吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets,ensemble
from sklearn.model_selection import train_test_split def load_data_regression():
'''
加载用于回归问题的数据集
'''
#使用 scikit-learn 自带的一个糖尿病病人的数据集
diabetes = datasets.load_diabetes()
# 拆分成训练集和测试集,测试集大小为原始数据集大小的 1/4
return train_test_split(diabetes.data,diabetes.target,test_size=0.25,random_state=0) #集成学习梯度提升决策树GradientBoostingRegressor回归模型
def test_GradientBoostingRegressor(*data):
X_train,X_test,y_train,y_test=data
regr=ensemble.GradientBoostingRegressor()
regr.fit(X_train,y_train)
print("Training score:%f"%regr.score(X_train,y_train))
print("Testing score:%f"%regr.score(X_test,y_test)) # 获取分类数据
X_train,X_test,y_train,y_test=load_data_regression()
# 调用 test_GradientBoostingRegressor
test_GradientBoostingRegressor(X_train,X_test,y_train,y_test)

def test_GradientBoostingRegressor_num(*data):
'''
测试 GradientBoostingRegressor 的预测性能随 n_estimators 参数的影响
'''
X_train,X_test,y_train,y_test=data
nums=np.arange(1,200,step=2)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for num in nums:
regr=ensemble.GradientBoostingRegressor(n_estimators=num)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(nums,training_scores,label="Training Score")
ax.plot(nums,testing_scores,label="Testing Score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1.05)
plt.suptitle("GradientBoostingRegressor")
plt.show() # 调用 test_GradientBoostingRegressor_num
test_GradientBoostingRegressor_num(X_train,X_test,y_train,y_test)
def test_GradientBoostingRegressor_maxdepth(*data):
'''
测试 GradientBoostingRegressor 的预测性能随 max_depth 参数的影响
'''
X_train,X_test,y_train,y_test=data
maxdepths=np.arange(1,20)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for maxdepth in maxdepths:
regr=ensemble.GradientBoostingRegressor(max_depth=maxdepth,max_leaf_nodes=None)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(maxdepths,training_scores,label="Training Score")
ax.plot(maxdepths,testing_scores,label="Testing Score")
ax.set_xlabel("max_depth")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(-1,1.05)
plt.suptitle("GradientBoostingRegressor")
plt.show() # 调用 test_GradientBoostingRegressor_maxdepth
test_GradientBoostingRegressor_maxdepth(X_train,X_test,y_train,y_test)

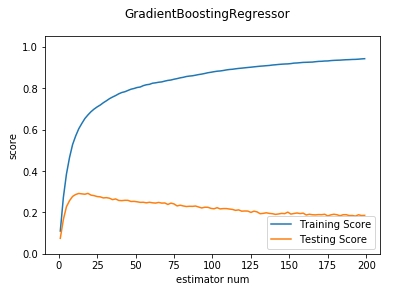
def test_GradientBoostingRegressor_learning(*data):
'''
测试 GradientBoostingRegressor 的预测性能随 learning_rate 参数的影响
'''
X_train,X_test,y_train,y_test=data
learnings=np.linspace(0.01,1.0)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for learning in learnings:
regr=ensemble.GradientBoostingRegressor(learning_rate=learning)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(learnings,training_scores,label="Training Score")
ax.plot(learnings,testing_scores,label="Testing Score")
ax.set_xlabel("learning_rate")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(-1,1.05)
plt.suptitle("GradientBoostingRegressor")
plt.show() # 调用 test_GradientBoostingRegressor_learning
test_GradientBoostingRegressor_learning(X_train,X_test,y_train,y_test)
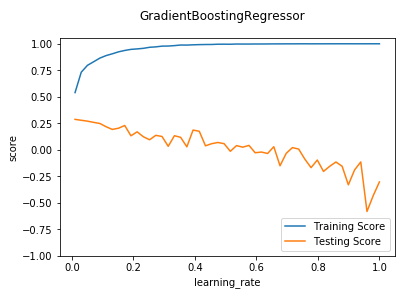
def test_GradientBoostingRegressor_subsample(*data):
'''
测试 GradientBoostingRegressor 的预测性能随 subsample 参数的影响
'''
X_train,X_test,y_train,y_test=data
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
