大数据小白系列——HDFS(3)
这里是大数据小白系列,这是本系列的第三篇,介绍HDFS中NameNode选举,JournalNode等概念。
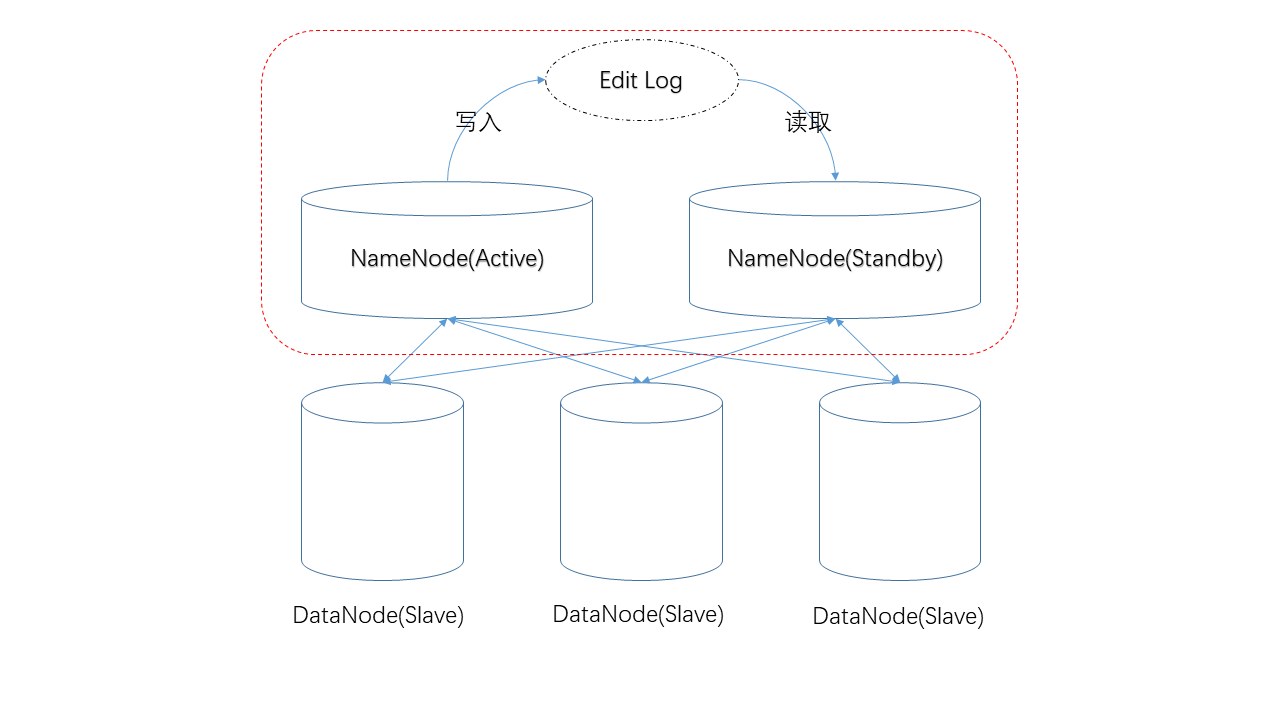
上一期我们说到了为解决NameNode(下称NN)单点失败问题,HDFS中使用了双NN的机制,一个Active NN,一个Standby NN。
现实常常是,解决一个问题的同时,免不了又引入了另外的问题。
谁来担任Active,谁来担任Standby?
