Flume 简介及基本使用
一、Flume简介
Apache Flume是一个分布式,高可用的数据收集系统。它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集。Flume 分为 NG 和 OG (1.0 之前)两个版本,NG在OG的基础上进行了完全的重构,是目前使用最为广泛的版本。下面的介绍均以NG为基础。
二、Flume架构和基本概念
下图为Flume的基本架构图:
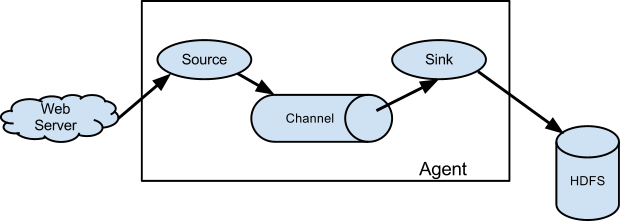
2.1 基本架构
外部数据源以特定格式向Flume发送events (事件),当source接收到events时,它将其存储到一个或多个channel,channe会一直保存events直到它被sink所消费。sink的主要功能从channel中读取events,并将其存入外部存储系统或转发到下一个source,成功后再从channel中移除events。
2.2 基本概念
1. Event
Evnet是Flume NG数据传输的基本单元。类似于JMS和消息系统中的消息。一个Evnet由标题和正文组成:前者是键/值映射,后者是任意字节数组。
2. Source
数据收集组件,从外部数据源收集数据,并存储到Channel中。
3. Channel
Channel是源和接收器之间的管道,用于临时存储数据。可以是内存或持久化的文件系统:
Memory Channel: 使用内存,优点是速度快,但数据可能会丢失(如突然宕机);File Channel: 使用持久化的文件系统,优点是能保证数据不丢失,但是速度慢。
4. Sink
Sink的主要功能从Channel中读取Evnet,并将其存入外部存储系统或将其转发到下一个Source,成功后再从Channel中移除Event。
5. Agent
是一个独立的(JVM)进程,包含Source、 Channel、 Sink等组件。
2.3 组件种类
Flume中的每一个组件都提供了丰富的类型,适用于不同场景:
- Source类型 :内置了几十种类型,如
Avro Source,Thrift Source,Kafka Source,JMS Source; - Sink类型 :
HDFS Sink,Hive Sink,HBaseSinks,Avro Sink等; - Channel类型 :
Memory Channel,JDBC Channel,Kafka Channel,File Channel等。
对于Flume的使用,除非有特别的需求,否则通过组合内置的各种类型的Source,Sink和Channel就能满足大多数的需求。在 Flume官网上对所有类型组件的配置参数均以表格的方式做了详尽的介绍,并附有配置样例;同时不同版本的参数可能略有所不同,所以使用时建议选取官网对应版本的User Guide作为主要参考资料。
三、Flume架构模式
Flume 支持多种架构模式,分别介绍如下
3.1 multi-agent flow

Flume支持跨越多个Agent的数据传递,这要求前一个Agent的Sink和下一个Agent的Source都必须是Avro类型,Sink指向Source所在主机名(或IP地址)和端口(详细配置见下文案例三)。
3.2 Consolidation
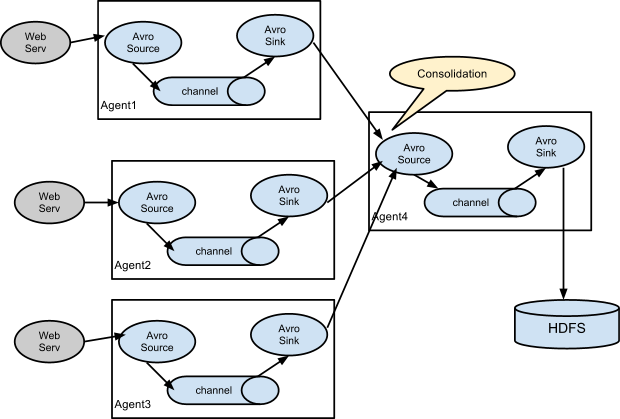
日志收集中常常存在大量的客户端(比如分布式web服务),Flume支持使用多个Agent分别收集日志,然后通过一个或者多个Agent聚合后再存储到文件系统中。
3.3 Multiplexing the flow
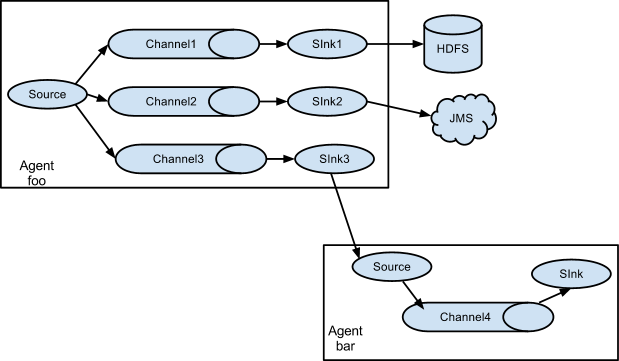
Flume支持从一个Source向多个Channel,也就是向多个Sink传递事件,这个操作称之为Fan Out(扇出)。默认情况下Fan Out是向所有的Channel复制Event,即所有Channel收到的数据都是相同的。同时Flume也支持在Source上自定义一个复用选择器(multiplexing selector) 来实现自定义的路由规则。
四、Flume配置格式
Flume配置通常需要以下两个步骤:
- 分别定义好Agent的Sources,Sinks,Channels,然后将Sources和Sinks与通道进行绑定。需要注意的是一个Source可以配置多个Channel,但一个Sink只能配置一个Channel。基本格式如下:
<Agent>.sources = <Source>
