scrapy之五大核心组件
scrapy之五大核心组件
scrapy一共有五大核心组件,分别为引擎、下载器、调度器、spider(爬虫文件)、管道。
爬虫文件的作用:
a. 解析数据
b. 发请求
调度器:
a. 队列
队列是一种数据结构,拥有先进先出的特性。
b. 过滤器
过滤器适用于过滤的,过滤重复的请求。
调度器是用来调度请求对象的。
引擎:
所有的实例化的过程都是由引擎来做的,根据那到的数据流进行判断实例化的时间。
处理流数据
触发事物
scrapy五大核心组件之间的工作流程:
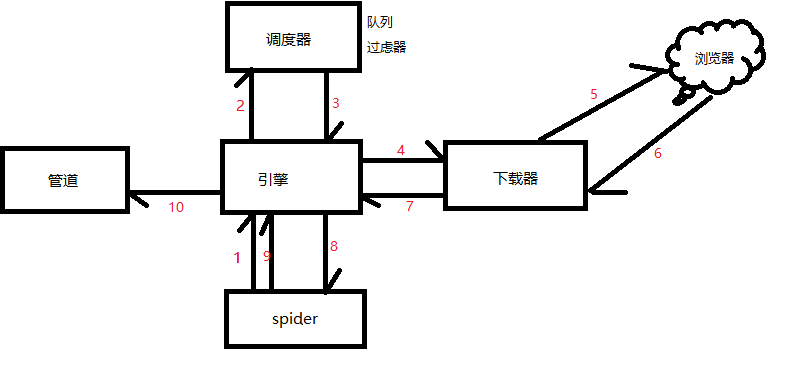
scrapy框架得的五大组件之间的工作流程上图所示:
当我们执行爬虫文件的时候,这五大组件就已经开始工作了 。其中,
1 首先,我们最原始的起始url是在我们爬虫文件中的,通常情况系,起始的url只有一个,当我们的爬虫文件执行的时候,首先对起始url发送请求,将起始url封装成了请求对象,将请求对象传递给了引擎,引擎就收到了爬虫文件给它发送的封装了起始URL的请求对象。我们在爬虫文件中发送的请求并没有拿到响应(没有马上拿到响应),只有请求发送到服务器端,服务器端返回响应,才能拿到响应。
2 引擎拿到这个请求对象以后,又将请求对象发送给了调度器,队列接受到的请求都放到了队列当中,队列中可能存在多个请求对象,然后通过过滤器,去掉重复的请求
3 调度器将过滤后的请求对象发送给了引擎,
4 引擎将拿到的请求对象给了下载器
5 下载器拿到请求后将请求拿到互联网进行数据下载
6 互联网将下载好的数据发送给下载器,此时下载好的数据是封装在响应对象中的
7 下载器将响应对象发送给引擎,引擎接收到了响应对象,此时引擎中存储了从互联网中下载的数据。
8 最终,这个响应对象又由引擎给了spider(爬虫文件),由parse方法中的response对象来接收,然后再parse方法中进行解析数据,此时可能解析到新的url,然后再次发请求;也可能解析到相关的数据,然后将数据进行封装得到item,
9 spider将item发送给引擎,
10 引擎将item发送给管道。
其中,在引擎和下载中间还有一个下载器中间件,spider和引擎中间有爬虫中间件,
下载器中间件
可以拦截请求和响应对象,请求和响应交互的时候一定会经过下载中间件,可以处理请求和响应。
爬虫中间件
拦截请求和响应,对请求和响应进行处理。
0
scrapy之五大核心组件的更多相关文章
- python爬虫---scrapy框架爬取图片,scrapy手动发送请求,发送post请求,提升爬取效率,请求传参(meta),五大核心组件,中间件
# settings 配置 UA USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, l ...
- Scrapy 框架 安装 五大核心组件 settings 配置 管道存储
scrapy 框架的使用 博客: https://www.cnblogs.com/bobo-zhang/p/10561617.html 安装: pip install wheel 下载 Twisted ...
