Python新手爬虫一:爬取影片名称评分等
豆瓣网站:https://movie.douban.com/chart
先上最后的代码:
from bs4 import BeautifulSoup
from lxml import html
import xml
import requests
from fake_useragent import UserAgent #ua库
import xlwt #表格模块 n = [] #存放电影名称
p = [] #存放电影评分 def get_url():
url = "https://movie.douban.com/chart"
ua = UserAgent()
headers={'user-agent':ua.random}
f = requests.get(url,headers=headers) #Get该网页从而获取该html内容
soup = BeautifulSoup(f.text,'lxml') #用lxml解析器解析该网页的内容, 好像f.content也是返回的html for k in soup.find_all('div',class_='pl2'): #找到div并且class为pl2的标签
b = k.find('a') #在每个对应div标签下找a标签
n.append(b.get_text()) #取标签 a 下的文字,并添加到 n 列表中 for i in soup.find_all('div',class_='star clearfix'):
c = i.find_all('span') #在每个对应div标签下找span标签,会发现,一个a里面有四组span
t = c[1].string,c[2].string #取相对应span中的字符串,评分和评价人数
p.append(t) #添加到 p 列表中 get_url() #获取数据 style = xlwt.XFStyle() #初始化样式模板
font = xlwt.Font() #初始化字体模板
pattern = xlwt.Pattern() #初始化背景颜色模板
alignment = xlwt.Alignment() #初始化单元格格式模板 font.name = 'Times New Roman' #指定字体
font.bold = True #加黑
font.height = 20*14 #字体 pattern.pattern = xlwt.Pattern.SOLID_PATTERN # 设置背景颜色的模式
pattern.pattern_fore_colour = 2 # 背景颜色 alignment.horz = 0x02 # 0x01(左端对齐)、0x02(水平方向上居中对齐)、0x03(右端对齐)
alignment.vert = 0x01 # 0x00(上端对齐)、 0x01(垂直方向上居中对齐)、0x02(底端对齐)
#alignment.wrap = 1 # 设置自动换行 style.font = font #应用到style中
style.pattern = pattern #
style.alignment = alignment #应用到style中 workbook = xlwt.Workbook()
worksheel = workbook.add_sheet('豆瓣电影排行榜') #创建一个新表格
worksheel.write(0,0,'电影名',style) #填写行、列、值
worksheel.write(0,1,'评分',style) for x in range(1,11):
for y in range(0,2):
if y == 0:
worksheel.write(x,y,label=n[x-1])
elif y == 1:
worksheel.write(x,y,label=p[x-1]) workbook.save(r"C:\Users\fan\Desktop\豆瓣影评.xls") #创建excel表
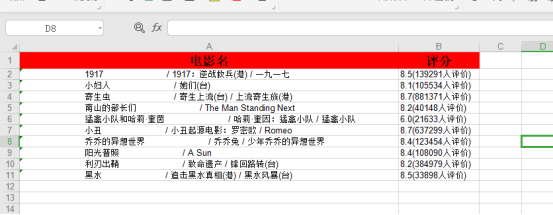
效果图:
思路:
1、进入网页—>F12—>右击影名—>检查—>查看相对应的html代码
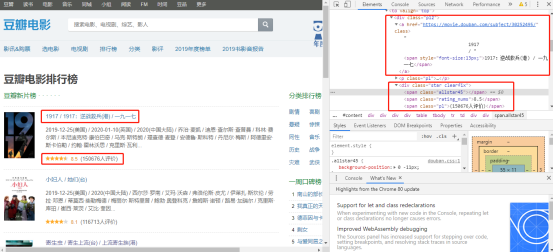
发现影名是存在<div class="pl2">标签下的<a>标签中,使用requests+BeautifulSoup库获取
评分和评价人数存储在<div class="star clearfix">下的<span>标签中。
所涉及到的库,全部是前文《爬虫常用库》中有介绍。
Python新手爬虫一:爬取影片名称评分等的更多相关文章
- 利用python的爬虫技术爬取百度贴吧的帖子
在爬取糗事百科的段子后,我又在知乎上找了一个爬取百度贴吧帖子的实例,为了巩固提升已掌握的爬虫知识,于是我打算自己也做一个. 实现目标:1,爬取楼主所发的帖子 2,显示所爬去的楼层以及帖子题目 3,将爬 ...
- python网络爬虫《爬取get请求的页面数据》
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在python3中的为urllib.request和urllib. ...
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- 初识python 之 爬虫:爬取双色球中奖号码信息
人生还是要有梦想的,毕竟还有python.比如,通过python来搞一搞彩票(双色球).注:此文仅用于python学习,结果仅作参考.用到知识点:1.爬取网页基础数据2.将数据写入excel文件3.将 ...