<Agent>.sinks = <Sink>
<Agent>.channels = <Channel1> <Channel2>
# set channel for source
<Agent>.sources.<Source>.channels = <Channel1> <Channel2> ...
# set channel for sink
<Agent>.sinks.<Sink>.channel = <Channel1>
- 分别定义Source,Sink,Channel的具体属性。基本格式如下:
<Agent>.sources.<Source>.<someProperty> = <someValue>
# properties for channels
<Agent>.channel.<Channel>.<someProperty> = <someValue>
# properties for sinks
<Agent>.sources.<Sink>.<someProperty> = <someValue>
五、Flume的安装部署
为方便大家后期查阅,本仓库中所有软件的安装均单独成篇,Flume的安装见:
六、Flume使用案例
介绍几个Flume的使用案例:
- 案例一:使用Flume监听文件内容变动,将新增加的内容输出到控制台。
- 案例二:使用Flume监听指定目录,将目录下新增加的文件存储到HDFS。
- 案例三:使用Avro将本服务器收集到的日志数据发送到另外一台服务器。
6.1 案例一
需求: 监听文件内容变动,将新增加的内容输出到控制台。
实现: 主要使用Exec Source配合tail命令实现。
1. 配置
新建配置文件exec-memory-logger.properties,其内容如下:
#指定agent的sources,sinks,channels
a1.sources = s1
a1.sinks = k1
a1.channels = c1
#配置sources属性
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /tmp/log.txt
a1.sources.s1.shell = /bin/bash -c
#将sources与channels进行绑定
a1.sources.s1.channels = c1
#配置sink
a1.sinks.k1.type = logger
#将sinks与channels进行绑定
a1.sinks.k1.channel = c1
#配置channel类型
a1.channels.c1.type = memory
2. 启动
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/exec-memory-logger.properties \
--name a1 \
-Dflume.root.logger=INFO,console
3. 测试
向文件中追加数据:

控制台的显示:

6.2 案例二
需求: 监听指定目录,将目录下新增加的文件存储到HDFS。
实现:使用Spooling Directory Source和HDFS Sink。
1. 配置
#指定agent的sources,sinks,channels
a1.sources = s1
a1.sinks = k1
a1.channels = c1
#配置sources属性
a1.sources.s1.type =spooldir
a1.sources.s1.spoolDir =/tmp/logs
a1.sources.s1.basenameHeader = true
a1.sources.s1.basenameHeaderKey = fileName
#将sources与channels进行绑定
a1.sources.s1.channels =c1
#配置sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H/
a1.sinks.k1.hdfs.filePrefix = %{fileName}
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#将sinks与channels进行绑定
a1.sinks.k1.channel = c1
#配置channel类型
a1.channels.c1.type = memory
2. 启动
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/spooling-memory-hdfs.properties \
