Python3爬取百度百科(配合PHP)
用PHP写了一个网页,可以获取百度百科词条。

那么通过Python来爬取,只需要不断向这个网页POST数据,获取返回值就可以了。由于是我自己的网页,保存返回值我也让PHP在服务器端来完成了,所以Python的任务只需要不断向服务器POST数据。
那么POST什么数据呢?暂时找到了一个名词大全的网页。http://cidian.911cha.com/cixing_mingci.html

足足20页的名词,足够作为名词POST数据的来源了。
下面是获取各种名词的python代码:
zd = []
for i in range(20):
url = 'http://cidian.911cha.com/cixing_mingci_p'+str(i+1)+'.html'
webpage = urllib.request.urlopen(url)
data = webpage.read()
data = data.decode('utf-8')
'''
file = open('d:/Pythoncode/simplecodes/0.html','w',encoding='utf-8')
file.write(data)
file.close()
'''
k = re.findall(r'target="_blank">.+?</a>',data)
cou = 0
cx=[]
for i in k :
if cou%2==0:
cx.append(i)
cou= cou+1
for it in cx:
m = re.search(r'target="_blank">(.*?)</a>',it)
iturl = m.group(1)
zd.append(iturl)
现在字典里已经保存了足足20页的名词,下一步就是要向服务器POST数据,保存词条内容了。
for i in zd :
s=i
print(i)
s=urllib.parse.quote(s)
url = "http://www.selflink.cn/xiaobaike/?name=%s"%(s)
try:
urllib.request.urlopen(url,timeout=5)
except Exception as e:
pass
python开始运行了……
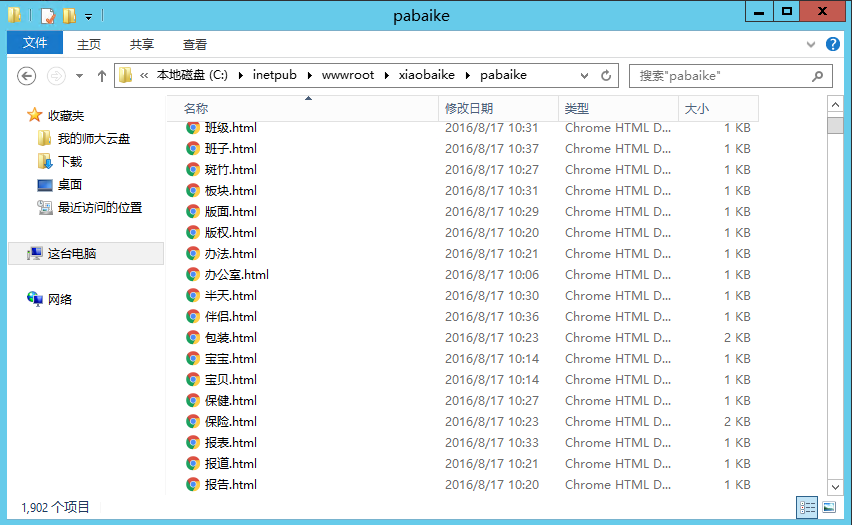
最后爬到了1902个词条内容0.0
获取了这么多词条有什么用呢?……我也不知道,不过,获取知识也许是人工智能的开始吧^_^
Python3爬取百度百科(配合PHP)的更多相关文章
- Python开发简单爬虫(二)---爬取百度百科页面数据
一.开发爬虫的步骤 1.确定目标抓取策略: 打开目标页面,通过右键审查元素确定网页的url格式.数据格式.和网页编码形式. ①先看url的格式, F12观察一下链接的形式;② 再看目标文本信息的标签格 ...
- Python——爬取百度百科关键词1000个相关网页
Python简单爬虫——爬取百度百科关键词1000个相关网页——标题和简介 网站爬虫由浅入深:慢慢来 分析: 链接的URL分析: 数据格式: 爬虫基本架构模型: 本爬虫架构: 源代码: # codin ...
- 爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释 我的第一个想法是做一个数据库,把常用的词语和词语的解释放到数据库里面,当用户查询时直接读取数据库结果 但是自己又没有心思做这样一个数 ...
