[Phoenix] 五、二级索引
摘要: 目前HBASE只有基于字典序的主键索引,对于非主键过滤条件的查询都会变成扫全表操作,为了解决这个问题Phoenix引入了二级索引功能。然而此二级索引又有别于传统关系型数据库的二级索引,本文将详细描述Phoenix中二级索引功能、用法和原理,希望能够对大家在业务技术选型时起到一些帮助作用。
一、概要
目前HBASE只有基于字典序的主键索引,对于非主键过滤条件的查询都会变成扫全表操作,为了解决这个问题Phoenix引入了二级索引功能。然而此二级索引又有别于传统关系型数据库的二级索引,本文将详细描述Phoenix中二级索引功能、用法和原理,希望能够对大家在业务技术选型时起到一些帮助作用。
二、二级索引
示例表如下(为了能够容易通过HBASE SHELL对照表内容,我们对属性值COLUMN_ENCODED_BYTES设置为0,不对column family进行编码):
CREATE TABLE TEST (
ID VARCHAR NOT NULL PRIMARY KEY,
COL1 VARCHAR,
COL2 VARCHAR
) COLUMN_ENCODED_BYTES=0;
upsert into TEST values('1', '2', '3');1. 全局索引
全局索引更多的应用在读较多的场景。它对应一张独立的HBASE表。对于全局索引,在查询中检索的列如果不在索引表中,默认的索引表将不会被使用,除非使用hint。
创建全局索引:
CREATE INDEX IDX_COL1 ON TEST(COL1)通过HBASE SHELL观察生成的索引表IDX_COL1。我们发现全局索引表的RowKey存储了索引列的值和原表RowKey的值,这样编码更有利于提高查询的性能。
hbase(main):001:0> scan 'IDX_COL1'
ROW COLUMN+CELL
2\x001 column=0:_0, timestamp=1520935113031, value=x
1 row(s) in 0.1650 seconds实际上全局索引的RowKey将会按照如下格式进行编码。
- SALT BYTE: 全局索引表和普通phoenix表一样,可以在创建索引时指定
SALT_BUCKETS或者split key。此byte正是存储着salt。 - TENANT_ID: 当前数据对应的多租户ID。
- INDEX VALUE: 索引数据。
- PK VALUE: 原表的RowKey。
2. 本地索引
因为本地索引和原数据是存储在同一个表中的,所以更适合写多的场景。对于本地索引,查询中无论是否指定hint或者是查询的列是否都在索引表中,都会使用索引表。
创建本地索引:
create local index LOCAL_IDX_COL1 ON TEST(COL1);通过HBASE SHELL观察表'TEST', 我们可以看到表中多了一行column为L#0:_0的索引数据。
hbase(main):001:0> scan 'TEST'
ROW COLUMN+CELL
\x00\x002\x001 column=L#0:_0, timestamp=1520935997600, value=_0
1 column=0:COL1, timestamp=1520935997600, value=2
1 column=0:COL2, timestamp=1520935997600, value=3
1 column=0:_0, timestamp=1520935997600, value=x
2 row(s) in 0.1680 seconds本地索引的RowKey将会按照如下格式进行编码:
- REGION START KEY : 当前row所在region的start key。加上这个start key的好处是,可以让索引数据和原数据尽量在同一个region, 减小IO,提升性能。
- INDEX ID : 每个ID对应不同的索引表。
- TENANT ID :当前数据对应的多租户ID。
- INDEX VALUE: 索引数据。
- PK VALUE: 原表的RowKey。
3. 覆盖索引
覆盖索引的特点是把原数据存储在索引数据表中,这样在查询到索引数据时就不需要再次返回到原表查询,可以直接拿到查询结果。
创建覆盖索引:
create index IDX_COL1_COVER_COL2 on TEST(COL1) include(COL2);通过HBASE SHELL 查询表IDX_COL1_COVER_COL2, 我们发现include的列的值被写入到了value中。
hbase(main):003:0> scan 'IDX_COL1_COVER_COL2'
ROW COLUMN+CELL
2\x001 column=0:0:COL2, timestamp=1520943893821, value=3
2\x001 column=0:_0, timestamp=1520943893821, value=x
1 row(s) in 0.0180 seconds对于类似select col2 from TEST where COL1='2'的查询,查询一次索引表就能获得结果。其查询计划如下:
+--------------------------------------------------------------------------------------+-----------------+----------------+---+
| PLAN | EST_BYTES_READ | EST_ROWS_READ | E |
+--------------------------------------------------------------------------------------+-----------------+----------------+---+
| CLIENT 1-CHUNK PARALLEL 1-WAY ROUND ROBIN RANGE SCAN OVER IDX_COL1_COVER_COL2 ['2'] | null | null | n |
+--------------------------------------------------------------------------------------+-----------------+----------------+---+4. 函数索引
函数索引的特点是能根据表达式创建索引,适用于对查询表,过滤条件是表达式的表创建索引。例如:
//创建函数索引
CREATE INDEX CONCATE_IDX ON TEST (UPPER(COL1||COL2))
//查询函数索引
SELECT * FROM TEST WHERE UPPER(COL1||COL2)='23'三、什么是Phoenix的二级索引?
