pyspider爬虫框架webui简介-爬取阿里招聘信息
命令行输入pyspider开启pyspider

浏览器打开http://localhost:5000/
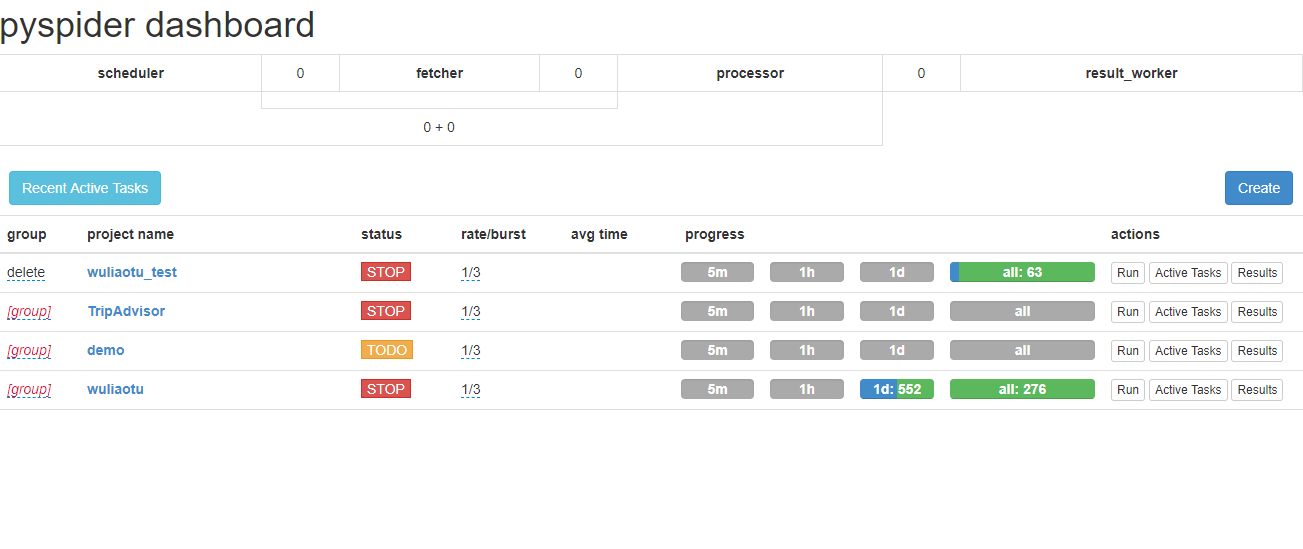
group表示组名,几个项目可以同一个组名,方便管理,当组名修改为delete时,项目会在一天后自动删除。
status表示项目的状态,TODO工作环境,STOP停用状态,DEBUG调试状态,RUNNING运行状态。当设置为RUNNING状态时,点击右边actions的Run按钮,程序就会跑起来。actions中的Results按钮点击之后,查看程序爬取的结果,如图:
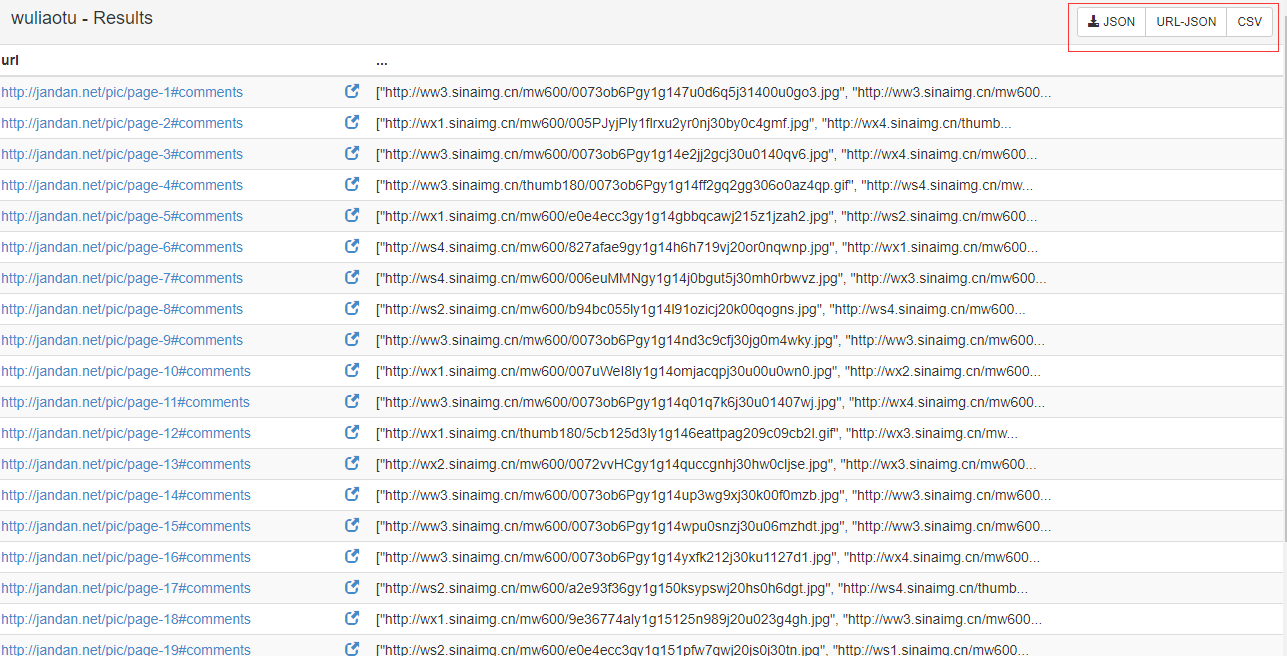
点击右上角,可以以不同格式查看爬取信息,点击url可以查看每个url爬取的任务ID,结果等信息。如图:
点击项目名,进入代码界面:

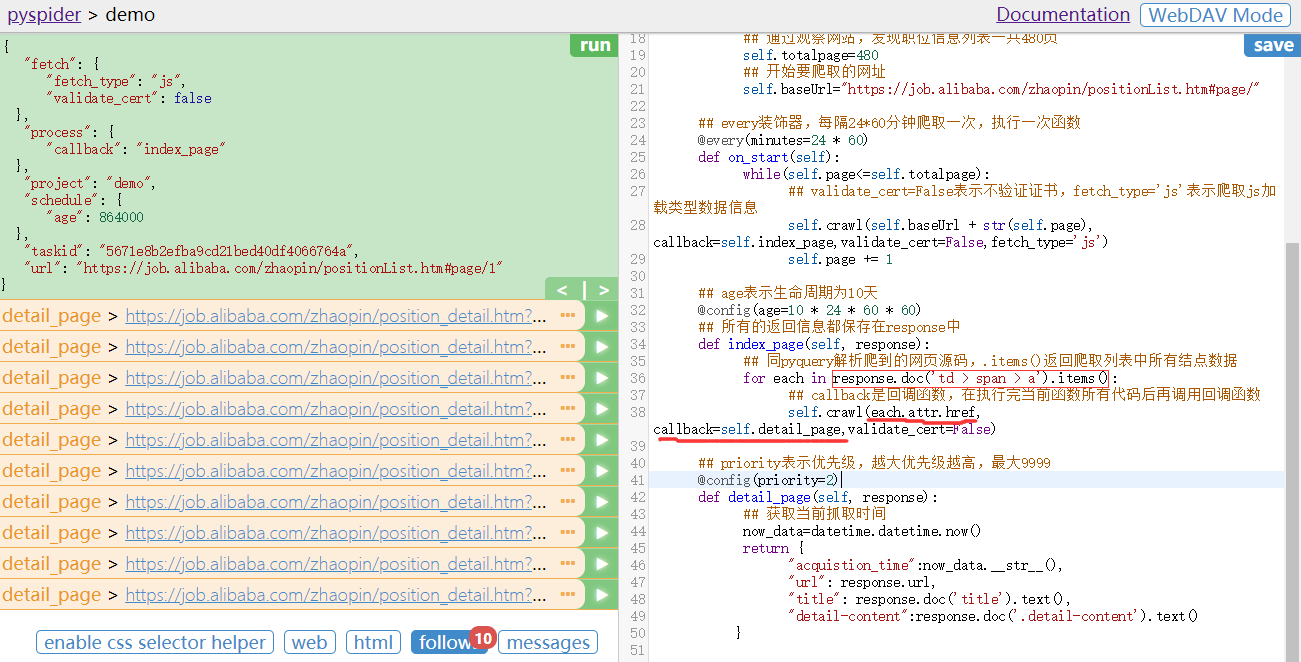
看代码,
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2019-03-24 13:51:31
# Project: demo
from pyspider.libs.base_handler import *
import datetime
class Handler(BaseHandler):
crawl_config = {
}
def __init__(self):
'''用户自定义,初始化变量'''
## 当前页码
self.page=1
## 通过观察网站,发现职位信息列表一共480页
self.totalpage=480
## 开始要爬取的网址
self.baseUrl="https://job.alibaba.com/zhaopin/positionList.htm#page/"
## every装饰器,每隔24*60分钟爬取一次,执行一次函数
@every(minutes=24 * 60)
