使用HtmlAgilityPack 爬取 国家统计局 区划和城乡划分代码
HtmlAgilityPack:Html解析神器,根据url地址解析html页面内容。
项目引用HtmlAgilityPack.dll文件或者通过安装 nuget 包 HtmlAgilityPack
特别注意:页面编码是GB2312时,会出现乱码问题。
解决方法:
.NET Framework 下处理方法:
var encoding = Encoding.GetEncoding("GB2312");
.NET Core 下处理方法:(安装 nuget 包 System.Text.Encoding.CodePages,需不需要?因为卸载后也没有出现问题)
System.Text.Encoding.RegisterProvider(System.Text.CodePagesEncodingProvider.Instance);
var encoding = System.Text.Encoding.GetEncoding("GB2312");
好了,说完处理过程中出现的问题,下面就放上程序代码:
1 using System;
2 using System.Threading;
3 using HtmlAgilityPack; //需要添加的命名空间
4
5 namespace ConsoleApp1
6 {
7 class Program
8 {
9 static string baseUrl = "http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/";
10 static void Main(string[] args)
11 {
12 GetProvince("index.html");
13 Console.ReadKey();
14 }
15
16 /// <summary>
17 /// 通过url获取html内容
18 /// </summary>
19 /// <param name="url"></param>
20 /// <returns></returns>
21 public static HtmlDocument GetHtmlDocument(string url)
22 {
23 HtmlDocument doc = null;
24 try
25 {
26 HtmlWeb web = new HtmlWeb();
27 System.Text.Encoding.RegisterProvider(System.Text.CodePagesEncodingProvider.Instance);
28 var encoding = System.Text.Encoding.GetEncoding("GB2312");
29 web.OverrideEncoding = encoding;
30 //从url中加载
31 doc = web.Load(baseUrl + url);
32
33 //获得title标签节点,其子标签下的所有节点也在其中
34 HtmlNode headNode = doc.DocumentNode.SelectSingleNode("//title");
35 //获得title标签中的内容
36 string Title = headNode.InnerText;
37 //Console.WriteLine(Title);
38 if (Title == "502 Bad Gateway")
39 {
40 Thread.Sleep(10000);
41 doc = GetHtmlDocument(url);
42 }
43 }
44 catch (Exception ex)
45 {
46 throw ex;
47 }
48 return doc;
49 }
50 /// <summary>
51 /// 省份
52 /// </summary>
53 /// <param name="url"></param>
54 public static void GetProvince(string url)
55 {
56 //从url中加载
57 HtmlDocument doc = GetHtmlDocument(url);
58
59 //table class='provincetable'
60 //provincetable table标签节点
61 HtmlNode tableNode = doc.DocumentNode.SelectSingleNode("//table[@class='provincetable']");
62 //获得tr标签下的所有子节点
63 HtmlNodeCollection trCollection = tableNode.ChildNodes;
64 foreach (var trItem in trCollection)
65 {
66 var classNode = trItem.Attributes["class"];
67 //判断是否存在class属性
68 if (classNode != null)
69 {
70 //获得标签属性为class的值
71 string className = classNode.Value;
72 if (className == "provincetr")
73 {
74 //获得tr标签下的所有子节点
75 HtmlNodeCollection tdCollection = trItem.ChildNodes;
76 foreach (var tdItem in tdCollection)
77 {
78 //获得td标签下的所有子节点
79 HtmlNodeCollection aCollection = tdItem.ChildNodes;
80 foreach (var item in aCollection)