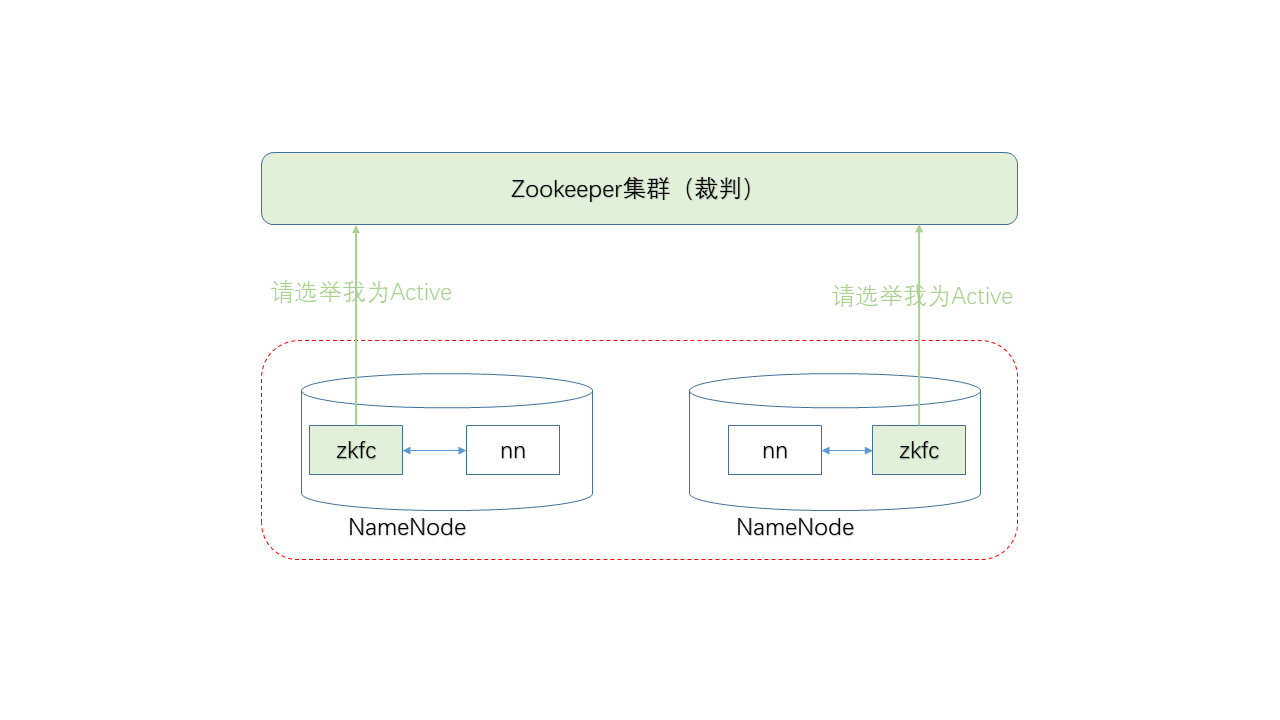
两个NN谁也说服不了谁,这个时候需要引入一个外部角色:一个Zookeeper(下称ZK)集群。
ZK也是个很有趣的东西,大数据小白系列后续会专门介绍。
这里,ZK集群扮演了类似裁判的角色,如果两个NN同时申请成为Active,由ZK决定谁将获胜。