- python简单爬虫 用beautifulsoup爬取百度百科词条
目标:爬取“湖南大学”百科词条并处理数据 需要获取的数据: 源代码: <div class="basic-info cmn-clearfix"> <dl clas ...
- java 如何爬取百度百科词条内容(java如何使用webmagic爬取百度词条)
这是老师所布置的作业 说一下我这里的爬去并非能把百度词条上的内容一字不漏的取下来(而是它分享链接的一个主要内容概括...)(他的主要内容我爬不到 也不想去研究大家有好办法可以call me) 例如 互 ...
- python爬虫—爬取百度百科数据
爬虫框架:开发平台 centos6.7 根据慕课网爬虫教程编写代码 片区百度百科url,标题,内容 分为4个模块:html_downloader.py 下载器 html_outputer.py 爬取数 ...
- python3爬取百度图片(2018年11月3日有效)
最终目的:能通过输入关键字进行搜索,爬取相应的图片存储到本地或者数据库 首先打开百度图片的网站,搜索任意一个关键字,比如说:水果,得到如下的界面 分析: 1.百度图片搜索结果的页面源代码不包含需要提取 ...
- python简单爬虫爬取百度百科python词条网页
目标分析:目标:百度百科python词条相关词条网页 - 标题和简介 入口页:https://baike.baidu.com/item/Python/407313 URL格式: - 词条页面URL:/ ...
- R语言爬虫:爬取百度百科词条
抓取目标:抓取花儿与少年的百度百科中成员信息 url <- "http://baike.baidu.com/item/%E8%8A%B1%E5%84%BF%E4%B8%8E%E5%B0 ...
随机推荐
- I.MX6 Android U-blox miniPCI 4G porting
/************************************************************************** * I.MX6 Android U-blox m ...
- ubuntu鼠标突然不能使用的解决方法
今天发现鼠标(usb即插即用)不能用了,最后发现需要接通充电才可以!!!用电池的时候居然不可以用鼠标?
- 一个好用的hibernate泛型dao
以前从springside2.0上搞下来的很好用的,基本实现dao零编码只要配置xml文件就行了. 先看图: 一共4层,com.demonstration.hibernate.basedao是我加的用 ...
- Google服务背后的天文数字
每天当我们在互联网上驰骋的时候,在背后支撑网页.应用.服务运转的就是各种编程语言和代码.无论是Gmail确认收件箱还是执行关键词搜索都需要大量的代码,但是你知道Google的各项互联网服务合起来需要多 ...
- MySQL数据库分布式事务XA优缺点与改进方案
1 MySQL 外部XA分析 1.1 作用分析 MySQL数据库外部XA可以用在分布式数据库代理层,实现对MySQL数据库的分布式事务支持,例如开源的代理工具:ameoba[4],网易的DDB,淘宝的 ...
- 回调函数、Java接口回调 总结
谈到回调,我们得先从回调函数说起,什么叫回调函数呢? 回调函数是什么? 百度百科的解释:回调函数就是一个通过函数指针调用的函数.如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用为调用 ...
- java 使用相对路径读取文件
java 使用相对路径读取文件 1.java project环境,使用java.io用相对路径读取文件的例子: *目录结构: DecisionTree |___src ...
- HDU5787 K-wolf Number 数位dp
分析:赛场上也知道是裸的数位dp,但是无奈刷数位dp题刷的太少了,并不能写出来 一点感想:赛后补题,看了题解的map记录状态,一脸蒙逼,也是非常的不爽,然后想看别人写的,不是递归就是写的比较乱 而且我 ...
- 不知道帐号密码的情况下完全重装Mac Min的OS X10.7系统
现状: 1.原系统OS X 10.7 2.老账号不知道密码 3.Mac小盒子 目的: 1.删除老账号 2.更新系统到10.9以上 尝试过程1: 1.按住option键 + 开机 2.选择“磁盘工具” ...
- ASP.NET Session丢失的解决方案
正常操作情况下会有ASP.NET Session丢失的情况出现.因为程序是在不停的被操作,排除Session超时的可能.另外,Session超时时间被设定成60分钟,不会这么快就超时的.现在我就把原因 ...