scrapy爬虫,爬取图片
一、scrapy的安装:
本文基于Anacoda3,
Anacoda2和3如何同时安装?
将Anacoda3安装在C:\ProgramData\Anaconda2\envs文件夹中即可。
如何用conda安装scrapy?
安装了Anaconda2和3后,

如图,只有一个命令框,可以看到打开的时候:
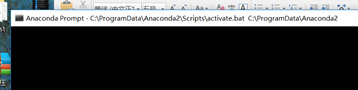
可以切到Anaconda3对应的路径下即可。
安装的方法:cmd中:conda install scrapy即可。
当然,可能会出现权限的问题,那是因为安装的文件夹禁止了读写。可以如图:
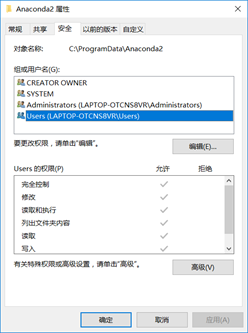
将权限都设为“允许“。
注意:此时虽然scapy安装上了,但是在cmd中输入scapy可能会不认,可以将安装scrapy.exe的路径添加到环境变量中。
二、scapy的简单使用
例子:爬取图片
1、 创建scrapy工程
譬如,想要创建工程名:testImage
输入:scrapy startproject testImage
即可创建该工程,按照cmd中提示的依次输入:
cd testImage
scrapy genspider getPhoto www.27270.com/word/dongwushijie/2013/4850.html
其中:在当前项目中创建spider,这仅仅是创建spider的一种快捷方法,该方法可以使用提前定义好的模板来生成spider,后面的网址是一个采集网址的集合,即为允许访问域名的一个判断。注意不要加http/https。
至此,可以在testImage\testImage\spiders中找到创建好的爬虫getPhoto.py,可以在此基础上进行修改。
2、创建爬虫
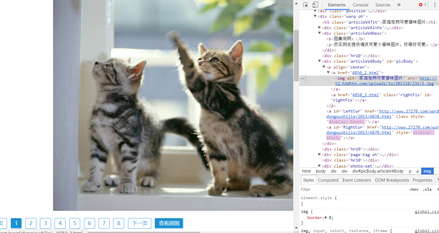
如图,可以在图片的位置右键,检查,查看源码,在图片所在的位置处,将xpath拷贝出来。
此时,可以找出图片的地址:
class GetphotoSpider(scrapy.Spider):
name = 'getPhoto'
allowed_domains = ['www.27270.com']
start_urls = ['http://www.27270.com/word/dongwushijie/2013/4850.html']
def parse(self, response):
urlImage = response.xpath('//*[@id="picBody"]/p/a[1]/img/@src').extract()
print(urlImage)
pass
此时,注意网络路径的正确书写,最后没有/,
http://www.27270.com/word/dongwushijie/2013/4850.html/
此时将4850.html 当作了目录,会出现404找不到路径的错误!
3、 下载图片
items.py:
class PhotoItem(scrapy.Item):
name = scrapy.Field()
imageLink = scrapy.Field()
pipelines.py:
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class ImagePipeline(ImagesPipeline):
def get_media_requests(self,item,info):
image_link = item['imageLink']
yield scrapy.Request(image_link)
settings.py:
IMAGES_STORE = r"C:\Users\24630\Desktop\test"
另外,对于上面的网址,还需要ROBOTSTXT_OBEY = False
并且,访问该网址会出现302错误,这是一个重定向的问题,
MEDIA_ALLOW_REDIRECTS =True
设置该选项,就可以正确下载,但是下载的还是不对,问题不好解决。
当然在爬虫中,还要对items赋值:
from testImage import items
。。。 for urllink in urlImage:
item = items.PhotoItem()
item['imageLink'] = urllink
三、 进一步爬取(读取下一页)
# -*- coding: utf-8 -*-
import scrapy
from testImage import items
class GetphotoSpider(scrapy.Spider):
name = 'getPhoto'
allowed_domains = ['www.wmpic.me']
start_urls = ['http://www.wmpic.me/93912']
def parse(self, response):
#//*[@id="content"]/div[1]/p/a[2]/img
urlImage = response.xpath('//*[@id="content"]/div[1]/p/a/img/@src').extract()
print(urlImage)
for urllink in urlImage:
item = items.PhotoItem()
item['imageLink'] = urllink
yield item ifnext = response.xpath('//*[@id="content"]/div[2]/text()').extract()[0]
# 当没有下一篇,即最后一页停止爬取
if("下一篇" in ifnext):
nextUrl = response.xpath('//*[@id="content"]/div[2]/a/@href').extract()[0]
url=response.urljoin(nextUrl)
yield scrapy.Request(url=url)
此时,便可以看到路径下的下载后的文件了。(由于该网址每页的图片所在的xpath都不一样,故下载的图片不全)
scrapy爬虫,爬取图片的更多相关文章
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
- [python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度.搜狗.googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨.同时 ...
