爬虫(五):PyQuery的使用
一:简介
PyQuery库是jQuery的Python实现,可以用于解析HTML网页内容,是一个非常强大又灵活的网页解析库。
--》官方文档地址
--》jQuery参考文档
二:初始化
初始化的时候一般有三种传入方式:传入字符串,传入url,传入文件。
(1):字符串初始化
html = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
print(doc('li')) ################# 运行结果
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
##################
注意:
由于PyQuery写起来比较麻烦,所以我们导入的时候都会添加别名:
from pyquery import PyQuery as pq
这里我们可以知道上述代码中的doc其实就是一个pyquery对象,我们可以通过doc可以进行元素的选择,其实这里就是一个css选择器,所以CSS选择器的规则都可以用,直接doc(标签名)就可以获取所有的该标签的内容,如果想要获取class 则doc('.class_name'),如果是id则doc('#id_name')....
(2):url初始化
from pyquery import PyQuery as pq
doc = pq(url='http://www.baidu.com')
print(doc('head'))
(3):文件初始化
from pyquery import PyQuery as pq
doc = pq(filename='demo.html')
print(doc('li'))
注意:pq()这里可以传入url参数也可以传入文件参数,当然这里的文件通常是一个html文件,例如:pq(filename='index.html')
三:基本的CSS选择器
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
print(doc('#container .list li'))
注意:
doc('#container .list li'),这里的三者之间的并不是必须要挨着,只要是层级关系就可以,下面是常用的CSS选择器方法:
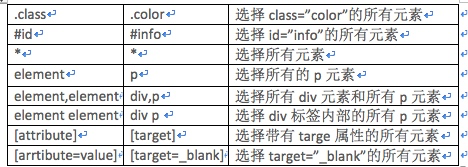
(1):查找元素
子元素:
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
print(type(items))
print(items)
lis = items.find('li')
print(type(lis))
print(lis) #####################运行结果
<class 'pyquery.pyquery.PyQuery'>
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul> <class 'pyquery.pyquery.PyQuery'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
##############################
从结果里我们也可以看出通过pyquery找到结果其实还是一个pyquery对象,可以继续查找,上述中的代码中的items.find('li') 则表示查找ul里的所有的li标签
当然这里通过children可以实现同样的效果,并且通过.children方法得到的结果也是一个pyquery对象
li = items.children()
print(type(li))
print(li) # 在children里也可以用CSS选择器
li2 = items.children('.active')
print(li2)
父元素:
通过.parent就可以找到父元素的内容:
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
container = items.parent()
print(type(container))
print(container)
通过.parents就可以找到祖先节点的内容:
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
parents = items.parents()
print(type(parents))
print(parents) # 通过.parents查找的时候也可以添加css选择器来进行内容的筛选
兄弟元素:
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.list .item-0.active')
print(li.siblings())
代码中doc('.list .item-0.active') 中的.tem-0和.active是紧挨着的,所以表示是并的关系,这样满足条件的就剩下一个了:thired item的那个标签了
这样在通过.siblings就可以获取所有的兄弟标签,当然这里是不包括自己的
同样的在.siblings()里也是可以通过CSS选择器进行筛选
(2):遍历
单个元素:
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li) lis = doc('li').items() # 通过items()可以得到一个生成器,并且通过循环得到每个元素
print(type(lis))
for li in lis:
print(type(li))
print(li)
三:获取信息
获取属性:
pyquery对象.attr(属性名)
pyquery对象.attr.属性名
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.attr('href'))
print(a.attr.href) # 获得属性值的时候可以直接a.attr(属性名)或者a.attr.属性名
获取文本:
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.text()) # 通过.text()就可以获取文本信息
获取html:
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
print(li.html()) # 通过.html()的方式可以获取当前标签所包含的html信息
四:DOM操作
addClass、removeClass
