五 web爬虫,scrapy模块,解决重复ur——自动递归url
一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过
记录url可以是缓存,或者数据库,如果保存数据库按照以下方式:
id URL加密(建索引以便查询) 原始URL
保存URL表里应该至少有以上3个字段
1、URL加密(建索引以便查询)字段:用来查询这样速度快,
2、原始URL,用来给加密url做对比,防止加密不同的URL出现同样的加密值
自动递归url

# -*- coding: utf-8 -*-
import scrapy #导入爬虫模块
from scrapy.selector import HtmlXPathSelector #导入HtmlXPathSelector模块
from scrapy.selector import Selector class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['hao.360.cn']
start_urls = ['https://hao.360.cn/'] def parse(self, response): #这里做页面的各种获取以及处理 #递归查找url循环执行
hq_url = Selector(response=response).xpath('//a/@href') #查找到当前页面的所有a标签的href,也就是url
for url in hq_url: #循环url
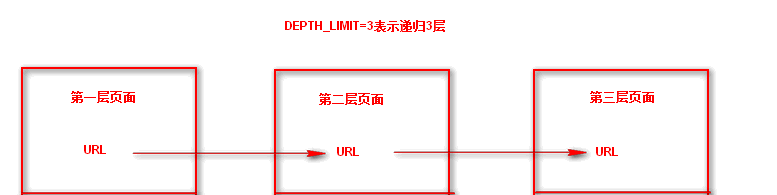
yield scrapy.Request(url=url, callback=self.parse) #每次循环将url传入Request方法进行继续抓取,callback执行parse回调函数,递归循环 #这样就会递归抓取url并且自动执行了,但是需要在settings.py 配置文件中设置递归深度,DEPTH_LIMIT=3表示递归3层
这样就会递归抓取url并且自动执行了,但是需要在settings.py 配置文件中设置递归深度,DEPTH_LIMIT=3表示递归3层
五 web爬虫,scrapy模块,解决重复ur——自动递归url的更多相关文章
- 第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url 一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 ...
- 爬虫scrapy模块
首先下载scrapy模块 这里有惊喜 https://www.cnblogs.com/bobo-zhang/p/10068997.html 创建一个scrapy文件 首先在终端找到一个文件夹 输入 s ...
- 十五 web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块,然后将网页数据通过lxml下的etree转化为treedata的形式 urllib库中使用xpath表 ...
- (4)分布式下的爬虫Scrapy应该如何做-规则自动爬取及命令行下传参
本次探讨的主题是规则爬取的实现及命令行下的自定义参数的传递,规则下的爬虫在我看来才是真正意义上的爬虫. 我们选从逻辑上来看,这种爬虫是如何工作的: 我们给定一个起点的url link ,进入页面之后提 ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百二十四节,web爬虫,scrapy模块介绍与使用
第三百二十四节,web爬虫,scrapy模块介绍与使用 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- 第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装 当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip ...
- 二 web爬虫,scrapy模块以及相关依赖模块安装
当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip install Scrapy 手动源码安装,比较麻烦要自己手动安 ...
随机推荐
- Linux基础命令(一)
一.开启Linux操作系统,要求以root用户登录GNOME图形界面,语言支持选择为汉语没有图形界面 二.使用快捷键切换到虚拟终端2,使用普通用户身份登录,查看系统提示符 Ctrl + Alt + F ...
- 转!!xss漏洞
参考资料 https://blog.csdn.net/jiangzhexi/article/details/56841793 http://www.freebuf.com/articles/web/4 ...
- 原!!win7-64 安装python的 redis客户端库
安装python的redis客户端库 本人系统已装python2.7 利用cmd命令行: 1.cmd-->python -->>>进入python命令下 >>> ...
- R-CNN for Small Object Detection
R-CNN for Small Object Detection 文章方法概括 这篇文章主要讨论针对小目标的目标检测 文章为了证明:对传统R-CNN style的方法进行改进,可以用于小目标检测,并且 ...
- EJB远程客户端和本地客户端
在客户端中使用企业bean 企业bean的客户端通过依赖注入或JNDI查询的方式获得对企业bean实例的引用. 依赖注入是获得对企业bean实例的引用的最简便的方法. (紧耦合的bean之间相互依赖, ...
- 007-Centos 7.x 安装 Mysql 5.7.13
1. 下载mysql的repo源 CentOS 7.2的yum源中默认没有mysql,要先下载mysql的repo源 wget http://repo.mysql.com/mysql57-commun ...
- Redis七(发布订阅)
发布与订阅(pub/sub) 介绍 Redis 通过 PUBLISH . SUBSCRIBE 等命令实现了订阅与发布模式, 这个功能提供两种信息机制, 分别是订阅/发布到频道和订阅/发布到模式 订阅者 ...
- jmeter 非GUI模式下测试报错An error occurred: Unknown arg:
D:\download\性能工具\JMeter\apache-jmeter-2.11\apache-jmeter-2.11\bin>jmeter -n -t E:\性能测试\jmeter scr ...
- 其他机器访问本机redis服务器
- ORACLE 多表连接与子查询
Oracle表连接 SQL/Oracle使用表连接从多个表中查询数据 语法格式: select 字段列表from table1,table2where table1.column1=table2.co ...