回归损失函数:L1,L2,Huber,Log-Cosh,Quantile Loss
回归损失函数:L1,L2,Huber,Log-Cosh,Quantile Loss
机器学习中所有的算法都需要最大化或最小化一个函数,这个函数被称为“目标函数”。其中,我们一般把最小化的一类函数,称为“损失函数”。它能根据预测结果,衡量出模型预测能力的好坏。
在实际应用中,选取损失函数会受到诸多因素的制约,比如是否有异常值、机器学习算法的选择、梯度下降的时间复杂度、求导的难易程度以及预测值的置信度等等。因此,不存在一种损失函数适用于处理所有类型的数据。损失函数大致可分为两类:分类问题的损失函数和回归问题的损失函数。这篇文章介绍不同种类的回归损失函数以及它们的作用。

1、MAE / L1 + MSE / L2
(1)平均绝对误差(MAE / L1)
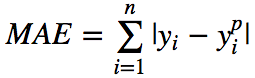
Y轴:MAE损失。X轴:预测值。

平均绝对误差(MAE)是一种用于回归模型的损失函数。MAE是目标值和预测值之差的绝对值之和。其只衡量了预测值误差的平均模长,而不考虑方向,取值范围也是从0到正无穷(如果考虑方向,则是残差/误差的总和——平均偏差(MBE))。
(2)均方误差(MSE / L2)

Y轴:MSE损失。X轴:预测值。

均方误差(MSE)是最常用的回归损失函数,计算方法是求预测值与真实值之间距离的平方和。MSE函数的图像中,目标值是100,预测值的范围从-10000到10000,Y轴代表的MSE取值范围是从0到正无穷,并且在预测值为100处达到最小。
(3)MSE(L2损失)与MAE(L1损失)的分析
简单来说,MSE计算简便,但MAE对异常点有更好的鲁棒性。训练一个机器学习模型时,目标就是找到损失函数达到极小值的点。当预测值等于真实值时,这两种函数都能达到最小。
分析:MSE对误差取了平方(令e=真实值-预测值),因此若e>1,则MSE会进一步增大误差。如果数据中存在异常点,那么e值就会很大,而e²则会远大于|e|。因此,相对于使用MAE计算损失,使用MSE的模型会赋予异常点更大的权重。用RMSE(即MSE的平方根,同MAE在同一量级中)计算损失的模型会以牺牲了其他样本的误差为代价,朝着减小异常点误差的方向更新。然而这就会降低模型的整体性能。
直观上可以这样理解:如果我们最小化MSE来对所有的样本点只给出一个预测值,那么这个值一定是所有目标值的平均值。但如果是最小化MAE,那么这个值,则会是所有样本点目标值的中位数。对异常值而言,中位数比均值更加鲁棒,因此MAE对于异常值也比MSE更稳定。
如何选择损失函数:如果训练数据被异常点所污染(比如,在训练数据中存在大量错误的反例和正例标记,但是在测试集中没有这个问题)或者异常点代表在商业中很重要的异常情况,并且需要被检测出来,则应选用MSE损失函数。相反,如果只把异常值当作受损数据,则应选用MAE损失函数。
MAE存在一个严重的问题(特别是对于神经网络):更新的梯度始终相同,也就是说,即使对于很小的损失值,梯度也很大。这样不利于模型的学习。为了解决这个缺陷,可以使用变化的学习率,在损失接近最小值时降低学习率。
MSE在这种情况下的表现就很好,即便使用固定的学习率也可以有效收敛。MSE损失的梯度随损失增大而增大,而损失趋于0时则会减小。这使得在训练结束时,使用MSE模型的结果会更精确。
总结:处理异常点时,L1损失函数更稳定,但它的导数不连续,因此求解效率较低。L2损失函数对异常点更敏感,但通过令其导数为0,可以得到更稳定的封闭解。
二者兼有的问题是:在某些情况下,上述两种损失函数都不能满足需求。例如,若数据中90%的样本对应的目标值为150,剩下10%在0到30之间。那么使用MAE作为损失函数的模型可能会忽视10%的异常点,而对所有样本的预测值都为150。这是因为模型会按中位数来预测。而使用MSE的模型则会给出很多介于0到30的预测值,因为模型会向异常点偏移。上述两种结果在许多商业场景中都是不可取的。最简单的办法是对目标变量进行变换。而另一种办法则是换一个损失函数。
2、Huber Loss
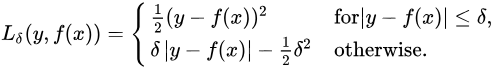
Y轴:Huber损失。X轴:预测值。真值取0。

