坑-聚合函数-序列化异常
Spark踩坑填坑-聚合函数-序列化异常 一.Spark聚合函数特殊场景 二.spark sql group by 三.Spark Caused by: java.io.NotSerializable ...
随机推荐
- [sql 注入] insert 报错注入与延时盲注
insert注入的技巧在于如何在一个字段值内构造闭合. insert 报错注入 演示案例所用的表: MariaDB [mysql]> desc test; +--------+--------- ...
- guitar pro系列教程(二十):Guitar Pro使用技巧之使用向导
本章节将采用图文结合的方式为大家讲述{cms_selflink page='index' text='Guitar Pro'}使用技巧里面的使用向导的相关知识,有兴趣的朋友可以一起来学习哦. 当你创建 ...
- guitar pro系列教程(十四):Guitar Pro教程之创建新乐谱后的设置
前面的章节我们有对Guitar Pro的单个功能作介绍,对于初学作曲,且又是吉他初学者的朋友们来说,学完这些功能介绍,自己还不能融会贯通起来,创建了一个新的乐谱后,但是看起来还不是很满意,今天我们就创 ...
- 对KVC和KVO的理解
html { overflow-x: initial !important } :root { --bg-color: #ffffff; --text-color: #333333; --select ...
- T147403 「TOC Round 4」吃,都可以吃
若不考虑 \(m\) 的限制,打表可以发现: 当 \(p=2^n\left(n>1\right)\) 时,最大的 \(f_i\) 是 \(5\),有十个 \(i\) 的 \(f_i\) 是 \( ...
- jstack测试
1.RUNABLE 2.BLOCKED 3.WAITING/TIMED_WAITING Reference Handler线程与Finalizer线程,这两个线程用于虚拟机处理override了obj ...
- java17(面向对象)
1.面向过程:所有事情都是按顺序一件件做,未知主体 买菜,做饭,吃饭,洗碗 面向对象:将功能封装到对象之中,让对象去实现功能 去饭馆,告诉服务员要吃啥,然后等着端上来. 面向对象的目的: 复杂的东西简 ...
- C语言const和define的区别
const 定义的是变量不是常量,只是这个变量的值不允许改变是常变量!带有类型.编译运行的时候起作用存在类型检查. define 定义的是不带类型的常数,只进行简单的字符替换.在预编译的时候起作用,不 ...
- 音视频入门-18-手动生成一张GIF图片
* 音视频入门文章目录 * GIF 编码知识 GIF 包含的数据块: 文件头(Header) 逻辑屏幕标识符(Logical Screen Descriptor) 全局颜色表(Global Color ...
- Hadoop完全分布式模式安装部署
在Linux上搭建Hadoop系列:1.Hadoop环境搭建流程图2.搭建Hadoop单机模式3.搭建Hadoop伪分布式模式4.搭建Hadoop完全分布式模式 注:此教程皆是以范例讲述的,当然你可以 ...