Phoenix的二级索引我们基本上已经介绍过了,我们回过头来继续看Phoenix二级索引的官方定义:Secondary indexes are an orthogonal way to access data from its primary access path。简单理解为,在主访问路径(通过row key访问)上发生正交的一种方法,更清楚的应该描述为:索引列访问和row key访问产生交集时的一种索引方法。我们来通过一个例子说明:
1. 对表TEST的COL1创建全局索引
CREATE INDEX IDX_COL1 ON TEST(COL1);2. 对于如下查询必将发生FULL SCAN。
select * from TEST where COL1='2';以上查询的查询计划如下:
+----------------------------------------------------------------+-----------------+----------------+--------------+
| PLAN | EST_BYTES_READ | EST_ROWS_READ | EST_INFO_TS |
+----------------------------------------------------------------+-----------------+----------------+--------------+
| CLIENT 1-CHUNK PARALLEL 1-WAY ROUND ROBIN FULL SCAN OVER TEST | null | null | null |
| SERVER FILTER BY COL1 = '2' | null | null | null |
+----------------------------------------------------------------+-----------------+----------------+--------------+3. 对于以下查询将会形成点查。因为二级索引是RowKey的交集。
select * from TEST where id='1' and COL1='2'查询计划如下
+---------------------------------------------------------------------------------------------+-----------------+-------------+
| PLAN | EST_BYTES_READ | EST_ROWS_RE |
+---------------------------------------------------------------------------------------------+-----------------+-------------+
| CLIENT 1-CHUNK 1 ROWS 203 BYTES PARALLEL 1-WAY ROUND ROBIN POINT LOOKUP ON 1 KEY OVER TEST | 203 | 1 |
| SERVER FILTER BY COL1 = '2' | 203 | 1 |
+---------------------------------------------------------------------------------------------+-----------------+-------------+对于2中所描述的查询为什么会发生FULL SCAN? 正如Phoenix二级索引官方定义的一样,因为“没有和RowKey列的查询发生正交关系”,除非使用Hint强制指定索引表。
四、索引Building
Phoenix的二级索引创建有同步和异步两种方式。
- 在执行
CREATE INDEX IDX_COL1 ON TEST(COL1)时会进行索引数据的同步。此方法适用于数据量较小的情况。 - 异步build索引需要借助MR,创建异步索引语法和同步索引相差一个关键字:
ASYNC。
//创建异步索引
CREATE INDEX ASYNC_IDX ON DB.TEST (COL1) ASYNC
//build 索引数据
${HBASE_HOME}/bin/hbase org.apache.phoenix.mapreduce.index.IndexTool --schema DB --data-table TEST --index-table ASYNC_IDX --output-path ASYNC_IDX_HFILES五、索引问题汇总
1. 创建同步索引超时怎么办?
在客户端配置文件hbase-site.xml中,把超时参数设置大一些,足够build索引数据的时间。
<property>
<name>hbase.rpc.timeout</name>
<value>60000000</value>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>60000000</value>
</property>
<property>
<name>phoenix.query.timeoutMs</name>
<value>60000000</value>
</property>2. 索引表最多可以创建多少个?
建议不超过10个
3. 为什么索引表多了,单条写入会变慢?
索引表越多写放大越严重。写放大情况可以参考下图。
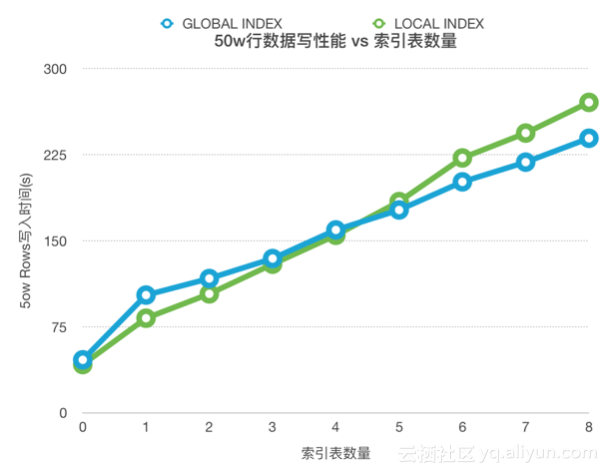
References
- https://phoenix.apache.org/secondary_indexing.html
- https://community.hortonworks.com/articles/61705/art-of-phoenix-secondary-indexes.html
转自:https://yq.aliyun.com/articles/536850
交流
如果大家对HBase有兴趣,致力于使用HBase解决实际的问题,欢迎加入Hbase技术社区群交流:
微信HBase技术社区群,假如微信群加不了,可以加秘书微信: SH_425 ,然后邀请您。

钉钉HBase技术社区群

[Phoenix] 五、二级索引的更多相关文章
- Phoneix(三)HBase集成Phoenix创建二级索引
一.Hbase集成Phoneix 1.下载 在官网http://www.apache.org/dyn/closer.lua/phoenix/中选择提供的镜像站点中下载与安装的HBase版本对应的版本. ...