两台NN机器上都分别存在一个ZKCF(Zookeeper Failover Controller)进程,该进程相当于ZK的一个客户端。
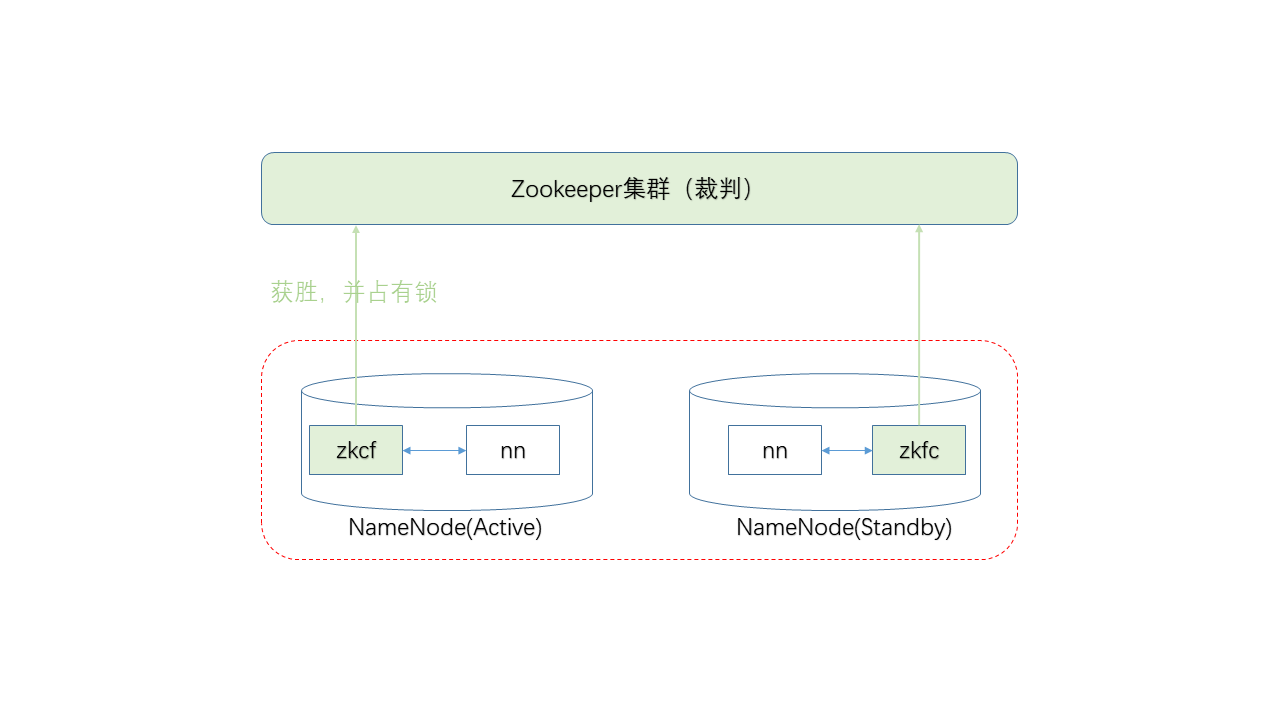
ZKFC定期检查NN进程的状态,如状态正常,并且目前没有其他NN在持有ZK集群上的锁,则加入选举,并且申请锁。(注:所谓的锁,实际上是ZK集群上的一种特殊目录)
