Kafka详解二:如何配置Kafka集群
问题导读
1.Kafka有哪几种配制方法?
2.如何启动一个Consumer实例来消费消息?
Kafka集群配置比较简单,为了更好的让大家理解,在这里要分别介绍下面三种配置
- 单节点:一个broker的集群
- 单节点:多个broker的集群
- 多节点:多broker集群
一、单节点单broker实例的配置
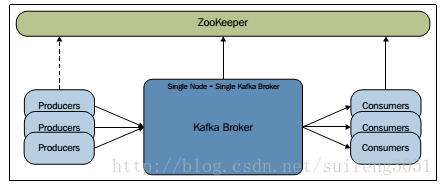
1. 首先启动zookeeper服务 Kafka本身提供了启动zookeeper的脚本(在kafka/bin/目录下)和zookeeper配置文件(在kafka/config/目录下),首先进入Kafka的主目录(可通过 whereis kafka命令查找到):
[root@localhost kafka-0.8]# bin/zookeeper-server-start.sh config/zookeeper.properties
zookeeper配置文件的一些重要属性:
# Data directory where the zookeeper snapshot is stored.
dataDir=/tmp/zookeeper
# The port listening for client request
clientPort=2181 默认情况下,zookeeper服务器会监听 2181端口,更详细的信息可去zookeeper官网查阅。
2. 启动Kafka broker 运行kafka提供的启动kafka服务脚本即可:
[root@localhost kafka-0.8]# bin/kafka-server-start.sh config/server.properties
broker配置文件中的重要属性:
# broker的id. 每个broker的id必须是唯一的.
Broker.id=0
# 存放log的目录
log.dir=/tmp/kafka8-logs
# Zookeeper 连接串
zookeeper.connect=localhost:2181
3. 创建一个仅有一个Partition的topic [root@localhost kafka-0.8]# bin/kafka-create-topic.sh --zookeeper localhost:2181 --replica 1 --partition 1 --topic kafkatopic
4. 用Kafka提供的生产者客户端启动一个生产者进程来发送消息 [root@localhost kafka-0.8]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic kafkatopic
其中有两个参数需要注意:
- broker-list:定义了生产者要推送消息的broker地址,以<IP地址:端口>形式
- topic:生产者发送给哪个topic
然后你就可以输入一些消息了,如下图:

5. 启动一个Consumer实例来消费消息 [root@localhost kafka-0.8]# bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic kafkatopic --from-beginning
当你执行这个命令之后,你便可以看到控制台上打印出的生产者生产的消息:

和消费者相关的属性配置存放在Consumer.properties文件中,重要的属性有:
# consumer的group id (A string that uniquely identifies a set of consumers
# within the same consumer group)
groupid=test-consumer-group
# zookeeper 连接串
zookeeper.connect=localhost:2181
二、单节点运行多broker实例
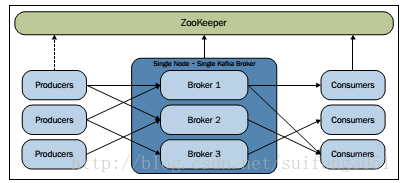
1.启动zookeeper 和上面的一样
2.启动Kafka的broker 要想在一台机器上启动多个broker实例,只需要准备多个server.properties文件即可,比如我们要在一台机器上启动两个broker:
首先我们要准备两个server.properties配置文件
- server-1
- brokerid=1
- port=9092
- log.dir=/temp/kafka8-logs/broker1
- server-2
- brokerid=2
- port=9093
- log.dir=/temp/kafka8-logs/broker2
然后我们再用这两个配置文件分别启动一个broker
[root@localhost kafka-0.8]# env JMX_PORT=9999 bin/kafka-server-start.sh config/server-1.properties
[root@localhost kafka-0.8]# env JMX_PORT=10000 bin/kafka-server-start.sh config/server-2.properties
可以看到我们启动是为每个broker都指定了不同的JMX Port,JMX Port主要用来利用jconsole等工具进行监控和排错
3.创建一个topic 现在我们要创建一个含有两个Partition分区和2个备份的broker:
[root@localhost kafka-0.8]# bin/kafka-create-topic.sh --zookeeper localhost:2181 --replica 2 --partition 2 --topic othertopic
4.启动Producer发送消息 如果我们要用一个Producer发送给多个broker,唯一需要改变的就是在broker-list属性中指定要连接的broker:
