python爬虫之pyquery学习
相关内容:
- pyquery的介绍
- pyquery的使用
- 安装模块
- 导入模块
- 解析对象初始化
- css选择器
- 在选定元素之后的元素再选取
- 元素的文本、属性等内容的获取
- pyquery执行DOM操作、css操作
- Dom操作
- CSS操作
- 一个利用pyquery爬取豆瓣新书的例子
首发时间:2018-03-09 21:26
pyquery的介绍
- pyquery允许对xml、html文档进行jQuery查询。
- pyquery使用lxml进行快速xml和html操作。
- pyquery是python中的jquery
PyQuery的使用:
1.安装模块:
pip3 install pyquery
2.导入模块:
from pyquery import PyQuery as pq
3.解析对象初始化:
【使用PyQuery初始化解析对象,PyQuery是一个类,直接将要解析的对象作为参数传入即可】
- 解析对象为字符串时字符串初始化 :默认情况下是字符串,如果字符串是一个带http\https前缀的,将会认为是一个url
textParse = pq(html)
- 解析对象为网页时url初始化: 建议使用关键字参数url=
# urlParse = pq('http://www.baidu.com') #1
urlParse = pq(url='http://www.baidu.com') #2 - 解析对象为文件时文件初始化:建议使用关键字参数filename=
fileParse = pq(filename="L:\demo.html")
- 解析完毕后,就可以使用相关函数或变量来进行筛选,可以使用css等来筛选,
4.CSS选择器:
- 利用标签获取:
result = textParse('h2').text() - 利用类选择器:
result3=textParse(".p1").text() - 利用id选择:
result4=textParse("#user").attr("type") - 分组选择:
result5=textParse("p,div").text() - 后代选择器:
result6=textParse("div a").attr.href - 属性选择器:
result7=textParse("[class='p1']").text() - CSS3伪类选择器:
result8=textParse("p:last").text()
(更多的,可以参考css)
5.在选定元素之后的元素再选取:
- find():找出指定子元素 ,find可以有参数,该参数可以是任何 jQuery 选择器的语法,
- filter():对结果进行过滤,找出指定元素 ,filter可以有参数,该参数可以是任何 jQuery 选择器的语法,
- children():获取所有子元素,可以有参数,该参数可以是任何 jQuery 选择器的语法,
- parent():获取父元素,可以有参数,该参数可以是任何 jQuery 选择器的语法,
- parents():获取祖先元素,可以有参数,该参数可以是任何 jQuery 选择器的语法,
- siblings():获取兄弟元素,可以有参数,该参数可以是任何 jQuery 选择器的语法,
from pyquery import PyQuery as pq html="""
<html>
<head>
</head>
<body>
<h2>This is a heading</h2>
<p class="p1">This is a paragraph.</p>
<p class="p2">This is another paragraph.</p>
<div>
123
<a id="a1" href="http://www.baidu.com">hello</a>
</div>
<input type="Button" >
<input id="user" type="text" >
</body>
""" ###初始化
textParse = pq(html)
# urlParse = pq('http://www.baidu.com') #1
# urlParse = pq(url='http://www.baidu.com') #2
# fileParse = pq(filename="L:\demo.html") ##获取
result = textParse('h2').text()
print(result)
result2= textParse('div').html()
print(result2)
result3=textParse(".p1").text()
print(result3)
result4=textParse("#user").attr("type")
print(result4)
result5=textParse("p,div").text()
print(result5)
result6=textParse("div a").attr.href
print(result6)
result7=textParse("[class='p1']").text()
print(result7)
result8=textParse("p:last").text()
print(result8)
result9=textParse("div").find("a").text()
print(result9)
result12=textParse("p").filter(".p1").text()
print(result12)
result10=textParse("div").children()
print(result10)
result11=textParse("a").parent()
print(result11)
6.元素的文本、属性等内容的获取:
attr(attribute):获取属性
result2=textParse("a").attr("href")
attr.xxxx:获取属性xxxx
result21=textParse("a").attr.href
result22=textParse("a").attr.class_
text():获取文本,子元素中也仅仅返回文本