Huber损失,平滑的平均绝对误差。Huber损失对数据中的异常点没有平方误差损失那么敏感。它在0也可微分。本质上,Huber损失是绝对误差,只是在误差很小时,就变为平方误差。误差降到多小时变为平方误差由超参数δ(delta)来控制。当Huber损失在 [0-δ,0+δ] 之间时,等价为MSE,而在 [-∞,δ] 和 [δ,+∞] 时为MAE。
这里超参数delta的选择非常重要,因为这决定了对异常点的定义。当残差大于delta,应当采用L1(对较大的异常值不那么敏感)来最小化,而残差小于超参数,则用L2来最小化。
如何选择损失函数:使用MAE训练神经网络最大的一个问题就是不变的大梯度,这可能导致在使用梯度下降快要结束时,错过了最小点。而对于MSE,梯度会随着损失的减小而减小,使结果更加精确。在这种情况下,Huber损失就非常有用。它会由于梯度的减小而落在最小值附近。比起MSE,它对异常点更加鲁棒。因此,Huber损失结合了MSE和MAE的优点。但是,Huber损失的问题是可能需要不断调整超参数delta。
3、Log-Cosh Loss
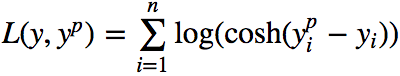
Y轴:Log-cosh损失。X轴:预测值。真值取0。

Log-cosh损失是另一种应用于回归问题中的,且比L2更平滑的的损失函数。它的计算方式是预测误差的双曲余弦的对数。
优点:对于较小的x,log(cosh(x))近似等于(x^2)/2,对于较大的x,近似等于abs(x)-log(2)。这意味着‘logcosh’基本类似于均方误差,但不易受到异常点的影响。它具有Huber损失所有的优点,但不同于Huber损失的是,Log-cosh二阶处处可微。
如何选择损失函数:许多机器学习模型如XGBoost,就是采用牛顿法来寻找最优点。而牛顿法就需要求解二阶导数(Hessian)。因此对于诸如XGBoost这类机器学习框架,损失函数的二阶可微是很有必要的。但Log-cosh损失也并非完美,其仍存在某些问题。比如误差很大的话,一阶梯度和Hessian会变成定值,这就导致XGBoost出现缺少分裂点的情况。
4、Quantile Loss

γ是所需的分位数,其值介于0和1之间。
Y轴:分位数损失。X轴:预测值。Y的真值为0。

许多商业问题的决策通常希望了解预测中的不确定性,更关注区间预测而不仅是点预测时,分位数损失函数就很有用。
使用最小二乘回归进行区间预测,基于的假设是残差(y-y_hat)是独立变量,且方差保持不变。一旦违背了这条假设,那么线性回归模型就不成立。这时,就可以使用分位数损失和分位数回归,因为即便对于具有变化方差或非正态分布的残差,基于分位数损失的回归也能给出合理的预测区间。

理解分位数损失函数:如何选取合适的分位值取决于我们对正误差和反误差的重视程度。损失函数通过分位值(γ)对高估和低估给予不同的惩罚。例如,当分位数损失函数γ=0.25时,对高估的惩罚更大,使得预测值略低于中值。