81 {
82 //只查找a标签 派出其他标签
83 if (item.Name == "a")
84 {
85 //获得标签属性为href的值
86 string aValue = item.Attributes["href"].Value;
87 //获得标签内的内容
88 string aInterText = item.InnerText.Replace("<br/>", "");
89 string[] split = aValue.Split(new Char[] { '.' });
90 string code = split[0];
91
92 Console.WriteLine("区划代码:" + code + "\t" + " 省份:" + aInterText);
93
94 //Thread.Sleep(5000);
95 GetCity(aValue);
96 }
97 }
98 }
99 }
100 }
101 }
102 }
103 /// <summary>
104 /// 市
105 /// </summary>
106 /// <param name="url"></param>
107 public static void GetCity(string url)
108 {
109 //从url中加载
110 HtmlDocument doc = GetHtmlDocument(url);
111
112 //table class='provincetable'
113 //citytable table标签节点
114 HtmlNode tableNode = doc.DocumentNode.SelectSingleNode("//table[@class='citytable']");
115 //获得tr标签下的所有子节点
116 HtmlNodeCollection trCollection = tableNode.ChildNodes;
117 foreach (var trItem in trCollection)
118 {
119 var classNode = trItem.Attributes["class"];
120 //判断是否存在class属性
121 if (classNode != null)
122 {
123 //获得标签属性为class的值
124 string className = classNode.Value;
125 if (className == "citytr")
126 {
127 //获得tr标签下的所有子节点
128 HtmlNodeCollection tdCollection = trItem.ChildNodes;
129 int i = 0;
130 foreach (var tdItem in tdCollection)
131 {
132 //获取第二td
133 if (i == 1)
134 {
135 //获得td标签下的所有子节点
136 HtmlNodeCollection aCollection = tdItem.ChildNodes;
137
138 foreach (var item in aCollection)
139 {
140 //只查找a标签 派出其他标签
141 if (item.Name == "a")
142 {
143 //获得标签属性为href的值
144 string aValue = item.Attributes["href"].Value;
145 //获得标签内的内容
146 string aInterText = item.InnerText.Replace("<br/>", "");
147 string[] split = aValue.Split(new Char[] { '.' })[0].Split(new Char[] { '/' });
148
149 string code = split[1];
150
151
152 Console.WriteLine("区划代码:" + code + "\t" + " 市:" + aInterText);
153
154 //11/1101.html 2019/11/1101.html
155 //Thread.Sleep(5000);
156 GetCounty(aValue);
157 }
158 }
159 }
160 i++;
161 }
162 }
163 }
164 }
165 }
166 /// <summary>
167 /// 区/县
168 /// </summary>
169 /// <param name="url"></param>
170 public static void GetCounty(string url)
171 {
172 //从url中加载
173 HtmlDocument doc = GetHtmlDocument(url);
174
175 //table class='countytable'
176 //countytable table标签节点
177 HtmlNode tableNode = doc.DocumentNode.SelectSingleNode("//table[@class='countytable']");
178 //获得tr标签下的所有子节点
179 HtmlNodeCollection trCollection = tableNode.ChildNodes;
180 foreach (var trItem in trCollection)
181 {
182 var classNode = trItem.Attributes["class"];
183 //判断是否存在class属性
184 if (classNode != null)
185 {
186 //获得标签属性为class的值
