<scrapy爬虫>爬取360妹子图存入mysql(mongoDB还没学会,学会后加上去)
1.创建scrapy项目
dos窗口输入:
scrapy startproject images360
cd images360
2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义)
import scrapy class Images360Item(scrapy.Item):
# define the fields for your item here like:
#图片ID
image_id = scrapy.Field()
#链接
url = scrapy.Field()
#标题
title = scrapy.Field()
#缩略图
thumb = scrapy.Field()
3.创建爬虫文件
dos窗口输入:
scrapy genspider myspider images.so.com
4.编写myspider.py文件(接收响应,处理数据)
# -*- coding: utf-8 -*-
from urllib.parse import urlencode
import scrapy
from images360.items import Images360Item
import json class MyspiderSpider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['images.so.com']
urls = []
data = {'ch': 'beauty', 'listtype': 'new'}
base_url = 'https://image.so.com/zj?0'
for page in range(1,51):
data['sn'] = page * 30
params = urlencode(data)
url = base_url + params
urls.append(url)
print(urls)
start_urls = urls # ch: beauty
# sn: 120
# listtype: new
# temp: 1 def parse(self, response):
result = json.loads(response.text)
for each in result.get('list'):
item = Images360Item()
item['image_id'] = each.get('imageid')
item['url'] = each.get('qhimg_url')
item['title'] = each.get('group_title')
item['thumb'] = each.get('qhimg_thumb_url')
yield item
5.编写pipelines.py(存储数据)
import pymysql.cursors class Images360Pipeline(object):
def __init__(self):
self.connect = pymysql.connect(
host='localhost',
user='root',
password='',
database='quotes',
charset='utf8',
)
self.cursor = self.connect.cursor() def process_item(self, item, spider):
item = dict(item)
sql = 'insert into images360(image_id,url,title,thumb) values(%s,%s,%s,%s)'
self.cursor.execute(sql, (item['image_id'], item['url'], item['title'],item['thumb']))
self.connect.commit()
return item def close_spider(self, spider):
self.cursor.close()
self.connect.close()
6.编写settings.py(设置headers,pipelines等)
robox协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
headers
DEFAULT_REQUEST_HEADERS = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
}
pipelines
ITEM_PIPELINES = {
'quote.pipelines.Images360Pipeline': 300,
}
7.运行爬虫
dos窗口输入:
scrapy crawl myspider
运行结果
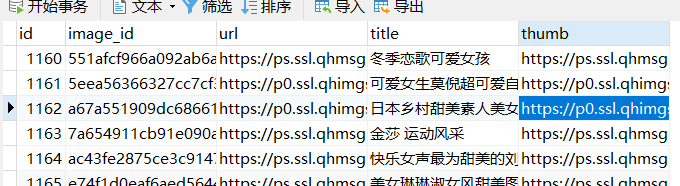
<scrapy爬虫>爬取360妹子图存入mysql(mongoDB还没学会,学会后加上去)的更多相关文章
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- Scrapy框架学习(四)爬取360摄影美图
我们要爬取的网站为http://image.so.com/z?ch=photography,打开开发者工具,页面往下拉,观察到出现了如图所示Ajax请求, 其中list就是图片的详细信息,接着观察到每 ...
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
- <scrapy爬虫>爬取猫眼电影top100详细信息
1.创建scrapy项目 dos窗口输入: scrapy startproject maoyan cd maoyan 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # -*- ...
- <scrapy爬虫>爬取quotes.toscrape.com
1.创建scrapy项目 dos窗口输入: scrapy startproject quote cd quote 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) import ...
- scrapy爬虫爬取小姐姐图片(不羞涩)
这个爬虫主要学习scrapy的item Pipeline 是时候搬出这张图了: 当我们要使用item Pipeline的时候,要现在settings里面取消这几行的注释 我们可以自定义Item Pip ...
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- <scrapy爬虫>爬取校花信息及图片
1.创建scrapy项目 dos窗口输入: scrapy startproject xiaohuar cd xiaohuar 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # ...
- <scrapy爬虫>爬取腾讯社招信息
1.创建scrapy项目 dos窗口输入: scrapy startproject tencent cd tencent 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # - ...
随机推荐
- 39 Ubuntu下配置python的vscode开发环境
0 引言 最近想在ubuntu下搞深度学习,首先配置了python的vscode开发环境.在配置python时,选择了Anaconda3.x,保证了其相对于系统python2.x的独立性.另外,vsc ...
- Caused by: java.sql.SQLSyntaxErrorException: ORA-00932: 数据类型不一致: 应为 NUMBER, 但却获得 BINARY
at org.springframework.aop.framework.ReflectiveMethodInvocation.invokeJoinpoint(ReflectiveMethodInvo ...
- IAsyncResult
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...
- POJ2406-Power Strings-KMP循环节/哈希循环节
Given two strings a and b we define a*b to be their concatenation. For example, if a = "abc&quo ...
- HDU-1226-超级密码-队列+广搜+大数取模
Ignatius花了一个星期的时间终于找到了传说中的宝藏,宝藏被放在一个房间里,房间的门用密码锁起来了,在门旁边的墙上有一些关于密码的提示信息: 密码是一个C进制的数,并且只能由给定的M个数字构成,同 ...
- PAT_A1106#Lowest Price in Supply Chain
Source: PAT A1106 Lowest Price in Supply Chain (25 分) Description: A supply chain is a network of re ...
- Rabbit MQ 基础入门
Rabbit MQ 学习(一)基础入门 简介 RabbitMQ 简介 为什么选择 RabbitMQ RabbitMQ 的模型架构是什么? AMQP 协议是什么? AMQP 常用命令 概念 生产者和消费 ...
- 关于JQuery Ajax 跨域 访问.net WebService
关于这个 jQuery Ajax跨域访问 WebService 前天整了好几个小时没整明白 今天再看一下 结果突然就顿悟了 1.建一个空webApplication --添加--新建项--web服务( ...
- 《转》python数据类型
转自 http://www.cnblogs.com/BeginMan/archive/2013/06/08/3125876.html 一.标准类型函数 cmp():比较大小 str():转换为字符串 ...
- [课后作业] 第001讲:我和Python的第一次亲密接触 | 课后测试题的答案
0. Python 是什么类型的语言? Python是脚本语言 脚本语言(Scripting language)是电脑编程语言,因此也能让开发者藉以编写出让电脑听命行事的程序.以简单的方式快速完成某些 ...