def on_start(self):
while(self.page<=self.totalpage):
## validate_cert=False表示不验证证书,fetch_type='js'表示爬取js加载类型数据信息
self.crawl(self.baseUrl + str(self.page), callback=self.index_page,validate_cert=False,fetch_type='js')
self.page += 1
## age表示生命周期为10天
@config(age=10 * 24 * 60 * 60)
## 所有的返回信息都保存在response中
def index_page(self, response):
## 同pyquery解析爬到的网页源码,.items()返回爬取列表中所有结点数据
for each in response.doc('td > span > a').items():
## callback是回调函数,在执行完当前函数所有代码后再调用回调函数
self.crawl(each.attr.href, callback=self.detail_page,validate_cert=False)
## priority表示优先级,越大优先级越高,最大9999
@config(priority=2)
def detail_page(self, response):
## 获取当前抓取时间
now_data=datetime.datetime.now()
return {
"acquistion_time":now_data.__str__(),
"url": response.url,
"title": response.doc('title').text(),
"detail-content":response.doc('.detail-content').text()
}
然后看左边编辑器,
每次编辑好右边代码后点击右上角SAVE按钮保存,然后点击RUN,运行程序

follows表示当前执行回调函数on_start执行之后,有多少此回调index_page函数,传入参数self。点击follows,出现每一个index_page函数传入的self中的链接,对应链接右边的向右箭头,执行该index_page函数。

点击第一个index_page函数右边箭头之后,点击web按钮,显示index_page传入链接的网页如图,点击html按钮,是web网页对应的源码,点击follows如图,显示执行index_page回调函数后的结果,即列表页信息。
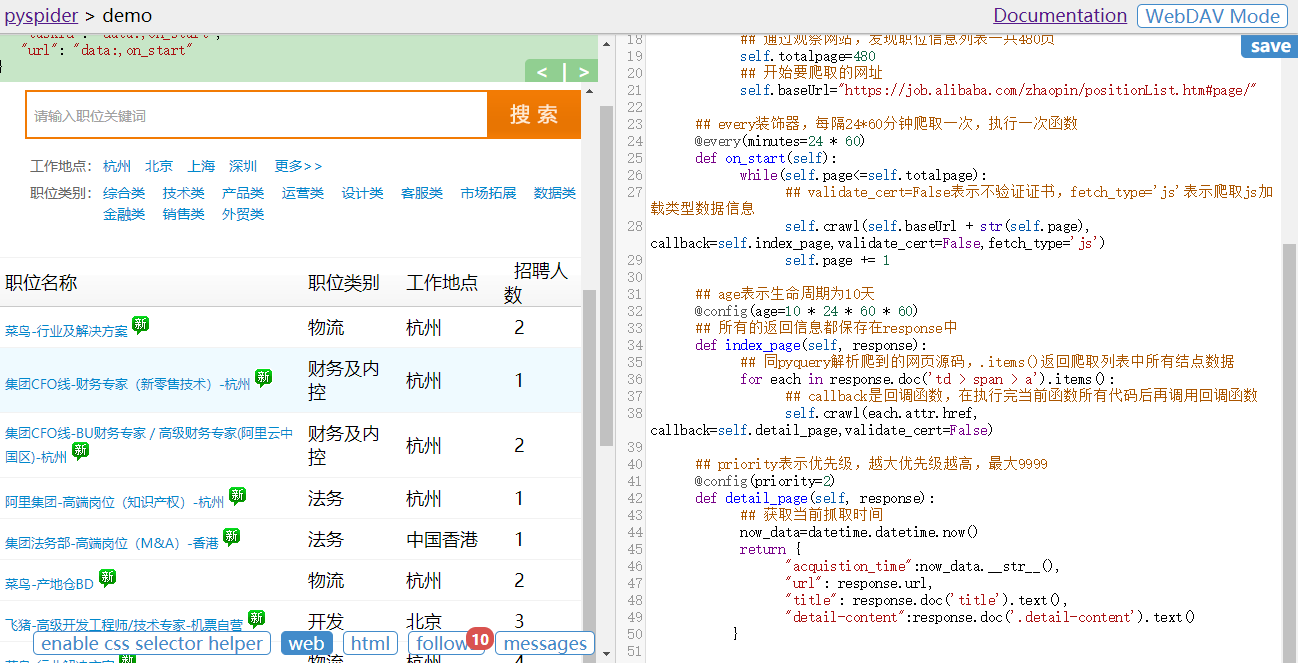
然后,在点击web按钮后,点击enable css selector helper按钮,选中web网页中对应职位标题,单击选中,然后点击左边窗体右上角的箭头,就会将对应选择结点的CSS选择器自动生成到右边代码编辑区鼠标定位处。

继续回来,点击follows,然后点击detail_page回调函数右边的箭头执行每个detail_page回调函数,则爬取了detail_page返回的内容,即详情页信息,每个职位的详细信息。

messages按钮表示右边代码中return的信息,及控制台提示信息、报错信息等。
pyspider爬虫框架webui简介-爬取阿里招聘信息的更多相关文章
- 爬虫框架之Scrapy——爬取某招聘信息网站
案例1:爬取内容存储为一个文件 1.建立项目 C:\pythonStudy\ScrapyProject>scrapy startproject tenCent New Scrapy projec ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- 爬取拉勾网招聘信息并使用xlwt存入Excel
xlwt 1.3.0 xlwt 文档 xlrd 1.1.0 python操作excel之xlrd 1.Python模块介绍 - xlwt ,什么是xlwt? Python语言中,写入Excel文件的扩 ...