若ZKFC检查NN进程不正常,则退出选举,并放弃ZK上的锁(如持有)。
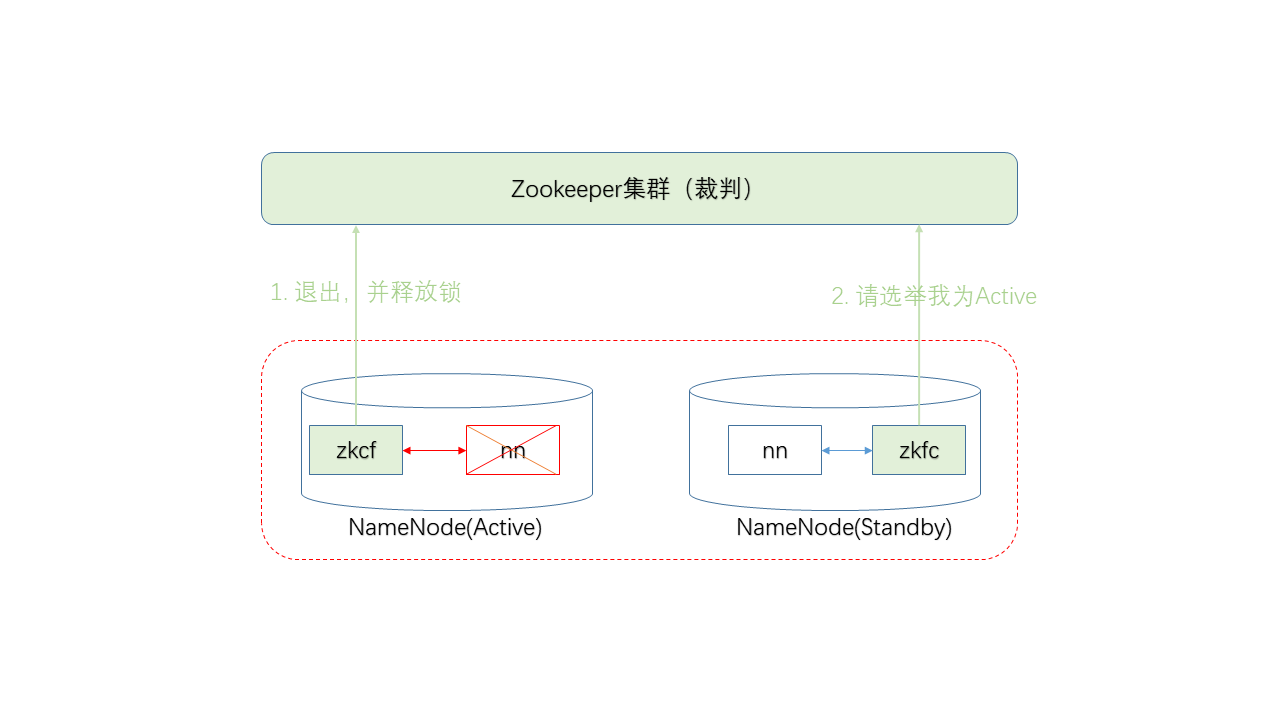
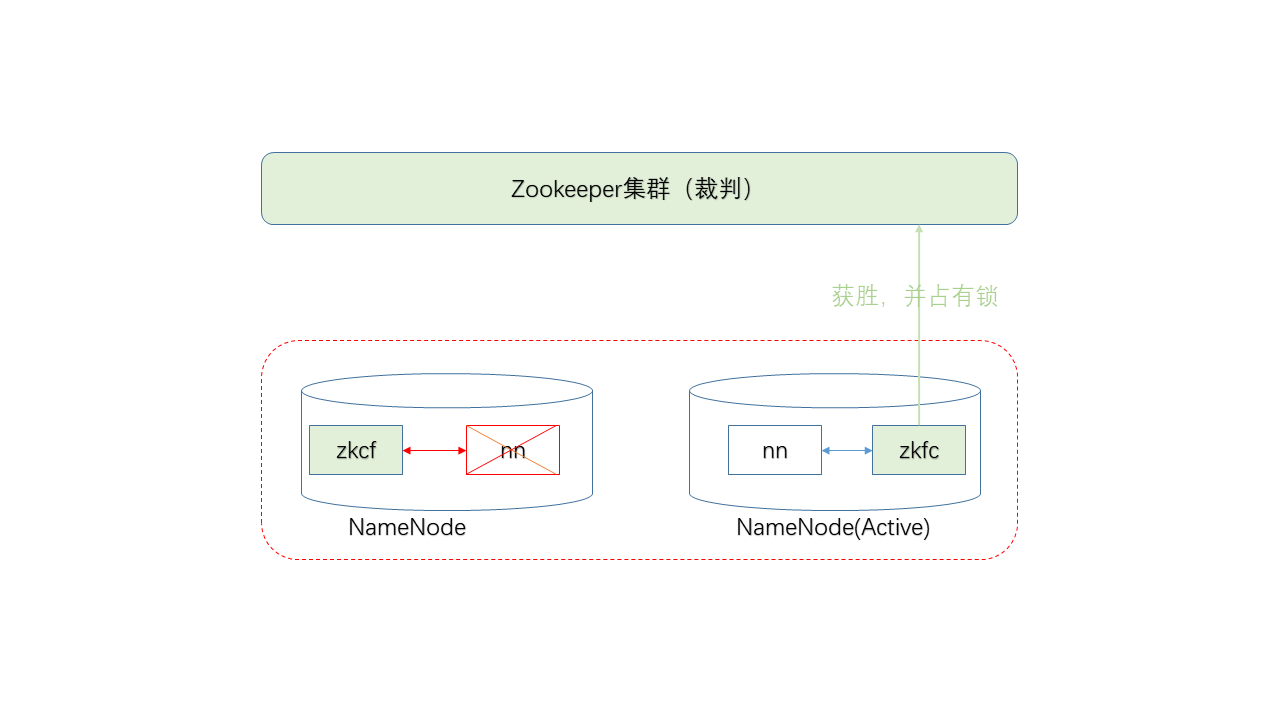
Q:如果不是NN进程死了,而是整个NN机器掉电了呢?