result1=textParse("a").text()
html():获取html,功能与text类似,但返回html标签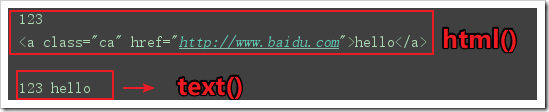
result3=textParse("div").html()
补充1:
元素的迭代:如果返回的结果是多个元素,如果想迭代出每个元素,可以使用items():

补充2:pyquery是jquery的python化,语法基本都是相通的,想了解更多,可以参考jquery。
pyquery执行DOM操作、css操作:
DOM操作:
add_class():增加class
remove_class():移除class
remove():删除指定元素
from pyquery import PyQuery as pq html="""
<html>
<head>
</head>
<body>
<h2>This is a heading</h2>
<p id="p1" class="p1">This is a paragraph.</p>
<p class="p2">This is another paragraph.</p>
<div style="color:blue">
123
<a class="ca" href="http://www.baidu.com">hello</a>
</div>
<input type="Button" >
<input id="user" type="text" >
</body>
""" textParse=pq(html)
textParse('a').add_class("c1")
print(textParse('a').attr("class")) textParse('a').remove_class("c1")
print(textParse('a').attr("class")) print(textParse('div').html())
textParse('div').remove("a")
print(textParse('div').html())
css操作:
- attr():设置属性
- 设置格式:attr("属性名","属性值")
- css():设置css
- 设置格式1:css("css样式","样式值")
- 格式2:css({"样式1":"样式值","样式2":"样式值"})
from pyquery import PyQuery as pq html="""
<html>
<head>
</head>
<body>
<h2>This is a heading</h2>
<p id="p1" class="p1">This is a paragraph.</p>
<p class="p2">This is another paragraph.</p>
<div style="color:blue">
123
<a class="ca" href="http://www.baidu.com">hello</a>
</div>
<input type="Button" >
<input id="user" type="text" >
</body>
""" textParse=pq(html)
textParse('a').attr("name","hehe")
print(textParse('a').attr("name")) textParse('a').css("color","white")
textParse('a').css({"background-color":"black","postion":"fixed"})
print(textParse('a').attr("style"))
这些操作什么时候会被用到:
【有时候可能会将数据样式处理一下再存储下来,就需要用到,比如我获取下来的数据样式我不满意,可以自定义成我自己的格式】
【有时候需要逐层清理再筛选出指定结果,比如<div>123<a></a></div>中,如果仅仅想要获取123就可以先删除<a>再获取】
一个利用pyquery爬取豆瓣新书的例子:
先使用审查元素,定位目标元素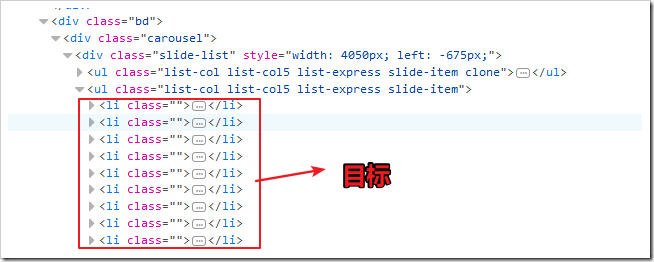
确认爬取信息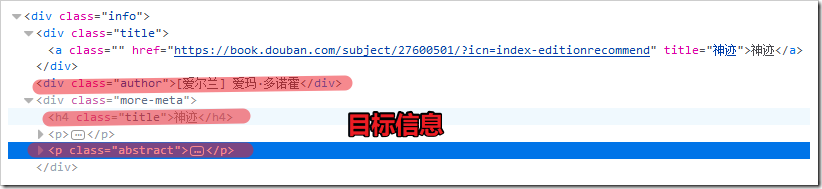
要注意的是,豆瓣新书是有一些分在后面页的,实际上目标应该是li的上一级ul: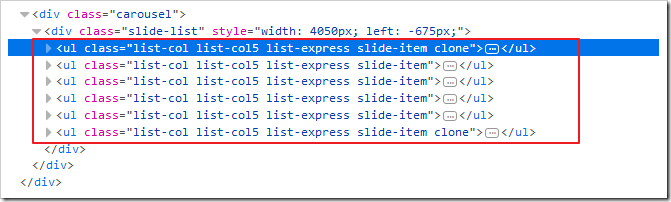
使用PyQuery筛选出结果:
from pyquery import PyQuery as pq
urlParse=pq(url="https://book.douban.com/")
info=urlParse("div.carousel ul li div.info")
file=open("demo.txt","w",encoding="utf8")
for i in info.items():
title=i.find("div.title")
author=i.find("span.author")
abstract=i.find(".abstract")
file.write("标题:"+title.text()+"\n")
file.write("作者:"+author.text()+"\n")
file.write("概要:"+abstract.text()+"\n")
file.write("-----------------\n")
print("\n")
file.close()
python爬虫之pyquery学习的更多相关文章
- Python爬虫之PyQuery使用(六)
Python爬虫之PyQuery使用 PyQuery简介 pyquery能够通过选择器精确定位 DOM 树中的目标并进行操作.pyquery相当于jQuery的python实现,可以用于解析HTML网 ...
- 专业的“python爬虫工程师”需要学习哪些知识?
学到哪种程度 暂且把目标定位初级爬虫工程师,简单列一下吧: (必要部分) 熟悉多线程编程.网络编程.HTTP协议相关 开发过完整爬虫项目(最好有全站爬虫经验,这个下面会说到) 反爬相关,cookie. ...