- Python爬虫框架Scrapy获得定向打击批量招聘信息
爬虫,就是一个在网上到处或定向抓取数据的程序,当然,这样的说法不够专业,更专业的描写叙述就是.抓取特定站点网页的HTML数据.只是因为一个站点的网页非常多,而我们又不可能事先知道全部网页的URL地址, ...
- Python爬取拉勾网招聘信息并写入Excel
这个是我想爬取的链接:http://www.lagou.com/zhaopin/Python/?labelWords=label 页面显示如下: 在Chrome浏览器中审查元素,找到对应的链接: 然后 ...
- Java爬虫框架WebMagic入门——爬取列表类网站文章
初学爬虫,WebMagic作为一个Java开发的爬虫框架很容易上手,下面就通过一个简单的小例子来看一下. WebMagic框架简介 WebMagic框架包含四个组件,PageProcessor.Sch ...
- 爬虫框架Scrapy入门——爬取acg12某页面
1.安装1.1自行安装python3环境1.2ide使用pycharm1.3安装scrapy框架2.入门案例2.1新建项目工程2.2配置settings文件2.3新建爬虫app新建app将start_ ...
- python-scrapy爬虫框架爬取拉勾网招聘信息
本文实例为爬取拉勾网上的python相关的职位信息, 这些信息在职位详情页上, 如职位名, 薪资, 公司名等等. 分析思路 分析查询结果页 在拉勾网搜索框中搜索'python'关键字, 在浏览器地址栏 ...
- Scrapy框架——CrawlSpider爬取某招聘信息网站
CrawlSpider Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 它是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页, 而Craw ...
随机推荐
- 【深度学习系列】卷积神经网络CNN原理详解(一)——基本原理
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度.有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可 ...
- lua的String
基础字符串函数 字符串库中有一些函数非常简单,如: 1). string.len(s) 返回字符串s的长度: 2). string.rep(s,n) 返回字符串s重复n次的结果: 3 ...
- 第34章 授予类型 - Identity Server 4 中文文档(v1.0.0)
授权类型是指定客户端如何与IdentityServer交互的方式.OpenID Connect和OAuth2.0规范定义了以下授权类型: Implicit Authorization code Hyb ...
- 第13章 切换到混合流并添加API访问 - Identity Server 4 中文文档(v1.0.0)
在之前的快速入门中,我们探讨了API访问和用户身份验证.现在我们想把这两个部分放在一起. OpenID Connect和OAuth 2.0组合的优点在于,您可以使用单个协议和使用令牌服务进行单次交换来 ...
- "每日一道面试题".net托管堆是否会存在内存泄漏的情况
首先说答案:会 所谓的内存泄漏,就是指内存空间上产生了不再被实际使用却又无非被分配的对象.严格意义上来说,在.net中经常会遇到内存泄漏的情况,因为托管堆内的对象不再被使用时,需要等待下一次GC才会被 ...
- Java中float型最大值大于long型?
float型在内存中占用的是4个字节的空间,而long型占用的是8个字节的空间. 注:float类型的范围是:一3.403E38~3.403E38.而long类型的范围是:-2^63~2^63-1(大 ...
- 折腾Java设计模式之策略模式
博客原文地址 简介 在策略模式(Strategy Pattern)中,一个类的行为或其算法可以在运行时更改.这种类型的设计模式属于行为型模式.简单理解就是一组算法,可以互换,再简单点策略就是封装算法. ...
- Spring框架基础(上)
spring是开源对轻量级框架 spring核心主要两部分 aop 面向切面编程,扩展功能不是修改源代码实现 aop采用横向抽取机制,取代了传统纵向继承体系重复代码(性能监视.事务管理.安全检查.缓存 ...
- SBC数据格式转换软件
北京博信施科技有限公司是一家专业从事数据格式转换.数据处理领域研发软件产品和解决方案实施的技术型公司.在当今信息时代,PDF文档格式是在Internet上进行电子文档发行和数字化信息传播的理想文档格式 ...
- iOS----------教你如何使用 GitHub Desktop
1.先创建一个工程项目Test 2.创建一个仓库Repository 3.提交到master(记得写标题) 4.推送到github上 5.创建仓库Respository成功