sklearn KMeans聚类算法(总结)
基本原理
Kmeans是无监督学习的代表,没有所谓的Y。主要目的是分类,分类的依据就是样本之间的距离。比如要分为K类。步骤是:
- 随机选取K个点。
- 计算每个点到K个质心的距离,分成K个簇。
- 计算K个簇样本的平均值作新的质心
- 循环2、3
- 位置不变,距离完成
距离
Kmeans的基本原理是计算距离。一般有三种距离可选:
- 欧氏距离
\[d(x,u)=\sqrt{\sum_{i=1}^n(x_i-\mu_i)^2}
\] - 曼哈顿距离
\[d(x,u)=\sum_{i=1}^n(|x_i-\mu|)
\] - 余弦距离
\[cos\theta=\frac{\sum_{i=1}^n(x_i*\mu)}{\sqrt{\sum_i^n(x_i)^2}*\sqrt{\sum_1^n(\mu)^2}}
\]
inertia
每个簇内到其质心的距离相加,叫inertia。各个簇的inertia相加的和越小,即簇内越相似。(但是k越大inertia越小,追求k越大对应用无益处)
代码
模拟数据:
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X, y = make_blobs(n_samples=500, # 500个样本
n_features=2, # 每个样本2个特征
centers=4, # 4个中心
random_state=1 #控制随机性
)
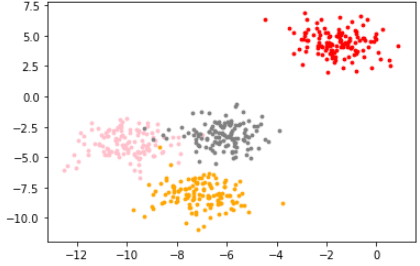
画出图像:
color = ['red', 'pink','orange','gray']
fig, axi1=plt.subplots(1)
for i in range(4):
axi1.scatter(X[y==i, 0], X[y==i,1],
marker='o',
s=8,
c=color[i]
)
plt.show()
使用KMeans类建模:
from sklearn.cluster import KMeans
n_clusters=3
cluster = KMeans(n_clusters=n_clusters,random_state=0).fit(X)
也可先用fit, 再用predict,但是可能数据不准确。用于数据量较大时。
此时就可以查看其属性了:质心、inertia.
centroid=cluster.cluster_centers_
centroid # 查看质心
查看inertia:
inertia=cluster.inertia_
inertia
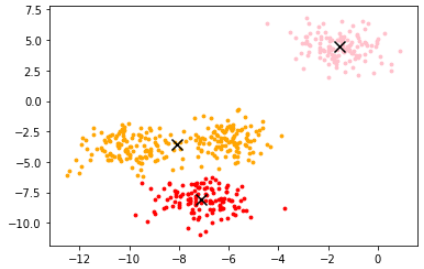
画出所在位置。
color=['red','pink','orange','gray']
fig, axi1=plt.subplots(1)
for i in range(n_clusters):
axi1.scatter(X[y_pred==i, 0], X[y_pred==i, 1],
marker='o',
s=8,
c=color[i])
axi1.scatter(centroid[:,0],centroid[:,1],marker='x',s=100,c='black')
sklearn KMeans聚类算法(总结)的更多相关文章
- 转载: scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- 一步步教你轻松学K-means聚类算法
一步步教你轻松学K-means聚类算法(白宁超 2018年9月13日09:10:33) 导读:k-均值算法(英文:k-means clustering),属于比较常用的算法之一,文本首先介绍聚类的理 ...
- 《数据挖掘导论》实验课——实验七、数据挖掘之K-means聚类算法
实验七.数据挖掘之K-means聚类算法 一.实验目的 1. 理解K-means聚类算法的基本原理 2. 学会用python实现K-means算法 二.实验工具 1. Anaconda 2. skle ...
- K-Means 聚类算法
K-Means 概念定义: K-Means 是一种基于距离的排他的聚类划分方法. 上面的 K-Means 描述中包含了几个概念: 聚类(Clustering):K-Means 是一种聚类分析(Clus ...
- k-means聚类算法python实现
K-means聚类算法 算法优缺点: 优点:容易实现缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他 ...
- K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- Kmeans聚类算法原理与实现
Kmeans聚类算法 1 Kmeans聚类算法的基本原理 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一.K-means算法的基本思想是:以空间中k个点为中心进行聚类,对 ...
- 机器学习六--K-means聚类算法
机器学习六--K-means聚类算法 想想常见的分类算法有决策树.Logistic回归.SVM.贝叶斯等.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别 ...
- 沙湖王 | 用Scipy实现K-means聚类算法
沙湖王 | 用Scipy实现K-means聚类算法 用Scipy实现K-means聚类算法
随机推荐
- winfrom窗体的透明度
在VS中创建一个Winform项目,其默认的窗体名称为 Form1. 在VS设计界面中对 Form1 的 Opacity 属性值设置为 50%. 没错,就这样就可以了. 方法2: ...
- Oozie笔记
简介 Oozie 是用于 Hadoop 平台的开源的工作流调度引擎. 用于管理 Hadoop 属于web应用程序, 由 Oozie client 和 Oozie Server 两个组件构成. Oozi ...
- “战疫”需求不再等-京东云与AI【应急资源信息发布平台】召集开发者共同支援
截止北京时间 2020年2月5日19时00分,全国确诊新型冠状病毒肺炎24423例,疑似23260例. 新年伊始,一切都显得和往年有那么一点不一样.疫情牵动着每一个人的心脏,也有很多人早就放弃了假期投 ...
- 每天一点点之vue框架开发 - 引入bootstrap
只使用css样式 如果在你的项目中只是使用css样式,那就不需要安装,直接全局引入样式就好 <link rel="stylesheet" href="https ...
- 使用dbcp连接mysql
1.创建dbcp.properties 文件 driver=com.mysql.jdbc.Driver url=jdbc:mysql:///zhang username=root password= ...
- java: 集合collection
collection是集合层次结构中的根接口,一些集合允许重复元素,而其他集合不允许. 有些collection是有序的,而另一些是无序的. JDK不提供此接口的任何直接实现:它提供了更具体的子接口的 ...
- [转自官方文档] Django——render()
每个视图都需要做2件事,返回一个包含被请求页面内容的HttpResponse对象或者一个404 快捷函数 render( 请求, 模板, 内容) 载入模板,填充上下文,再返回它生成的HttpResp ...
- ACM蒟蒻防bug专用 ( •̀ ω •́ )✧
/*********************************************** * _ooOoo_ * * o8888888o * * 88" . "88 * * ...
- 吴裕雄--天生自然TensorFlow2教程:合并与分割
import tensorflow as tf # 6个班级的学生分数情况 a = tf.ones([4, 35, 8]) b = tf.ones([2, 35, 8]) c = tf.concat( ...
- kube-proxy详解
KUBE_LOGTOSTDERR="--logtostderr=true"KUBE_LOG_LEVEL="--v=4"NODE_HOSTNAME="- ...