- python +requests 爬虫-爬取图片并进行下载到本地
因为写12306抢票脚本需要用到爬虫技术下载验证码并进行定位点击所以这章主要讲解,爬虫,从网页上爬取图片并进行下载到本地 爬虫实现方式: 1.首先选取你需要的抓取的URL:2.将这些URL放入待抓 ...
- 使用scrapy框架爬取图片网全站图片(二十多万张),并打包成exe可执行文件
目标网站:https://www.mn52.com/ 本文代码已上传至git和百度网盘,链接分享在文末 网站概览 目标,使用scrapy框架抓取全部图片并分类保存到本地. 1.创建scrapy项目 s ...
- Python 爬虫 爬取图片入门
爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 用户看到的网页实质是由 HTML 代码构成的,爬 ...
- python爬虫---scrapy框架爬取图片,scrapy手动发送请求,发送post请求,提升爬取效率,请求传参(meta),五大核心组件,中间件
# settings 配置 UA USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, l ...
- <scrapy爬虫>爬取校花信息及图片
1.创建scrapy项目 dos窗口输入: scrapy startproject xiaohuar cd xiaohuar 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # ...
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- 使用scrapy ImagesPipeline爬取图片资源
这是一个使用scrapy的ImagesPipeline爬取下载图片的示例,生成的图片保存在爬虫的full文件夹里. scrapy startproject DoubanImgs cd DoubanIm ...
- <scrapy爬虫>爬取360妹子图存入mysql(mongoDB还没学会,学会后加上去)
1.创建scrapy项目 dos窗口输入: scrapy startproject images360 cd images360 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) ...
随机推荐
- C语言实现线性表
#include <stdio.h> #include <stdlib.h> //提供malloc()原型 /* 线性表需要的方法: 1. List MakeEmpty():初 ...
- Python Pool
我们在使用Python时,会经常需要使用多进程/多线程的情况,以便提高程序的运行效率,尤其是跟网络进行交互,如使用爬虫时.下面我们将简单看下Python的进程池的创建,map().apply_asyn ...
- shell脚本-监控及邮件提醒
首先写一个邮件提醒python文件 #!/usr/bin/python # -*- coding: UTF-8 -*- import sys import smtplib import email.m ...
- Dream------scala--开发环境搭建
scala简介: scala是一门函数式编程和面向对象编程结合的语言 函数式编程非常擅长数值计算而面向对象特别适合于大型工程或项目的组织以及团队的分工合作 我们借助scala可以非常优雅的构造出各种规 ...
- 【连接查询】mySql多表连接查询与union与union all用法
1.准备两个表 表a: 结构: mysql> desc a; +-------+-------------+------+-----+---------+-------+ | Field | T ...
- 【FCS NOI2018】福建省冬摸鱼笔记 day1
省冬的第一天. 带了本子,笔,一本<算法导论>就去了.惊讶于为什么同学不带本子记笔记. 他们说:“都学过了.”,果然这才是巨神吧. 第一天:数论,讲师:zzx 前几页的课件挺水,瞎记了点笔 ...
- 一步一步搭建oracle 11gR2 rac+dg之共享磁盘设置(三)【转】
一步一步在RHEL6.5+VMware Workstation 10上搭建 oracle 11gR2 rac + dg 之共享磁盘准备 (三) 注意:这一步是配置rac的过程中非常重要的一步,很多童鞋 ...
- Python之 context manager
在context manager中,必须要介绍两个概念: with as... , 和 enter , exit. 下文将先介绍with语句,然后介绍 __enter__和exit, 最后介绍cont ...
- RobotFramework基本用法(二)
双击打开C:\Python27\Scripts目录下的 ride.py 一,定义变量,打印 1,右键File-->New Poreject,在项目下右键New suite,在套件下右键 New ...
- Python开发环境(1):Eclipse+PyDev插件
电脑:小米笔记本电脑Pro 15.6寸(i5-8250U),操作系统:Windows 10,JDK版本:1.8.0_152(环境变量已配置) Step 1.下载Eclipse 根据我的CPU型号,选择 ...