- phoenix创建二级索引
create table user (id varchar primary key, firstname varchar, lastname varchar); create index user_i ...
- phoenix中添加二级索引
Phoenix创建Hbase二级索引 官方文档 1. 配置Hbase支持Phoenix创建二级索引 1. 添加如下配置到Hbase的Hregionserver节点的hbase-site.xml ...
- 「从零单排HBase 12」HBase二级索引Phoenix使用与最佳实践
Phoenix是构建在HBase上的一个SQL层,能让我们用标准的JDBC APIs对HBase数据进行增删改查,构建二级索引.当然,开源产品嘛,自然需要注意“避坑”啦,阿丸会把使用方式和最佳实践都告 ...
- HBase的二级索引,以及phoenix的安装(需再做一次)
一:HBase的二级索引 1.讲解 uid+ts 11111_20161126111111:查询某一uid的某一个时间段内的数据 查询某一时间段内所有用户的数据:按照时间 索引表 rowkey:ts+ ...
- Phoenix二级索引(Secondary Indexing)的使用
摘要 HBase只提供了一个基于字典排序的主键索引,在查询中你只能通过行键查询或扫描全表来获取数据,使用Phoenix提供的二级索引,可以避免在查询数据时全表扫描,提高查过性能,提升查询效率 测试 ...
- 085 HBase的二级索引,以及phoenix的安装(需再做一次)
一:问题由来 1.举例 有A列与B列,分别是年龄与姓名. 如果想通过年龄查询姓名. 正常的检索是通过rowkey进行检索. 根据年龄查询rowkey,然后根据rowkey进行查找姓名. 这样的效率不高 ...
- Phoenix系列:二级索引(2)
上一篇介绍了Phoenix基于HBase的二级索引的基本知识,这一篇介绍一下和索引相关的一致性和优化相关内容. 一致性的保证 Phoenix客户端在成功提交一个操作并且得到成功响应后,就代表你所做的操 ...
- Phoenix系列:二级索引(1)
Phoenix使用HBase作为后端存储,对于HBase来说,我们通常使用字典序的RowKey来快速访问数据,除此之外,也可以使用自定义的Filter来搜索数据,但是它是基于全表扫描的.而Phoeni ...
随机推荐
- ThinkPHP 条件是一个表里面的两个字段比较
ThinkPHP 条件是一个表里面的两个字段比较 今天群里有人问,thinkphp框架,条件是一个表里的两个字段,怎么查询. 然后就做了下测试: 比如查询出 手机号就是微信号 的用户: (1)首先,正 ...
- vue v-on:click传递动态参数
最近项目中要为一个循环列表动态传送当前点击列的数据,查了很久资料也没有一个完美的解决方案, 新手只能用vue的事件处理器与jquery的选择器做了一个不伦不类的方案,居然也能解决这个问题,作此记录留待 ...
- JAVA算法总结_时间复杂度_Demo
JAVA面试中经常问到排序算法问题,本人结合网络上一些资源整理了编写一下常用的Demo,并附带运行结果,希望能帮助到大家. /** * @Title: 冒泡排序 * @Description: 将数组 ...
- Java Scanner类中next()和nextLine()方法的区别
今天在练习中遇到了调用Scanner类中的nextLine()输入字符串自动跳过的问题,在博客上看了两篇解答,原来是nextLine()误认了前面next()输入时的Enter,但还是想了一会儿才弄清 ...
- 作为一个新人,怎样学习嵌入式Linux?
作为一个新人,怎样学习嵌入式Linux? 在学习嵌入式Linux之前,肯定要有C语言基础.汇编基础有没有无所谓(就那么几条汇编指令,用到了一看就会).尝试着写一些C语言竞赛的题目.它们是纯 ...
- 9.【nuxt起步】-scroll分页加载
面是单页,下面实现一个列表页和分页加载的例子 1.新建pages/list.vue <template> <div> 分页加载列表页面 </div> </te ...
- [反汇编练习] 160个CrackMe之037
[反汇编练习] 160个CrackMe之037. 本系列文章的目的是从一个没有任何经验的新手的角度(其实就是我自己),一步步尝试将160个CrackMe全部破解,如果可以,通过任何方式写出一个类似于注 ...
- 第八讲_图像问答Image Question Answering
第八讲_图像问答Image Question Answering 课程结构 图像问答的描述 具备一系列AI能力:细分识别,物体检测,动作识别,常识推理,知识库推理..... 先要根据问题,判断什么任务 ...
- stateMachine 相关知识
一个state的基本构造,processMessage 以及可选的enter exit 和getName. processMessager是用于处理数据. enter 和exit 则是类似于 面向编程 ...
- 深入理解vue路由的使用
vue-router是Vue.js官方的路由插件,它和vue.js是深度集成的,适合用于构建单页面应用.vue的单页面应用是基于路由和组件的,路由用于设定访问路径,并将路径和组件映射起来.传统的页面应 ...