187 string className = classNode.Value;
188 if (className == "countytr")
189 {
190 //获得tr标签下的所有子节点
191 HtmlNodeCollection tdCollection = trItem.ChildNodes;
192 int i = 0;
193 foreach (var tdItem in tdCollection)
194 {
195 //获取第二td
196 if (i == 1)
197 {
198 //获得td标签下的所有子节点
199 HtmlNodeCollection aCollection = tdItem.ChildNodes;
200
201 foreach (var item in aCollection)
202 {
203 //只查找a标签 派出其他标签
204 if (item.Name == "a")
205 {
206 //获得标签属性为href的值
207 string aValue = item.Attributes["href"].Value;
208 //获得标签内的内容
209 string aInterText = item.InnerText.Replace("<br/>", "");
210 string[] split = aValue.Split(new Char[] { '.' })[0].Split(new Char[] { '/' });
211 string code = split[1];
212
213 Console.WriteLine("区划代码:" + code + "\t" + " 区/县:" + aInterText);
214
215 //01/1101.html 2019/11/01/1101.html
216 string provinceCode = code.Substring(0, 2);
217 var townUrl = provinceCode + "/" + aValue;
218 //Thread.Sleep(5000);
219 GetTown(townUrl);
220 }
221 }
222 }
223 i++;
224 }
225 }
226 }
227 }
228 }
229
230 /// <summary>
231 /// 乡/镇/街道
232 /// </summary>
233 /// <param name="url"></param>
234 public static void GetTown(string url)
235 {
236 //从url中加载
237 HtmlDocument doc = GetHtmlDocument(url);
238
239 //table class='towntable'
240 //towntable table标签节点
241 HtmlNode tableNode = doc.DocumentNode.SelectSingleNode("//table[@class='towntable']");
242 //获得tr标签下的所有子节点
243 HtmlNodeCollection trCollection = tableNode.ChildNodes;
244 foreach (var trItem in trCollection)
245 {
246 var classNode = trItem.Attributes["class"];
247 //判断是否存在class属性
248 if (classNode != null)
249 {
250 //获得标签属性为class的值
251 string className = classNode.Value;
252 if (className == "towntr")
253 {
254 //获得tr标签下的所有子节点
255 HtmlNodeCollection tdCollection = trItem.ChildNodes;
256 int i = 0;
257 foreach (var tdItem in tdCollection)
258 {
259 //获取第二td
260 if (i == 1)
261 {
262 //获得td标签下的所有子节点
263 HtmlNodeCollection aCollection = tdItem.ChildNodes;
264
265 foreach (var item in aCollection)
266 {
267 //只查找a标签 派出其他标签
268 if (item.Name == "a")
269 {
270 //获得标签属性为href的值
271 string aValue = item.Attributes["href"].Value;
272 //获得标签内的内容
273 string aInterText = item.InnerText.Replace("<br/>", "");
274 string[] split = aValue.Split(new Char[] { '.' })[0].Split(new Char[] { '/' });
275 string code = split[1];
276
277 Console.WriteLine("区划代码:" + code + "\t" + " 乡/镇/街道:" + aInterText);
278
279 //01/110101001.html 2019/11/01/01/110101001.html
280 string provinceCode = code.Substring(0, 2);
281 string cityCode = code.Substring(2, 2);