通过这两个操作可以添加和删除属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.removeClass('active')
print(li)
li.addClass('active')
print(li)
attr,css
同样的我们可以通过attr给标签添加和修改属性,
如果之前没有该属性则是添加,如果有则是修改
我们也可以通过css添加一些css属性,这个时候,标签的属性里会多一个style属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.attr('name', 'link')
print(li)
li.css('font-size', '14px')
print(li)
remove
有时候我们获取文本信息的时候可能并列的会有一些其他标签干扰,这个时候通过remove就可以将无用的或者干扰的标签直接删除,从而方便操作
html = '''
<div class="wrap">
Hello, World
<p>This is a paragraph.</p>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
wrap = doc('.wrap')
print(wrap.text())
wrap.find('p').remove()
print(wrap.text())
五:官方api整理-->api
使用方法
from pyquery import PyQuery as pq
1.可加载一段HTML字符串,或一个HTML文件,或是一个url地址,
例:
d=pq("<html><title>hello</title></html>")
d=pq(filename=path_to_html_file)
d=pq(url='http://www.baidu.com')注意:此处url似乎必须写全
2.html()和text() ——获取相应的HTML块或文本块,
例:
p=pq("<head><title>hello</title></head>")
p('head').html()#返回<title>hello</title>
p('head').text()#返回hello
3.根据HTML标签来获取元素,
例:
d=pq('<div><p>test 1</p><p>test 2</p></div>')
d('p')#返回[<p>,<p>]
print d('p')#返回<p>test 1</p><p>test 2</p>
print d('p').html()#返回test 1
注意:当获取到的元素不只一个时,html()、text()方法只返回首个元素的相应内容块
4.eq(index) ——根据给定的索引号得到指定元素
接上例,若想得到第二个p标签内的内容,则可以:
print d('p').eq(1).html() #返回test 2
5.filter() ——根据类名、id名得到指定元素,例:
d=pq("<div><p id='1'>test 1</p><p class='2'>test 2</p></div>")
d('p').filter('#1') #返回[<p#1>]
d('p').filter('.2') #返回[<p.2>]
6.find() ——查找嵌套元素,例:
d=pq("<div><p id='1'>test 1</p><p class='2'>test 2</p></div>")
d('div').find('p')#返回[<p#1>, <p.2>]
d('div').find('p').eq(0)#返回[<p#1>]
7.直接根据类名、id名获取元素,例:
d=pq("<div><p id='1'>test 1</p><p class='2'>test 2</p></div>")
d('#1').html()#返回test 1
d('.2').html()#返回test 2
8.获取属性值,例:
d=pq("<p id='my_id'><a href='http://hello.com'>hello</a></p>")
d('a').attr('href')#返回http://hello.com
d('p').attr('id')#返回my_id
9.修改属性值,例:
d('a').attr('href', 'http://baidu.com')把href属性修改为了baidu
10.addClass(value) ——为元素添加类,例:
d=pq('<div></div>')
d.addClass('my_class')#返回[<div.my_class>]
11.hasClass(name) #返回判断元素是否包含给定的类,例:
d=pq("<div class='my_class'></div>")
d.hasClass('my_class')#返回True
12.children(selector=None) ——获取子元素,例:
d=pq("<span><p id='1'>hello</p><p id='2'>world</p></span>")
d.children()#返回[<p#1>, <p#2>]
d.children('#2')#返回[<p#2>]
13.parents(selector=None)——获取父元素,例:
d=pq("<span><p id='1'>hello</p><p id='2'>world</p></span>")
d('p').parents()#返回[<span>]
d('#1').parents('span')#返回[<span>]
d('#1').parents('p')#返回[]
14.clone() ——返回一个节点的拷贝
15.empty() ——移除节点内容
16.nextAll(selector=None) ——返回后面全部的元素块,例:
d=pq("<p id='1'>hello</p><p id='2'>world</p><img scr='' />")
d('p:first').nextAll()#返回[<p#2>, <img>]
d('p:last').nextAll()#返回[<img>]
17.not_(selector) ——返回不匹配选择器的元素,例:
d=pq("<p id='1'>test 1</p><p id='2'>test 2</p>")
d('p').not_('#2')#返回[<p#1>]
爬虫(五):PyQuery的使用的更多相关文章
- Python逆向爬虫之pyquery,非常详细
系列目录 Python逆向爬虫之pyquery pyquery是一个类似jquery的python库,它实现能够在xml文档中进行jQuery查询,pyquery使用lxml解析器进行快速在xml和h ...
