scrapy--使用案例
1.scrapy框架
1.1 安装scrapy
- pip3 install wheel
- 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
- 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
- pip3 install pywin32
- pip3 install scrapy
1.2 简单使用
scrapy创建需要在终端执行命令
- scrapy startproject proName 创建项目
- cd proNme 进入项目文件夹
- scrapy genspider spiderName www.xxx.com 创建一个爬虫文件
1.3 配置文件
不遵从robots协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
进行UA伪装
USER_AGENT = '浏览器USER_AGENT'
进行日志等级设定:
LOG_LEVEL = 'ERROR'
1.4 使用方法
import scrapy
class FirstSpider(scrapy.Spider):
# 爬虫文件的名称:爬虫文件的唯一标识(在spiders子目录下是可以创建多个爬虫文件)
name = 'first'
# 允许的域名,一般注释掉
allowed_domains = ['www.baidu.com']
# 起始的url列表:列表中存放的url会被scrapy自动的进行请求发送
start_urls = ['https://www.baidu.com/', 'https://www.sogou.com/']
# 用作于数据解析:将start_urls列表中对应的url请求成功后的响应数据进行解析
def parse(self, response):
print(response)
- 项目启动命令
- scrapy crawl pro_name
1.5 持久化存储
基于终端指令:
- 特性:只可以将parse方法的返回值存储到本地的磁盘文件中
- 存储指令: scrapy crawl spiderName -o filePath
class XiaopapaSpider(scrapy.Spider):
name = 'qiubai'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/'] # 基于终端指令的持久化存储操作
def parse(self, response):
div_list = response.xpath('//*[@id="content-left"]/div')
all_data = []
for div in div_list:
# scrapy中的xpath返回的列表的列表元素一定是Selector对象,我们最终想要的解析的数据一定是存储在该对象中
# extract()将Selector对象中data参数的值取出
# author = div.xpath('./div[1]/a[2]/h2/text()')[0].extract() # 取第一个
author = div.xpath('./div[1]/a[2]/h2/text()').extract_first() # 也是取第一个
# 列表直接调用extract表示的是将extract作用到每一个列表元素中
content = div.xpath('./a[1]/div/span//text()').extract()
content = ''.join(content)
dic = {'author': author,
'content': content }
all_data.append(dic)
return all_data # response.xpath("xpath 路径") 返回的列表的列表元素是Selector对象,数据存在该对象当中
# extract()将Selector对象中data参数的值取出
# .extract_first() # 取第一个值
# 列表直接调用extract表示的是将extract作用到每一个列表元素中,返回的是一个列表
基于管道:实现流程
1.数据解析
2.在item类中定义相关的属性
3.将解析的数据存储或者封装到一个item类型的对象(items文件中对应类的对象)
4.向管道提交item
5.在管道文件的process_item方法中接收item进行持久化存储
6.在配置文件中开启管道# 管道中需要注意的细节:
- 配置文件中开启管道对应的配置是一个字典,字典中的键值表示的就是某一个管道
- 在管道对应的源文件中其实可以定义多个管道类。一个管道类对应的是一种形式的持久化存储
- 在process_item方法中的return item表示的是将item提交给下一个即将被执行的管道类
- 爬虫文件通过yield item只可以将item提交给第一个(优先级最高)被执行的管道
将同一份数据持久化到不同的平台中
- 分析:
- 1.管道文件中的一个管道类负责数据的一种形式的持久化存储
- 2.爬虫文件向管道提交的item只会提交给优先级最高的那一个管道类
- 3.在管道类的process_item中的return item表示的是将当前管道接收的item返回/提交给
下一个即将被执行的管道类
# 基于管道的持久化存储
# 爬虫.py文件,
def parse(self, response):
div_list = response.xpath('//*[@id="content-left"]/div')
all_data = []
for div in div_list:
#scrapy中的xpath返回的列表的列表元素一定是Selector对象,我们最终想要的解析的
#数据一定是存储在该对象中
#extract()将Selector对象中data参数的值取出
# author = div.xpath('./div[1]/a[2]/h2/text()')[0].extract()
author = div.xpath('./div[1]/a[2]/h2/text()').extract_first()
#列表直接调用extract表示的是将extract作用到每一个列表元素中
content = div.xpath('./a[1]/div/span//text()').extract()
content = ''.join(content)
#将解析的数据存储到item对象
item = QiubaiproItem()
item['author'] = author
item['content'] = content
#将item提交给管道
yield item #item一定是提交给了优先级最高的管道类- items.py文件
# items.py文件
class QiubaiproItem(scrapy.Item):
author = scrapy.Field() #Field可以将其理解成是一个万能的数据类型
content = scrapy.Field()
- pipelines.py文件
- 存储到不同的数据平台中
# pipelines.py文件
#存储到文件中
class QiubaiproPipeline(object):
fp = None
def open_spider(self,spider): # 重写父类方法,只会执行一次,打开文件
print('开始爬虫!')