- scrapy框架post请求发送,五大核心组件,日志等级,请求传参
一.post请求发送 - 问题:爬虫文件的代码中,我们从来没有手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确是进行了请求的发送,那这是如何实现的呢? - 解答: ...
- scrapy 五大核心组件-分页
scrapy 五大核心组件-分页 分页 思路 总的原理和之前是一样的,但是由于框架的原因,要遵循他框架的使用方式,每次更改他的url,并指定回调函数 # -*- coding: utf-8 -*- i ...
- Scrapy五大核心组件工作流程
一.Scrapy五大核心组件工作流程 1.核心组件 # 引擎(Scrapy) 对整个系统的数据流进行处理, 触发事务(框架核心). # 调度器(Scheduler) 用来接受引擎发过来的请求. 由过滤 ...
- scrapy五大核心组件和中间件以及UA池和代理池
五大核心组件的工作流程 引擎(Scrapy) 用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- Scrapy五大核心组件简介
五大核心组件 scrapy框架主要由五大组件组成,他们分别是调度器(Scheduler),下载器(Downloader),爬虫(Spider),和实体管道(Item Pipeline),Scrapy引 ...
- scrapy五大核心组件
scrapy五大核心组件 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- Spring MVC(一)五大核心组件和配置
一,五大核心组件 1.DispatcherServlet 请求入口 2.HandlerMapping 请求派发,负责请求和控制器建立一一对应的关系 3.Controller 处理器 4.Mod ...
随机推荐
- Visio画图--我的形状
本人用的Visio 2013 打开Visio后新建一个拓扑图,发现左侧形状一栏不见了 形状栏可以保存很多自定义图形,怎么才能将形状一栏重新显示出来呢?方法其实很简单,方法如下所示: 这时候我们就会发现 ...
- java实现支付宝支付及退款(二)
紧跟上篇博客,本篇将书写具体的代码实现 开发环境:SSM.maven.JDK8.0 1.Maven坐标 <!--阿里支付--> <dependency> <groupId ...
- 编译&链接笔记
无法解析的外部符号? 1)库的版本不对,换成X64或Win32试试
- Nginx使用教程(五):使用Nginx缓存之缓存静态内容
NGINX虽然已经对静态内容做过优化. 但在高流量网站的情况下,仍然可以使用open_file_cache进一步提高性能. NGINX缓存将最近使用的文件描述符和相关元数据(如修改时间,大小等)存储在 ...
- UVA208-Firetruck(并查集+dfs)
Problem UVA208-Firetruck Accept:1733 Submit:14538 Time Limit: 3000 mSec Problem Description The Ce ...
- Python之TabError: inconsistent use of tabs and spaces in indentation和ModuleNotFoundError:No module named 'win32api'
1.TabError: inconsistent use of tabs and spaces in indentation 这是我的代码,感觉没啥不对, 后来运行之后出现了下面的错误,我也是弄了好久 ...
- maven-resources-plugin插件关于占位符不生效问题
插件版本: <plugin> <artifactId>maven-resources-plugin</artifactId> <version>3.0. ...
- 【转】iOS弹幕库OCBarrage-如何hold住每秒5000条巨量弹幕
最近公司做新需求, 原来用的老弹幕库, 已经无法满足需要. 迫不得已自己写了一套弹幕库OCBarrage. 这套弹幕库轻量, 可拓展, 高度自定义, 超高性能, 简单易上手. 无论哪家公司软件的性能绝 ...
- 【angularjs】pc端使用angular搭建项目,实现导出excel功能
此为简单demo. <!DOCTYPE html> <html ng-app="myApp"> <head> <meta charset= ...
- 【vue】vue中引入jquery
简洁版: 第一步:首先在package.json中输入"jquery":"^3.2.1",其中“3.2.1”为jquery版本号,按需修改 注:package. ...