A:当集群与ZKFC进程的连接断开超过一定时间,锁将自动过期,以便其他NN可以申请重新选举。
Q:如果Active、Standby都死了呢?
A:不好意思,那就死透了。
上一期提到的另外一个内容,Active NN负责将Edit Log写入某个“共享存储”,而Standby NN负责从该位置读取以保持同步。
最简单的,可以使用NFS(Network File System)来担任共享存储。
但是NFS本身成为了单点失败,即,如果NFS系统坏了,导致Edit Log无法读写,整个HDFS系统也就无法工作。
因此,HDFS推荐使用的是专为Edit Log高可用性所设计的“JournalNode(下称JN))集群”。
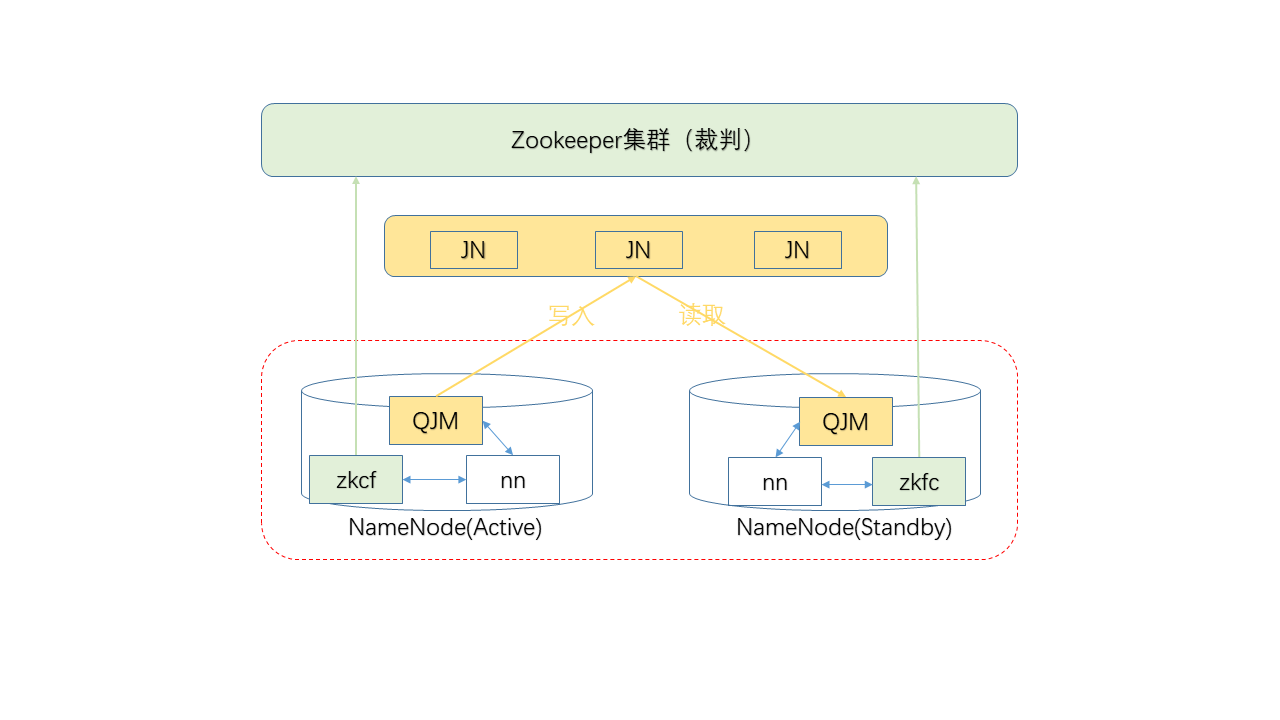
NN通过QJM(Quorum Journal Manager)进程将Edit Log写入某JN节点,该JN节点需要将数据写入其他JN节点,直到数据被写入集群中的“多数节点”,本次操作才算成功。
例如,JN集群中共有3个节点,需要写入到其中2个节点,即所谓的“多数”(majority)。
通常,JN集群总是包含奇数个节点,至于为什么,我准备在介绍ZK的时候再来说明,因为二者比较类似。
需要注意,虽然QJM的工作机制类似于ZK,但本身并没有用到ZK,同时它也比ZK来的轻量级,它可以跑在集群现有的机器上,而不需要单独为它准备机器。
好了,这期就先到这,下期我们将介绍现实世界中的HDFS集群,以及Federation等概念。Cheers!
