Scrapy五大核心组件工作流程
一.Scrapy五大核心组件工作流程
1.核心组件
# 引擎(Scrapy)
对整个系统的数据流进行处理, 触发事务(框架核心).
# 调度器(Scheduler)
用来接受引擎发过来的请求. 由过滤器过滤重复的url并将其压入队列中, 在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么.
# 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的).
# 爬虫(Spiders)
爬虫是主要干活的, 它可以生成url, 并从特定的url中提取自己需要的信息, 即所谓的实体(Item). 用户也可以从中提取出链接, 让Scrapy继续抓取下一个页面.
# 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体, 主要的功能是持久化实体、验证实体的有效性、清除不需要的信息. 当页面被爬虫解析后, 将被发送到项目管道, 并经过几个特定的次序处理数据.
2.工作流程
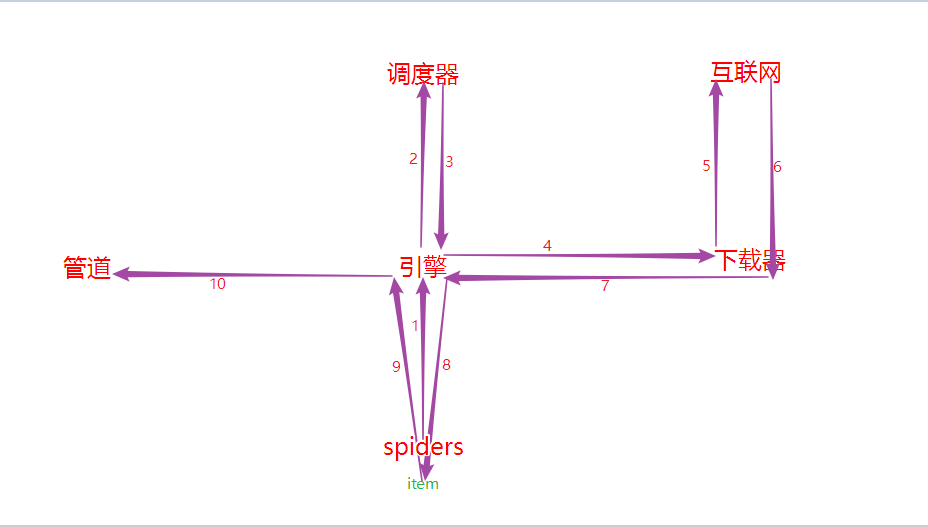
- spider中的url被封装成请求对象交给引擎(每一个url对应一个请求对象);
- 引擎拿到请求对象之后, 将其全部交给调度器;
- 调度器拿到所有请求对象后, 通过内部的过滤器过滤掉重复的url, 最后将去重后的所有url对应的请求对象压入到队列中, 随后调度器调度出其中一个请求对象, 并将其交给引擎;
- 引擎将调度器调度出的请求对象交给下载器;
- 下载器拿到该请求对象去互联网中下载数据;
- 数据下载成功后会被封装到response中, 随后response会被交给下载器;
- 下载器将response交给引擎;
- 引擎将response交给spiders;
- spiders拿到response后调用回调方法进行数据解析, 解析成功后产生item, 随后spiders将item交给引擎;
- 引擎将item交给管道, 管道拿到item后进行数据的持久化存储.
Scrapy五大核心组件工作流程的更多相关文章
- scrapy 五大核心组件-分页
scrapy 五大核心组件-分页 分页 思路 总的原理和之前是一样的,但是由于框架的原因,要遵循他框架的使用方式,每次更改他的url,并指定回调函数 # -*- coding: utf-8 -*- i ...
- scrapy五大核心组件
scrapy五大核心组件 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- scrapy核心组件工作流程和post请求
一 . 五大核心组件的工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返 ...
- scrapy五大核心组件和中间件以及UA池和代理池
五大核心组件的工作流程 引擎(Scrapy) 用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- Scrapy五大核心组件简介
五大核心组件 scrapy框架主要由五大组件组成,他们分别是调度器(Scheduler),下载器(Downloader),爬虫(Spider),和实体管道(Item Pipeline),Scrapy引 ...
- 爬虫-scrapy五大核心组件及工作流
- scrapy框架post请求发送,五大核心组件,日志等级,请求传参
一.post请求发送 - 问题:爬虫文件的代码中,我们从来没有手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确是进行了请求的发送,那这是如何实现的呢? - 解答: ...
- Scrapy中的核心工作流程以及POST请求
五大核心组件工作流程 post请求发送 递归爬取 五大核心组件工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, ...
- scrapy之五大核心组件
scrapy之五大核心组件 scrapy一共有五大核心组件,分别为引擎.下载器.调度器.spider(爬虫文件).管道. 爬虫文件的作用: a. 解析数据 b. 发请求 调度器: a. 队列 队列是一 ...
随机推荐
- 【SCOI2007】降雨量
新人求助,降雨量那题本机AC提交WAWAWA…… 原题: 我们常常会说这样的话:“X年是自Y年以来降雨量最多的”.它的含义是X年的降雨量不超过Y年,且对于任意Y<Z<X,Z年的降雨量严格小 ...
- 大数据之路week04--day05(java XML解析)
java解析XML的四种方式: XML是一种通用的数据交换格式,它的平台无关性.语言无关性.系统无关性.给数据集成与交互带来了极大的方便.XML在不同的语言环境中解析方式都是一样的,只不过实现的语法不 ...
- api文档设计工具:RAML、Swagger
api文档设计工具是用来描述和辅助API开发的. 一.RAML https://raml.org/ https://wenku.baidu.com/view/9523238d5ef7ba0d4b733 ...
- [Javascript] Create an Image with JavaScript Using Fetch and URL.createObjectURL
Most developers are familiar with using img tags and assigning the src inside of HTML. It is also po ...
- Codevs 1242 布局 2005年USACO(差分约束)
1242 布局 2005年USACO 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题目描述 Description 当排队等候喂食时,奶牛喜欢和它们的朋友站得靠近 ...
- 前端逼死强迫症系列之Html
概述 HTML是英文Hyper Text Mark-up Language(超文本标记语言)的缩写,他是一种制作万维网页面标准语言(标记).相当于定义统一的一套规则,大家都来遵守他,这样就可以让浏览器 ...
- shell 重定向0,1,2
.1和2分别表示标准输入.标准输出和标准错误信息输出,可以用来指定需要重定向的标准输入或输出,比如 >a.txt 表示将错误信息输出到文件a.txt中. #将1,2输出转发给/dev/null设 ...
- P2308 添加括号
P2308 添加括号 题解 一看这题---我能AC 看完这题---我要换题 这题第二问其实就是一个链的石子合并,也就是不用处理环 所以一三问怎么处理??? 数组 mid[ i ][ j ] 记录区间 ...
- 前端知识点回顾——koa和模板引擎
koa 基于Node.js的web框架,koa1只兼容ES5,koa2兼容ES6及以后. const Koa = requier("koa"); const koa = new K ...
- ForkJoinPool 源码分析
ForkJoinPool ForkJoinPool 是一个运行 ForkJoinTask 任务.支持工作窃取和并行计算的线程池 核心参数+创建实例 // 工作者线程驻留任务队列索引位 static f ...