- Python爬虫之PyQuery使用(六)
Python爬虫之PyQuery使用 PyQuery简介 pyquery能够通过选择器精确定位 DOM 树中的目标并进行操作.pyquery相当于jQuery的python实现,可以用于解析HTML网 ...
- 爬虫之PyQuery的base了解
爬虫之PyQuery的base了解 pyquery库是jQuery的Python实现,能够以jQuery的语法来操作解析 HTML 文档,易用性和解析速度都很好,和它差不多的还有BeautifulSo ...
- # Python3微博爬虫[requests+pyquery+selenium+mongodb]
目录 Python3微博爬虫[requests+pyquery+selenium+mongodb] 主要技术 站点分析 程序流程图 编程实现 数据库选择 代理IP测试 模拟登录 获取用户详细信息 获取 ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- 爬虫之pyquery库
官方文档:https://pyquery.readthedocs.io/en/latest/ PyQuery是一个强大又灵活的网页解析库.如果你觉得正则写起来太麻烦.BeautifulSoup语法太难 ...
- python爬虫神器PyQuery的使用方法
你是否觉得 XPath 的用法多少有点晦涩难记呢? 你是否觉得 BeautifulSoup 的语法多少有些悭吝难懂呢? 你是否甚至还在苦苦研究正则表达式却因为少些了一个点而抓狂呢? 你是否已经有了一些 ...
- python爬虫(五)_urllib2:Get请求和Post请求
本篇将介绍urllib2的Get和Post方法,更多内容请参考:python学习指南 urllib2默认只支持HTTP/HTTPS的GET和POST方法 urllib.urlencode() urll ...
- Python爬虫之pyquery库的基本使用
# 字符串初始化 html = ''' <div> <ul> <li class = "item-0">first item</li> ...
- python爬虫之PyQuery的基本使用
PyQuery库也是一个非常强大又灵活的网页解析库,如果你有前端开发经验的,都应该接触过jQuery,那么PyQuery就是你非常绝佳的选择,PyQuery 是 Python 仿照 jQuery 的严 ...
随机推荐
- PowerBuilder学习笔记之删除和加载PBL文件的方法
删除PBL目录的方法:直接点删除键删除 加载PBL文件的方法:点Browse按钮选择PBL文件
- oracle DBA操作
sqlplus sys/tiger as sysdba; alter user scott account unlock; 用户已更改 切换用户:conn scott/tiger as sysdba ...
- Linux Nginx的权限——访问本地目录报错403
在安装好FastDFS并成功上传图片文件后,根据FastDFS返回的文件地址无法通过HTTP(即浏览器)访问到,报错404或者403. 不管是Error 404还是Error 403,基本都是Ngin ...
- Excel VBA 入门基础
Private Sub RegExp_Replace() Dim RegExp As Object Dim SearchRange As Range, Cell As Range '此处定义正则表达式 ...
- spark 机器学习 ALS原理(一)
1.线性回归模型线性回归是统计学中最常用的算法,当你想表示两个变量间的数学关系时,就可以用线性回归.当你使用它时,你首先假设输出变量(相应变量.因变量.标签)和预测变量(自变量.解释变量.特征)之间存 ...
- iveiw DatePicker 只能选择本月之前的日期,本月包括之后都不能选择
日期判断只能选择本月之前的日期 <DatePicker type="date" :options="options3" format="yyyy ...
- 基于CentOS构建企业镜像站
参考:How to Setup Local HTTP Yum Repository on CentOS 7 实验环境 CentOS7 1804 步骤一:安装Nginx Web Server 最小化安装 ...
- 部署Nginx网站服务实现访问状态统计以及访问控制功能
原文:https://blog.51cto.com/11134648/2130987 Nginx专为性能优化而开发,最知名的优点是它的稳定性和低系统资源消耗,以及对HTTP并发连接的高处理能力,单个物 ...
- 锁、threading.local、线程池
一.锁 Lock(1次放1个) 什么时候用到锁: 线程安全,多线程操作时,内部会让所有线程排队处理.如:list.dict.queue 线程不安全, import threading import t ...
- psql主主复制
主主是mysql的概念,通常在mysql中为保证事务一致也是一台主写,一台做读.pg主从可以互为切换 之前没做数据库部署这部分,一个同事离职暂时没人,接受过来的!mysql做的是主主复制,我理解是可以 ...