282 var villageUrl = provinceCode + "/" + cityCode + "/" + aValue;
283 Thread.Sleep(5000);
284 GetVillage(villageUrl);
285 }
286 }
287 }
288 i++;
289 }
290 }
291 }
292 }
293 }
294
295 /// <summary>
296 /// 村庄
297 /// </summary>
298 /// <param name="url"></param>
299 public static void GetVillage(string url)
300 {
301 //从url中加载
302 HtmlDocument doc = GetHtmlDocument(url);
303
304 //table class='villagetable'
305 //villagetable table标签节点
306 HtmlNode tableNode = doc.DocumentNode.SelectSingleNode("//table[@class='villagetable']");
307 //获得tr标签下的所有子节点
308 HtmlNodeCollection trCollection = tableNode.ChildNodes;
309 foreach (var trItem in trCollection)
310 {
311 var classNode = trItem.Attributes["class"];
312 //判断是否存在class属性
313 if (classNode != null)
314 {
315 //获得标签属性为class的值
316 string className = classNode.Value;
317 if (className == "villagetr")
318 {
319 //获得tr标签下的所有子节点
320 HtmlNodeCollection tdCollection = trItem.ChildNodes;
321
322 string code = "";
323 string typeCode = "";
324 string villageName = "";
325
326 int i = 0;
327 foreach (var tdItem in tdCollection)
328 {
329 //获得标签内的内容
330 string aInterText = tdItem.InnerText.Replace("<br/>", "");
331
332 //获取第二td
333 if (i == 0) //区划代码
334 {
335 code = aInterText;
336 }
337 else if (i == 1) //城乡分类代码
338 {
339 typeCode = aInterText;
340 }
341 else if (i == 2) //村庄名称
342 {
343 villageName = aInterText;
344 }
345
346 i++;
347
348 }
349 //城乡分类代码
350 Console.WriteLine("区划代码:" + code + "\t" + " 城乡分类代码:" + typeCode + "\t" + " 村庄:" + villageName);
351 }
352 }
353 }
354 }
355 }
356 }
再上传一个效果图吧,方便大家看到结果:
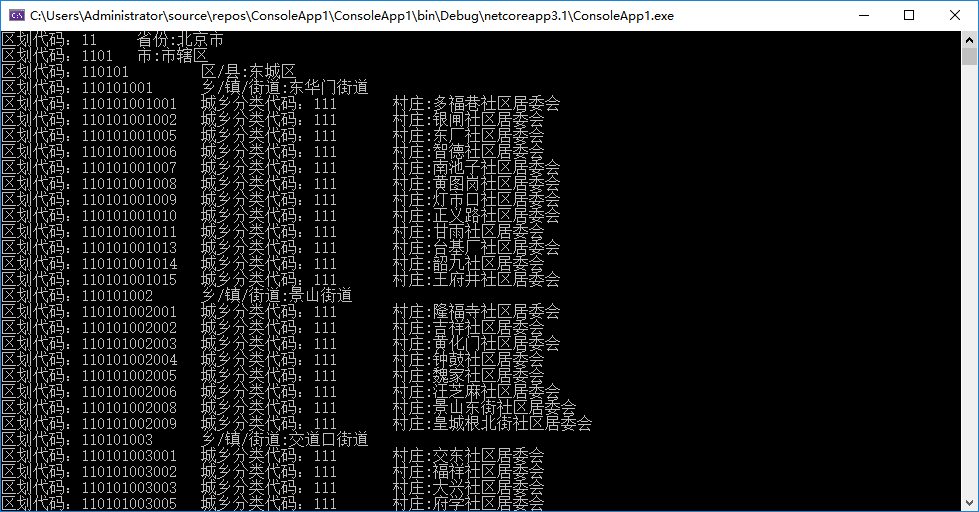
使用HtmlAgilityPack 爬取 国家统计局 区划和城乡划分代码的更多相关文章
- 使用java爬取国家统计局的12位行政区划代码
前言: 本文基于j2ee的原始url进行都写,解析指定内容时也是使用很傻的形式去查找指定格式的字符串来实现的. 更优雅的方式是可以使用apache的HttpClient和某些文档模型将HTML字符串构 ...
- python 爬虫 requests+BeautifulSoup 爬取巨潮资讯公司概况代码实例
第一次写一个算是比较完整的爬虫,自我感觉极差啊,代码low,效率差,也没有保存到本地文件或者数据库,强行使用了一波多线程导致数据顺序发生了变化... 贴在这里,引以为戒吧. # -*- coding: ...
- 安居客scrapy房产信息爬取到数据可视化(下)-可视化代码
接上篇:安居客scrapy房产信息爬取到数据可视化(下)-可视化代码,可视化的实现~ 先看看保存的数据吧~ 本人之前都是习惯把爬到的数据保存到本地json文件, 这次保存到数据库后发现使用mongod ...
- 使用HtmlAgilityPack爬取网站信息并存储到mysql
前言:打算做一个药材价格查询的功能,但刚开始一点数据都没有靠自己找信息录入的话很麻烦的,所以只有先到其它网站抓取存到数据库再开始做这个了. HtmlAgilityPack在c#里应该很多人用吧,简单又 ...
- python2爬取国家统计局全国省份城市区街道信息
工作中,再次需要python,发现python用得好 ,真的可以节省很多人力,先说我的需求,需要做一个类似像支付宝添加收货地址时,选择地区的功能,需要详细到街道信息,也就是4级联动,如右图.首先需要的 ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 用python的matplotlib和numpy库绘制股票K线均线的整合效果(含从网络接口爬取数据和验证交易策略代码)
本人最近在尝试着发表“以股票案例入门Python编程语言”系列的文章,在这些文章里,将用Python工具绘制各种股票指标,在讲述各股票指标的含义以及计算方式的同时,验证基于各种指标的交易策略,本文是第 ...