self.fp = open('qiushibaike.txt','w',encoding='utf-8') #使用来接收爬虫文件提交过来的item,然后将其进行任意形式的持久化存储
#参数item:就是接收到的item对象
#该方法每接收一个item就会调用一次
def process_item(self, item, spider):
author = item['author']
content= item['content'] self.fp.write(author+':'+content+'\n')
return item #item是返回给了下一个即将被执行的管道类 def close_spider(self,spider): # 重写父类方法,只会执行一次,关闭文件
print('结束爬虫!')
self.fp.close() #负责将数据存储到mysql
class MysqlPL(object):
conn = None
cursor = None
def open_spider(self,spider):
self.conn = pymysql.Connect(host='127.0.0.1',
port=3306,
user='root',
password='123',
db='spider',
charset='utf8')
print(self.conn)
def process_item(self,item,spider):
author = item['author']
content = item['content']
sql = 'insert into qiubai values ("%s","%s")'%(author,content)
self.cursor = self.conn.cursor()
try:
self.cursor.execute(sql)
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close() # 存到redis
class RedisPL(object):
conn = None
def open_spider(self,spider):
self.conn = Redis(host='127.0.0.1',port=6379)
print(self.conn)
def process_item(self,item,spider):
self.conn.lpush('all_data',item)
#注意:如果将字典写入redis报错:pip install -U redis==2.10.6
- settings文件
- 注册定义的管道
ITEM_PIPELINES = {
'qiubaiPro.pipelines.QiubaiproPipeline': 300, # 300表示的是优先级,数字越小,优先级就越大
'qiubaiPro.pipelines.MysqlPL': 301,
'qiubaiPro.pipelines.RedisPL': 302,
}
- 分析:
1.6 发送请求
1.6.1 自动请求发送:
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url,callback=self.parse)
1.6.2 手动发送请求:
- 在scrapy中如何进行手动请求发送(GET)
- 使用场景:爬取多个页码对应的页面源码数据
- yield scrapy.Request(url,callback)
- 在scrapy中如何进行手动请求发送(POST)
data = { #post请求的请求参数
'kw':'aaa'
}
yield scrapy.FormRequest(url,formdata=data,callback)
#将多个页码对应的页面数据进行爬取和解析的操作
url = 'https://www.qiushibaike.com/text/page/%d/'#通用的url模板
pageNum = 1
#parse第一次调用表示的是用来解析第一页对应页面中的段子内容和作者
def parse(self, response):
div_list = response.xpath('//*[@id="content-left"]/div')
all_data = []
for div in div_list:
author = div.xpath('./div[1]/a[2]/h2/text()').extract_first()
# 列表直接调用extract表示的是将extract作用到每一个列表元素中
content = div.xpath('./a[1]/div/span//text()').extract()
content = ''.join(content)
# 将解析的数据存储到item对象
item = QiubaiproItem()
item['author'] = author
item['content'] = content
# 将item提交给管道
yield item # item一定是提交给了优先级最高的管道类
if self.pageNum <= 5:
self.pageNum += 1
new_url = format(self.url%self.pageNum)
#手动请求(get)的发送
yield scrapy.Request(new_url,callback=self.parse) # 递归调用parse方法
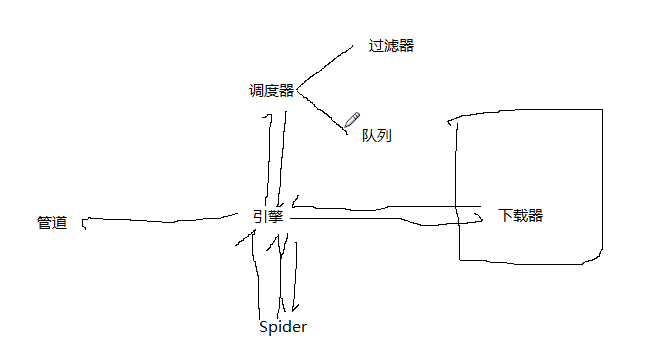
1.7 scrapy五大核心组件的工作流程
- 引擎(Scrapy)
- 用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler)
- 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader)
- 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders)
- 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline)
- 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
scrapy--使用案例的更多相关文章
- 爬虫框架Scrapy之案例三图片下载器
items.py class CoserItem(scrapy.Item): url = scrapy.Field() name = scrapy.Field() info = scrapy.Fiel ...