subsamples=np.linspace(0.01,1.0,num=20)
testing_scores=[]
training_scores=[]
for subsample in subsamples:
regr=ensemble.GradientBoostingRegressor(subsample=subsample)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(subsamples,training_scores,label="Training Score")
ax.plot(subsamples,testing_scores,label="Training Score")
ax.set_xlabel("subsample")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(-1,1.05)
plt.suptitle("GradientBoostingRegressor")
plt.show() # 调用 test_GradientBoostingRegressor_subsample
test_GradientBoostingRegressor_subsample(X_train,X_test,y_train,y_test)
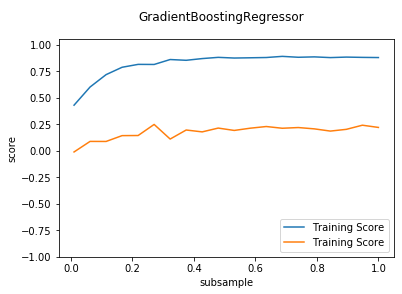
def test_GradientBoostingRegressor_loss(*data):
'''
测试 GradientBoostingRegressor 的预测性能随不同的损失函数和 alpha 参数的影响
'''
X_train,X_test,y_train,y_test=data
fig=plt.figure()
nums=np.arange(1,200,step=2)
########## 绘制 huber ######
ax=fig.add_subplot(2,1,1)
alphas=np.linspace(0.01,1.0,endpoint=False,num=5)
for alpha in alphas:
testing_scores=[]
training_scores=[]
for num in nums:
regr=ensemble.GradientBoostingRegressor(n_estimators=num,loss='huber',alpha=alpha)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(nums,training_scores,label="Training Score:alpha=%f"%alpha)
ax.plot(nums,testing_scores,label="Testing Score:alpha=%f"%alpha)
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right",framealpha=0.4)
ax.set_ylim(0,1.05)
ax.set_title("loss=%huber")
plt.suptitle("GradientBoostingRegressor")
#### 绘制 ls 和 lad
ax=fig.add_subplot(2,1,2)
for loss in ['ls','lad']:
testing_scores=[]
training_scores=[]
for num in nums:
regr=ensemble.GradientBoostingRegressor(n_estimators=num,loss=loss)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(nums,training_scores,label="Training Score:loss=%s"%loss)
ax.plot(nums,testing_scores,label="Testing Score:loss=%s"%loss)
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right",framealpha=0.4)
ax.set_ylim(0,1.05)
ax.set_title("loss=ls,lad")
plt.suptitle("GradientBoostingRegressor")
plt.show() # 调用 test_GradientBoostingRegressor_loss
test_GradientBoostingRegressor_loss(X_train,X_test,y_train,y_test)
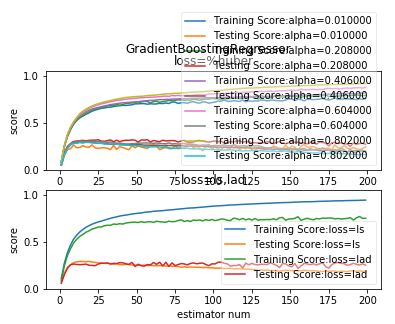
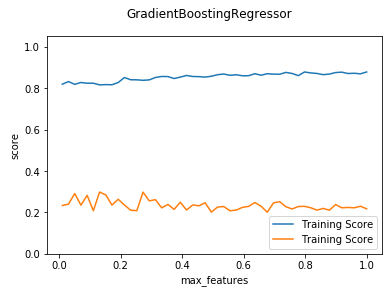
def test_GradientBoostingRegressor_max_features(*data):
'''
测试 GradientBoostingRegressor 的预测性能随 max_features 参数的影响
'''
X_train,X_test,y_train,y_test=data
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
max_features=np.linspace(0.01,1.0)
testing_scores=[]
training_scores=[]
for features in max_features:
regr=ensemble.GradientBoostingRegressor(max_features=features)
regr.fit(X_train,y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
ax.plot(max_features,training_scores,label="Training Score")
ax.plot(max_features,testing_scores,label="Training Score")
ax.set_xlabel("max_features")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1.05)
plt.suptitle("GradientBoostingRegressor")
plt.show() # 调用 test_GradientBoostingRegressor_max_features
test_GradientBoostingRegressor_max_features(X_train,X_test,y_train,y_test)
吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型的更多相关文章
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
- 吴裕雄 python 机器学习——人工神经网络感知机学习算法的应用
import numpy as np from matplotlib import pyplot as plt from sklearn import neighbors, datasets from ...