作者公众号“程序员杂书馆”,专注大数据,欢迎关注,每位关注者将获赠《Spark快速大数据分析》纸质书一本

大数据小白系列——HDFS(3)的更多相关文章
- 大数据小白系列——HDFS(4)
这里是大数据小白系列,这是本系列的第四篇,来看一个真实世界Hadoop集群的规模,以及我们为什么需要Hadoop Federation. 首先,我们先要来个直观的印象,这是你以为的Hadoop集群: ...
- 大数据小白系列——HDFS(2)
这里是大数据小白系列,这是本系列的第二篇,介绍一下HDFS中SecondaryNameNode.单点失败(SPOF).以及高可用(HA)等概念. 上一篇我们说到了大数据.分布式存储,以及HDFS中的一 ...
- 大数据小白系列——HDFS(1)
[注1:结尾有大福利!] [注2:想写一个大数据小白系列,介绍大数据生态系统中的主要成员,理解其原理,明白其用途,万一有用呢,对不对.] 大数据是什么?抛开那些高大上但笼统的说法,其实大数据说的是两件 ...
- 大数据小白系列——MR(1)
一部编程发展史就是一部程序员偷懒史,MapReduce(下称MR)同样是程序员们用来偷懒的工具. 来了一份大数据,我们写了一个程序准备分析它,需要怎么做? 老式的处理方法不行,数据量太大时,所需的时间 ...
- 大数据小白系列 —— MapReduce流程的深入说明
上一期我们介绍了MR的基本流程与概念,本期稍微深入了解一下这个流程,尤其是比较重要但相对较少被提及的Shuffling过程. Mapping 上期我们说过,每一个mapper进程接收并处理一块数据,这 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
随机推荐
- python之内置模块random(转载)
转载自http://www.cnblogs.com/wcwnina/p/9281334.html random.seed(a=None, version=2) # 初始化伪随机数生成器,若种子a相同, ...
- django 中自定义过滤器
多参数过滤器
- Socket网络编程(二)
udp协议发送消息案例 1.创建UdpServer(udp服务器端) package com.cppdy.udp; import java.net.DatagramPacket; import jav ...
- 使用gulp-babel转换Es6出现exports is not defined 问题
//问题描述:当使用import导入模块时,出现exports is not defined //1.安装插件 npm install --save-dev babel-plugin-transfor ...
- 《剑指offer》二叉搜索树的后序遍历序列
本题来自<剑指offer> 二叉搜索树的后序遍历序列 题目: 输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果.如果是则输出Yes,否则输出No.假设输入的数组的任意两个数字 ...
- Nginx详解四:Nginx基础篇之目录和配置语法
一.安装目录 命令:rpm -ql nginx 二.编译参数 命令:nginx -V 三.Nginx基本配置语法 修改主配置文件 当Nginx读配置文件读到include /etc/nginx/con ...
- Error: Java VM internal error:Error Loading javai.dll
因为前几天的JMS测试,第一次写了loadrunner的脚本,感觉路一下子宽了. 知道loadrunner可以使用java写脚本,今天就试了一下,遇到了两个第一次写Java Vuser脚本普遍都会遇到 ...
- java数据
因为曾经干了啥事儿,才印象特别深刻. 将byte存入String的后果 String res = ""; res += (char) 0xc3; byte[] bytes = re ...
- Parameter 'name' not found. Available parameters are [arg1, arg0, param1, param2]
解决方法: <select id="selectIf" resultType="student"> SELECT id,name,age,score ...
- 让Mysql支持Emoji表情,解决[Err] 1366 - Incorrect string value: '\xF0\xA3\x84\x83'
mysql insert内容包含表情或者unicode码时候,插入Mysql时失败了,报如下异常: java.sql.SQLException: Incorrect string value: '\x ...