- 爬虫框架Scrapy之案例二
新浪网分类资讯爬虫 爬取新浪网导航页所有下所有大类.小类.小类里的子链接,以及子链接页面的新闻内容. 效果演示图: items.py import scrapy import sys reload(s ...
- 爬虫框架Scrapy之案例一
阳光热线问政平台 http://wz.sun0769.com/index.php/question/questionType?type=4 爬取投诉帖子的编号.帖子的url.帖子的标题,和帖子里的内容 ...
- 爬虫——Scrapy框架案例二:阳光问政平台
阳光热线问政平台 URL地址:http://wz.sun0769.com/index.php/question/questionType?type=4&page= 爬取字段:帖子的编号.投诉类 ...
- 爬虫——Scrapy框架案例一:手机APP抓包
以爬取斗鱼直播上的信息为例: URL地址:http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset=0 爬取字段:房间ID. ...
- 爬虫 (6)- Scrapy 实战案例 - 爬取不锈钢的相关钢卷信息
超详细创建流程及思路 一. 新建项目 1.创建文件夹,然后在对应文件夹创建一个新的python项目 2.点击Terminal命令行窗口,运行下面的命令创建scrapy项目 scrapy startpr ...
- 爬虫之scrapy简单案例之猫眼
在爬虫py文件下 class TopSpider(scrapy.Spider): name = 'top' allowed_domains = ['maoyan.com'] start_urls = ...
- Scrapy爬虫案例 | 数据存储至MySQL
首先,MySQL创建好数据库和表 然后编写各个模块 item.py import scrapy class JianliItem(scrapy.Item): name = scrapy.Field() ...
- Scrapy爬虫案例 | 数据存储至MongoDB
豆瓣电影TOP 250网址 要求: 1.爬取豆瓣top 250电影名字.演员列表.评分和简介 2.设置随机UserAgent和Proxy 3.爬取到的数据保存到MongoDB数据库 items.py ...
- scrapy爬虫案例:用MongoDB保存数据
用Pymongo保存数据 爬取豆瓣电影top250movie.douban.com/top250的电影数据,并保存在MongoDB中. items.py class DoubanspiderItem( ...
随机推荐
- 轻松了解DNS劫持
对于互联网,人们总是高谈阔论,却很少有人愿意去了解电脑.手机.电视这些设备到底是如何被"连接"起来的.本文通过"我",一个普通的网络请求的视角,给大家介绍下&q ...
- 数据平滑处理-均值|中值|Savitzky-Golay滤波器
均值滤波器 均值滤波器是一种使用频次较高的线性滤波器.它的实现原理很简单,就是指定一个长度大小为奇数的窗口,使用窗口中所有数据的平均值来替换中间位置的值,然后平移该窗口,平移步长为 1,继续重复上述操 ...
- CultureInfo、DateTimeFormatInfo、NumberFormatinfo之间的关系
CultureInfo.DateTimeFormatInfo.NumberFormatinfo之间的关系 线程中CurrentCulture和CurrentUICulture 区别 以下是win10操 ...
- centos7 部署ansible
Ansible默认采用SSH的方式管理客户端,基于python开发,由paramiko和PyYAMl 两个关键模块构建 支持非root用户管理,支持sudo ansible作用:通过使用ansible ...
- Leaflet:Marker、Popup类
Marker.Popup.Tooltip类都是继承自Layer类:Event与Layer Marker 1.用例 L.marker([41,123]).addTo(map); 2.实例化 L.mark ...
- docker学习笔记(6)——docker场景问题汇总(centos7 由于内核版本低带来的一系列问题,docker彻底卸载,安装、启动日志报错分析)
参考资料: https://nachuan.blog.csdn.net/article/details/96041277 https://www.cnblogs.com/xzkzzz/p/962765 ...
- qt(二)
主程序入口: #include <iostream> #include <QApplication> #include "MainWindow.h" int ...
- SQL Server--频繁建立连接和断开连接
使用数据库时,不建议一直与数据库保持连接,最好用时连接用完断开连接. 我的C#程序中采用"用时连接用完断开连接"的方式: 之前是C#程序调用本地数据库,没遇到问题: 后来改为C#程 ...
- 如何实现 UITabbarController 的 State Preservation?
原文链接 最近在看ios programming - the big nerd ranch guide 这本书,其中第24章介绍了如何使用系统接口来实现 State Restoration. 示例部分 ...
- 8、msyql性能分析工具
性能分析工具 1服务器优化的步骤 2查询系统参数 在MySQL中,可以使用 SHOW STATUS 语句查询一些MySQL数据库服务器的性能参数.执行频率 . SHOW STATUS语句语法如下: S ...