--name a1 -Dflume.root.logger=INFO,console
3. 测试
拷贝任意文件到监听目录下,可以从日志看到文件上传到HDFS的路径:
# cp log.txt logs/
查看上传到HDFS上的文件内容与本地是否一致:
# hdfs dfs -cat /flume/events/19-04-09/13/log.txt.1554788567801

6.3 案例三
需求: 将本服务器收集到的数据发送到另外一台服务器。
实现:使用avro sources和avro Sink实现。
1. 配置日志收集Flume
新建配置netcat-memory-avro.properties,监听文件内容变化,然后将新的文件内容通过avro sink发送到hadoop001这台服务器的8888端口:
#指定agent的sources,sinks,channels
a1.sources = s1
a1.sinks = k1
a1.channels = c1
#配置sources属性
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /tmp/log.txt
a1.sources.s1.shell = /bin/bash -c
a1.sources.s1.channels = c1
#配置sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop001
a1.sinks.k1.port = 8888
a1.sinks.k1.batch-size = 1
a1.sinks.k1.channel = c1
#配置channel类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
2. 配置日志聚合Flume
使用 avro source监听hadoop001服务器的8888端口,将获取到内容输出到控制台:
#指定agent的sources,sinks,channels
a2.sources = s2
a2.sinks = k2
a2.channels = c2
#配置sources属性
a2.sources.s2.type = avro
a2.sources.s2.bind = hadoop001
a2.sources.s2.port = 8888
#将sources与channels进行绑定
a2.sources.s2.channels = c2
#配置sink
a2.sinks.k2.type = logger
#将sinks与channels进行绑定
a2.sinks.k2.channel = c2
#配置channel类型
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
3. 启动
启动日志聚集Flume:
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/avro-memory-logger.properties \
--name a2 -Dflume.root.logger=INFO,console
在启动日志收集Flume:
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/netcat-memory-avro.properties \
--name a1 -Dflume.root.logger=INFO,console
这里建议按以上顺序启动,原因是avro.source会先与端口进行绑定,这样avro sink连接时才不会报无法连接的异常。但是即使不按顺序启动也是没关系的,sink会一直重试,直至建立好连接。
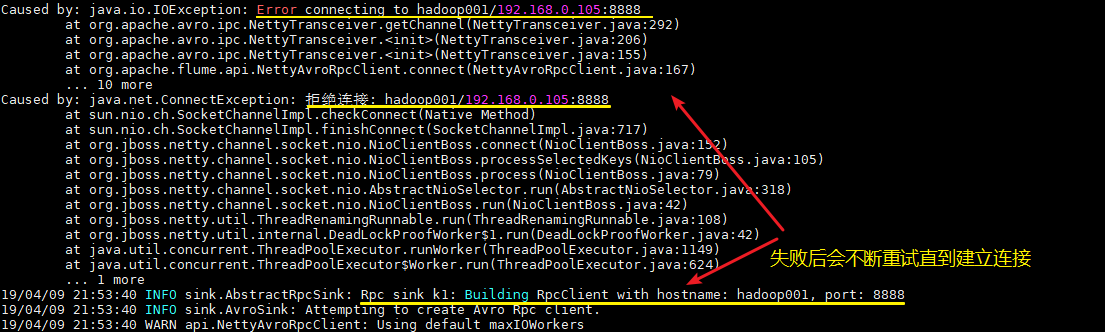
4.测试
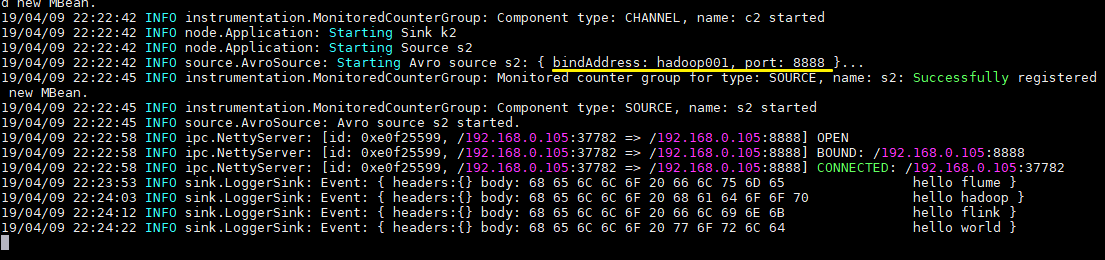
向文件tmp/log.txt中追加内容:

可以看到已经从8888端口监听到内容,并成功输出到控制台:
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Flume 简介及基本使用的更多相关文章
- Flume简介与使用(二)——Thrift Source采集数据
Flume简介与使用(二)——Thrift Source采集数据 继上一篇安装Flume后,本篇将介绍如何使用Thrift Source采集数据. Thrift是Google开发的用于跨语言RPC通信 ...