[root@localhost kafka-0.8]# bin/kafka-console-producer.sh --broker-list localhost:9092,localhost:9093 --topic othertopic
如果我们要让不同的Producer发送给不同的broker,我们也仅仅需要为每个Producer配置响应的broker-list属性即可。
5.启动一个消费者来消费消息 和之前的命令一样
[root@localhost kafka-0.8]# bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic othertopic --from-beginning
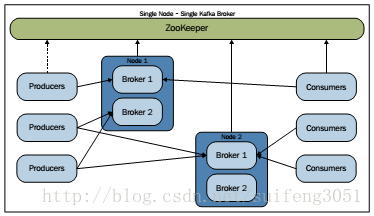
三、集群模式(多节点多实例) 介绍了上面两种配置方法,再理解集群配置就简单了,比如我们要配置如下图所示集群:
zookeeper配置文件(zookeeper.properties):不变
broker的配置配置文件(server.properties):按照单节点多实例配置方法在一个节点上启动两个实例,不同的地方是zookeeper的连接串需要把所有节点的zookeeper都连接起来
# Zookeeper 连接串
zookeeper.connect=node1:2181,node2:2181
转自:http://www.aboutyun.com/thread-11114-1-1.html
Kafka详解二:如何配置Kafka集群的更多相关文章
- HUE配置文件hue.ini 的hdfs_clusters模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的hive和beeswax模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的yarn_clusters模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的hbase模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的zookeeper模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的Spark模块详解(图文详解)(分HA集群和HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的impala模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的liboozie和oozie模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的sqoop模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
随机推荐
- Python2.6升级Python2.7
Python2.6升级2.7 由于Centos6系列自带的python版本为2.6.6,然而有很多应用需要依赖于python2.7来实现,所以有了这个升级的需求.升级原理很简单,无非就是下载.编译.安 ...
- iOS学习笔记(九)——xml数据解析
在iPhone开发中,XML的解析有很多选择,iOS SDK提供了NSXMLParser和libxml2两个类库,另外还有很多第三方类库可选,例如TBXML.TouchXML.KissXML.Tiny ...
- CodeIgniter框架——知识要点汇总
NO1.学习要点: 一.CodeIgniter 框架的简介 二.CodeIgniter 框架的安装 三.CodeIgniter 框架的目录结构分析 四.CodeIgniter 框架是如何工作的? 五. ...
- Python抓取网页并保存为PDF
https://blog.csdn.net/shenwanjiang111/article/details/67634794
- 合并子目录(hash)
题目2 : 合并子目录 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 小Hi的电脑的文件系统中一共有N个文件,例如: /hihocoder/offer22/soluti ...
- Chart控件文档
假设c1Chart1为Chart控件的一个实例. 一.基本框架图 二.主要外层属性(即this.c1Chart1的主要属性) 1.Header和Footer,上标题和下标题.位于this.c1Char ...
- 巨蟒django之CRM4 一些小功能
内容回顾: 修改的地方 (1) (2) (3) (4) (5) 整体回顾前几天内容: 现在可以登录的原因,session内部存储了信息 这个时候我们再访问刚才的地址,会发现,跳转到了登录页面login ...
- POJ 3259 Wormholes【bellman_ford判断负环——基础入门题】
链接: http://poj.org/problem?id=3259 http://acm.hust.edu.cn/vjudge/contest/view.action?cid=22010#probl ...
- ssm框架整合-过程总结(第三次周总结)
本周主要是完成前端界面和后端的整合. 犹豫前后端的工作完成程度不一致,只实现了部分整合. 登录界面. 可能自己最近没有把重心放在短学期的项目上,导致我们工作的总体进度都要比别慢. 虽然我们只是三个人的 ...
- Python操作Redis(一)
redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorted set ...