这个损失函数也可以在神经网络或基于树的模型中计算预测区间。在用Sklearn实现梯度提升树回归模型的示例中,使用分位数损失可以得到90%的预测区间。其中上限为γ=0.95,下限为γ=0.05。
回归损失函数:L1,L2,Huber,Log-Cosh,Quantile Loss的更多相关文章
- 回归损失函数2 : HUber loss,Log Cosh Loss,以及 Quantile Loss
均方误差(Mean Square Error,MSE)和平均绝对误差(Mean Absolute Error,MAE) 是回归中最常用的两个损失函数,但是其各有优缺点.为了避免MAE和MSE各自的优缺 ...
- 目标检测——Faster R_CNN使用smooth L1作为bbox的回归损失函数原因
前情提要—— 网上关于目标检测框架——faster r_cnn有太多太好的博文,这是我在组会讲述faster r_cnn这一框架时被人问到的一个点,当时没答上来,于是会下好好百度和搜索一下研究了一下这 ...
- [Scikit-learn] 1.1 Generalized Linear Models - from Linear Regression to L1&L2
Introduction 一.Scikit-learning 广义线性模型 From: http://sklearn.lzjqsdd.com/modules/linear_model.html#ord ...
- 正则化 L1 L2
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1ℓ1-norm和ℓ2ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数. L1正则化和 ...
- ML-线性模型 泛化优化 之 L1 L2 正则化
认识 L1, L2 从效果上来看, 正则化通过, 对ML的算法的任意修改, 达到减少泛化错误, 但不减少训练误差的方式的统称 训练误差 这个就损失函数什么的, 很好理解. 泛化错误 假设 我们知道 预 ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- 机器学习之正则化【L1 & L2】
前言 L1.L2在机器学习方向有两种含义:一是L1范数.L2范数的损失函数,二是L1.L2正则化 L1范数.L2范数损失函数 L1范数损失函数: L2范数损失函数: L1.L2分别对应损失函数中的绝对 ...
- 感知机、logistic回归 损失函数对比探讨
感知机.logistic回归 损失函数对比探讨 感知机 假如数据集是线性可分的,感知机学习的目标是求得一个能够将正负样本完全分开的分隔超平面 \(wx+b=0\) .其学习策略为,定义(经验)损失函数 ...
- LASSO回归与L1正则化 西瓜书
LASSO回归与L1正则化 西瓜书 2018年04月23日 19:29:57 BIT_666 阅读数 2968更多 分类专栏: 机器学习 机器学习数学原理 西瓜书 版权声明:本文为博主原创文章,遵 ...
随机推荐
- Collections用法总结
Collections是一个包装类,其中包含有各种有关集合操作的静态多态方,比如可以作用在List和Set上,此类不能实例化. 排序Integer[] array = new Integer[]{3, ...
- django post 403
同一个地址GET方式可以正常访问 在POST 提交数据过程中报403错误, 原来是1.3版本settings.py 文件中 'django.middleware.csrf.CsrfViewMiddle ...
- php发现一个神奇的函数
echo strtr('aaddffvvbbcc','avc','242'); //22ddff44bb22 echo '<br>'; echo str_replace('ad',22,' ...
- error: cannot connect to daemon解决办法
本文链接:https://blog.csdn.net/ipinki1218/article/details/80704806运行adb shell时出现error: cannot connect to ...
- gitment初始化评论跳回博客首页
表现 众所周知,gitment评论系统需要初始化以创建对应的issue,可是我在点击login with github的时候,总是跳向博客首页!WTF!什么鬼?这样不程序啊? 排查 1.F12查看lo ...
- Time类
public class Demo_Timer { /** * @param args * 计时器 * @throws InterruptedException */ public static vo ...
- i18n 语言码和对应的语言库
语言码 语言名称 af Afrikaans am Amharic ar Arabic az Azerbaijani be Belarusian bg Bulgarian bh Bihari bn Be ...
- c语言 正则表达式 IP地址
#include <stdio.h> #include <string.h> #include <regex.h> #define SUBSLEN 10 /* 匹配 ...
- 《最长的一帧》 osg3.4 osgViewer::View::init() osgViewer::Viewer::getContexts()
开始:osgViewer/ViewerBase.cpp 389行,startThreading()函数,启动线程 void ViewerBase::startThreading() { if ...
- git 关于Git每次进入都需要输入用户名和密码的问题解决
解决办法: git bash进入你的项目目录,输入: git config --global credential.helper store 然后你会在你本地生成一个文本,上边记录你的账号和密码.当然 ...