- Python网络爬虫_爬取Ajax动态加载和翻页时url不变的网页
1 . 什么是 AJAX ? AJAX = 异步 JavaScript 和 XML. AJAX 是一种用于创建快速动态网页的技术. 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新 ...
- python之爬虫(爬取.ts文件并将其合并为.MP4文件——以及一些异常的注意事项)
//20200115 最近在看“咱们裸熊——we bears”第一季和第三季都看完了,单单就第二季死活找不到,只有腾讯有资源,但是要vip……而且还是国语版……所以就瞄上了一个视频网站——可以在线观看 ...
- Python学习 —— 爬虫入门 - 爬取Pixiv每日排行中的图片
更新于 2019-01-30 16:30:55 我另外写了一个面向 pixiv 的库:pixiver 支持通过作品 ID 获取相关信息.下载等,支持通过日期浏览各种排行榜(包括R-18),支持通过 p ...
- 初识python 之 爬虫:爬取中国天气网数据
用到模块: 获取网页并解析:import requests,html5lib from bs4 import BeautifulSoup 使用pyecharts的Bar可视化工具"绘制图表& ...
- 初识python 之 爬虫:爬取某网站的壁纸图片
用到的主要知识点:requests.get 获取网页HTMLetree.HTML 使用lxml解析器解析网页xpath 使用xpath获取网页标签信息.图片地址request.urlretrieve ...
- Python网络爬虫 | Scrapy爬取妹子图网站全站照片
根据现有的知识,写了一个下载妹子图(meizitu.com)Scrapy脚本,把全站两万多张照片下载到了本地. 网站的分析 网页的网址分析 打开网站,发现网页的网址都是以 http://www.mei ...
随机推荐
- require模块化 AMD和CMD
在CommonJS中,有一个全局性方法require(),用于加载模块.假定有一个数学模块math.js,就可以像下面这样加载. 1 var math = require('math'); 然后,就可 ...
- 常用 Java 组件和框架分类
WEB 容器 Tomcat https://tomcat.apache.org/ Jetty https://www.jetty.com/ JBoss https://www.jboss.org/ R ...
- Django生成数据库表时报错 __init__() missing 1 required positional argument: 'on_delete'
原因: 在django2.0后,定义外键和一对一关系的时候需要加上on_delete选项,此参数为了避免两个表里的数据不一致问题,不然会报错 例如: owner=models.ForeignKey(U ...
- opc ua设备数据 转MQTT项目案例
目录 1 案例说明 1 2 VFBOX网关工作原理 1 3 准备工作 2 4 配置VFBOX网关采集OPC UA的数据 2 5 用MQTT协议转发数据 4 6 配置参数说明 4 7 上报内容配置 5 ...
- [oeasy]python0140_导入_import_from_as_namespace_
导入import 回忆上次内容 上次学习了 try except 注意要点 半角冒号 缩进 输出错误信息 有错就报告 不要隐瞒 否则找不到出错位置 还可以用traceback把 系统报错信息原 ...
- .NET单元测试使用AutoFixture按需填充属性的几种方式,以及最佳实践
AutoFixture是一个.NET库,旨在简化单元测试中的数据设置过程.通过自动生成测试数据,它帮助开发者减少测试代码的编写量,使得单元测试更加简洁.易读和易维护.AutoFixture可以用于任何 ...
- 假期小结3Hadoop学习
学习Hadoop是一个很好的选择,因为它是大数据处理和分析领域最流行的框架之一.Hadoop提供了可靠.可扩展的分布式数据处理能力,适用于处理大规模数据和构建可靠的数据管道. 在学习Hadoop时,以 ...
- Nuxt.js必读:轻松掌握运行时配置与 useRuntimeConfig
title: Nuxt.js必读:轻松掌握运行时配置与 useRuntimeConfig date: 2024/7/29 updated: 2024/7/29 author: cmdragon exc ...
- 全网最适合入门的面向对象编程教程:29 类和对象的Python实现-断言与防御性编程和help函数的使用
全网最适合入门的面向对象编程教程:29 类和对象的 Python 实现-断言与防御性编程和 help 函数的使用 摘要: 在 Python 中,断言是一种常用的调试工具,它允许程序员编写一条检查某个条 ...
- 【DataBase】SQL优化案例:其一
原始SQL: 这里想做的事情就是查询一周的一个计算值 可以理解为报表的那种 主表 t_wechat_clue 生产库上200万数据量 然后需要联表一些限制条件 SELECT IFNULL(SUM((C ...