- python爬虫爬取get请求的页面数据代码样例
废话不多说,上代码 #!/usr/bin/env python # -*- coding:utf-8 -*- # 导包 import urllib.request import urllib.pars ...
- C# HtmlAgilityPack爬取静态页面
最近对爬虫很感兴趣,稍微研究了一下,利用HtmlAgilityPack制作了一个十分简单的爬虫,这个简易爬虫只能获取静态页面的Html HtmlAgilityPack简介 HtmlAgilityPac ...
- 教你用python爬取网站美女图(附代码及教程)
我前几篇文章都是说一些python爬虫库的用法,还没有说怎样利用好这些知识玩一些好玩的东西.那我今天带大家玩好玩又刺激的,嘻嘻!对了,requests库和正则表达式很重要的,一定要学会!一定要学会!! ...
随机推荐
- 开发用户K8S授权
#开发用户没有K8S权限 [ans@master ~]$ kubectl get po Unable to connect to the server: x509: certificate signe ...
- Git 实战代码分支管理 | Git Flow 策略
简介 在团队协作开发中,版本管理工具尤为重要,它可以帮助团队很好地进行代码的共享.回滚等操作,比较流行的版本管理工具有:CVS.SVN.Git.Git作为分布式版本管理工具,优势十分明显,它可以为 ...
- 2022春每日一题:Day 17
今天打CF去了,但是很菜,只做了三题.赛后一分钟做出了第四题,wa了,改了一下下,过了 第一题就是对应的小写字母在大写字母前出现. 第二题直接dfs. 第三题dp,f[i][j]表示以第i个数开始加了 ...
- Selenium4+Python3系列(七) - Iframe、Select控件、交互式弹出框、执行JS、Cookie操作
前言 突然,想把所有之前未更新的常用Api操作.演示写出来,算是对API的一种完结吧. 下面按照Api模块来做逐一介绍. 一.iframe操作 iframe识别: 语法: driver.switch_ ...
- i春秋时间
打开题目就是一段php代码 大致的意思是 ------------------------------------------------------------------------------- ...
- JavaScript入门③-函数(2)原理{深入}执行上下文
00.头痛的JS闭包.词法作用域? 被JavaScript的闭包.上下文.嵌套函数.this搞得很头痛,这语言设计的,感觉比较混乱,先勉强理解总结一下. 为什么有闭包这么个东西?闭包包的是什么? 什么 ...
- ATM购物车项目 三层架构
目录 项目开发流程 项目需求 三层架构 (重点) 实际案例 展示层 核心逻辑层 数据处理层 ATM项目 项目开发流程 # 1.项目需求分析 产品经理(客户) 架构师 开发经理 1.架构师 开发经理提前 ...
- Windows搭建Git服务器
Windows如何搭建Git服务器 1.安装java环境 (1)下载安装java 注意(java的版本需要在1.7及以上) (2)配置java的环境变量 (3)检验java环境是否安装成功 2.下载安 ...
- 微软出品自动化神器【Playwright+Java】系列(七) 之 元素的可操作性验证
前言 昨天在某平台发表了一篇这系列的文章,结果不但提示说有违禁词(java也算?),然后文章审核通过后,文章还找不到,不到去哪了,表示很郁闷,去反应未果,确实有点尴尬了. 元素的可操作性验证 关于AP ...
- JavaScript:变量的作用域,window对象,关键字var/let与function
为什么要将这些内容放在一起,因为他们都跟初始化有关系,我们慢慢说吧. 我们在代码中,都会声明变量.函数和对象,然后由浏览器解释器(下面简称浏览器)执行: 我们还说过,变量和对象的内存结构: 那么,是什 ...