- Flume简介与使用(一)——Flume安装与配置
Flume简介与使用(一)——Flume安装与配置 Flume简介 Flume是一个分布式的.可靠的.实用的服务——从不同的数据源高效的采集.整合.移动海量数据. 分布式:可以多台机器同时运行采集数据 ...
- 入门大数据---Flume 简介及基本使用
一.Flume简介 Apache Flume 是一个分布式,高可用的数据收集系统.它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集.Flume 分为 NG 和 OG ( ...
- Apache Flume 简介
转自:http://blog.163.com/guaiguai_family/blog/static/20078414520138100562883/ Flume 是 Cloudera 公司开源出来的 ...
- Flume简介与使用(三)——Kafka Sink消费数据之Kafka安装
前面已经介绍了如何利用Thrift Source生产数据,今天介绍如何用Kafka Sink消费数据. 其实之前已经在Flume配置文件里设置了用Kafka Sink消费数据 agent1.sinks ...
- Flume简介及安装
Hadoop业务的大致开发流程以及Flume在业务中的地位: 从Hadoop的业务开发流程图中可以看出,在大数据的业务处理过程中,对于数据的采集是十分重要的一步,也是不可避免的一步,从而引出我们本文的 ...
- flume简介
组件介绍: 代理 Flume Agent Flume内部有一个或者多个Agent 每一个Agent是一个独立的守护进程(JVM) 从客户端哪儿接收收集,或者从其他的Agent哪儿接收,然后迅速的将获取 ...
- Flume简介及使用
一.Flume概述 1)官网地址 http://flume.apache.org/ 2)日志采集工具 Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据.它具有基于流数据 ...
- Apache Flume简介及安装部署
概述 Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的软件. Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目 ...
随机推荐
- eclise配置tomcat出现服务Tomcat version 6.0 only supports J2EE 1.2, 1.3, 1.4 and Java EE 5 Web modules
当部署项目Tomcat version 6.0 only supports J2EE 1.2, 1.3, 1.4, 1.5 and Java EE 5 Web modules错;解决方案,如下面: 空 ...
- Angular路由守卫 canActivate
作用 canActivate 控制是否允许进入路由. canActivateChild 等同 canActivate,只不过针对是所有子路由. 关键代码 创建路由守卫 import { Injecta ...
- LeetCode 36 Sudoku Solver
Write a program to solve a Sudoku puzzle by filling the empty cells. Empty cells are indicated by th ...
- ABP缓存示例
private readonly ICacheManager _cacheManager; public ProgrammeManage(ICacheManager cacheManager) { _ ...
- Bootstrap路径导航
@{ Layout = null;}<!DOCTYPE html><html><head> <meta name="viewport&q ...
- 【Gerrit】自动设置reviewer
gerrit 提供了一种代码review解决方案,但每次代码提交之后都要设置每个commit的code reviewer, 实在是痛苦. gerrit 在官方说明文档里面提供了解决方法,地址:http ...
- Qt 事件处理 快捷键(重写eventFilter的函数,使用Qt::ControlModifier判断)
CTRL+Enter发送信息的实现 在现在的即时聊天程序中,一般都设置有快捷键来实现一些常用的功能,类似QQ可以用CTRL+Enter来实现信息的发送. 在QT4中,所有的事件都继承与QEvent这个 ...
- generate eml file
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <HTML> <HEAD ...
- intellij开发安卓与genymotion配合
原文:intellij开发安卓与genymotion配合 [声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http: ...
- LigerUI中Grid的使用时关于url请求不到数据的问题
前台代码:(这里贴的是js的代码,完整的代码可以在LigerUI的文档中找到), 这里使用的是url请求数据,问题不是处在前台,所以就不细说. $("#maingrid").lig ...