- 吴裕雄 python 机器学习——人工神经网络与原始感知机模型
import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D from ...
- 吴裕雄 python 机器学习——分类决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——回归决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
随机推荐
- npm命令笔记-----转自网络,仅供自己查看使用
npm是一个node包管理和分发工具,已经成为了非官方的发布node模块(包)的标准.有了npm,可以很快的找到特定服务要使用的包,进行下载.安装以及管理已经安装 的包. npm常用指令 1.npm ...
- 微信小程序自定义顶部导航
注释:自定义导航需要自备相应图片 一.设置自定义顶部导航 Navigation是小程序的顶部导航组件,当页面配置navigationStyle设置为custom的时候可以使用此组件替代原生导航栏. 1 ...
- 机器学习作业(三)多类别分类与神经网络——Python(numpy)实现
题目太长了!下载地址[传送门] 第1题 简述:识别图片上的数字. import numpy as np import scipy.io as scio import matplotlib.pyplot ...
- 一个vue的日历组件
说明: 1.基于element-ui开发的vue日历组件. 地址 更新: 1.增加value-format指定返回值的格式2.增加头部插槽自定义头部 <ele-calendar > < ...
- Vs2013以管理员身份运行
VS快捷方式目录下的devenv.exe 右键->兼容性疑难解答->疑难解答程序->勾选该程序需要附加权限即可,以后每次打开VS时都会以管理员身份运行了!
- LVS+Nginx(LVS + Keepalived + Nginx安装及配置)
(也可以每个nginx都挂在上所有的应用服务器) nginx大家都在用,估计也很熟悉了,在做负载均衡时很好用,安装简单.配置简单.相关材料也特别多. lvs是国内的章文嵩博士的大作,比nginx被广 ...
- VSCode配置Go插件和第三方拓展包
前言 VSCode现在已经发展的相当完善,很多语言都比较推荐使用其来编写,Go语言也一样,前提你电脑已经有了Go环境和最新版本的VSCode 插件安装 直接在拓展插件中搜索Go,就可以安装Go插件 安 ...
- Linux忘记 root密码的解决办法
很多朋友经常会忘记Linux系统的root密码,linux系统忘记root密码的情况该怎么办呢?重新安装系统吗?当然不用!进入单用户模式更改一下root密码即可. 步骤如下: 重启linux系统 重启 ...
- SpringBoot--SSM框架整合
方式一 1 建立一个Spring Starter 2.在available中找到要用的包,配置mybatis 3.建立file,application.yml 文件 spring: datasourc ...
- 显示目录文件命令 - ls
1) 命令名称:ls 2) 英文原意:list 3) 命令所在路径:/bin/ls 4) 执行权限:所有用户 5) 功能描述:显示目录文件 6) 语法: ls 选项[-ald][文件或目录] -a 显 ...