- python爬虫之Scrapy学习
在爬虫的路上,学习scrapy是一个必不可少的环节.也许有好多朋友此时此刻也正在接触并学习scrapy,那么很好,我们一起学习.开始接触scrapy的朋友可能会有些疑惑,毕竟是一个框架,上来不知从何学 ...
- python爬虫神器PyQuery的使用方法
你是否觉得 XPath 的用法多少有点晦涩难记呢? 你是否觉得 BeautifulSoup 的语法多少有些悭吝难懂呢? 你是否甚至还在苦苦研究正则表达式却因为少些了一个点而抓狂呢? 你是否已经有了一些 ...
- Python 爬虫如何入门学习?
"入门"是良好的动机,但是可能作用缓慢.如果你手里或者脑子里有一个项目,那么实践起来你会被目标驱动,而不会像学习模块一样慢慢学习. 另外如果说知识体系里的每一个知识点是图里的点,依 ...
- python爬虫之PyQuery的基本使用
PyQuery库也是一个非常强大又灵活的网页解析库,如果你有前端开发经验的,都应该接触过jQuery,那么PyQuery就是你非常绝佳的选择,PyQuery 是 Python 仿照 jQuery 的严 ...
- python爬虫解析库学习
一.xpath库使用: 1.基本规则: 2.将文件转为HTML对象: html = etree.parse('./test.html', etree.HTMLParser()) result = et ...
- 【Python爬虫】PyQuery解析库
PyQuery解析库 阅读目录 初始化 基本CSS选择器 查找元素 遍历 获取信息 DOM操作 伪类选择器 PyQuery 是 Python 仿照 jQuery 的严格实现.语法与 jQuery 几乎 ...
- Python爬虫之pyquery库的基本使用
# 字符串初始化 html = ''' <div> <ul> <li class = "item-0">first item</li> ...
随机推荐
- javaScript 二分查找
什么是二分查找的,举个栗子: var arr = [1, 3, 5, 7, 9, 11, 14, 15, 17, 19, 20]; 上面有序数组, 随便给你一位 9 ,输出该数在数组中的索引. 当 ...
- 注意:Tomcat Get请求的坑!
Tomcat8.5,当Get请求中包含了未经编码的中文字符时,会报以下错误,请求未到应用程序在Tomcat层就被拦截了. Tomcat报错: java.lang.IllegalArgumentExce ...
- 如何用python爬取两个span之间的内容
Python用做数据处理还是相当不错的,如果你想要做爬虫,Python是很好的选择,它有很多已经写好的类包,只要调用,即可完成很多复杂的功能,此文中所有的功能都是基于BeautifulSoup这个包. ...
- 微信开放平台创建android应用时怎么获取应用签名
之前微信开放平台中申请创建应用,没有整理,过了好久,又重新百度,今天索性整理了,以供童鞋们备用. 1.微信开发平台注册申请成开发者账号,就此略过 2.在管理中心选择创建移动应用.按照严格要求填写.上传 ...
- 全网最详细的Eclipse和MyEclipse里对于Java web项目发布到Tomcat上运行成功的对比事宜【博主强烈推荐】【适合普通的还是Maven方式创建的】(图文详解)
不多说,直接上干货! 首先,大家要明确,IDEA.Eclipse和MyEclipse等编辑器之间的新建和运行手法是不一样的. 全网最详细的MyEclipse里如何正确新建普通的Java web项目并发 ...
- Java工程师学习指南 初级篇
Java工程师学习指南 初级篇 最近有很多小伙伴来问我,Java小白如何入门,如何安排学习路线,每一步应该怎么走比较好.原本我以为之前的几篇文章已经可以解决大家的问题了,其实不然,因为我之前写的文章都 ...
- PHP正则表达式修饰符的种类及介绍
◆i :如果在修饰符中加上"i",则正则将会取消大小写敏感性,即"a"和"A" 是一样的.◆m:默认的正则开始"^"和结 ...
- #7 Python顺序、条件、循环语句
前言 上一节讲解了Python的数据类型和运算,本节将继续深入,涉及Python的语句结构,相当于Python的语法,是以后编写程序的重要基础! 一.顺序语句 顺序语句很好理解,就是按程序的顺序逻辑编 ...
- SpringMVC入门学习(一)
SpringMVC入门学习(一) ssm框架 spring SpringMVC是一个Java WEB框架,现在我们知道Spring了,那么,何为MVC呢? MVC是一种设计模式,其分为3个方面 mo ...
- netty源码解解析(4.0)-8 ChannelPipeline的设计
io.netty.channel.ChannelPipeline 设计原理 上图中,为了更直观地展示事件处理顺序, 故意有规律地放置两种handler的顺序,实际上ChannelInboundHa ...