Python爬虫教程-28-Selenium 操纵 Chrome
我觉得本篇是很有意思的,闲着没事来看看!
Python爬虫教程-28-Selenium 操纵 Chrome
PhantomJS 幽灵浏览器,无界面浏览器,不渲染页面。Selenium + PhantomJS 在之前是很完美的搭配。后来在 2017 年 Google 宣布 Chrome 也宣布支持不渲染。所以 PhantomJS 使用的人就越来越少了,挺可惜,本篇介绍 Selenium + Chrome
安装Chrome浏览器和 Chromedriver
- 安装 Chrome 浏览器就不介绍了
- 安装 Chromedriver:
- 注意:Chromedriver 需要根据自己的 Chrome 版本下载:
- Chromedriver 所有版本下载地址:http://npm.taobao.org/mirrors/chromedriver/
- 兼容版本请参照:Chrome版本与chromedriver兼容版本对照表
- 下载解压即可,当然如果你解压到自己定义的目录,就需要配置一下环境,去环境变量,在 Path 加一条 Chromedriver 的安装目录
- 如果你嫌配置环境变量太麻烦,就直接把它放到一个已经配置好环境变量的目录,比如 C:\Program Files (x86)
安装 Chromedriver-binary 包
- 【PyCharm】>【file】>【settings】>【Project Interpreter】>【+】 >【BeautifulSoup4】>【install】
- 具体操作截图:
安装好就可以尽情使用了
Selenium 操作
- Selenium 操作主要分两大类:
- 得到 UI 元素
- find_element_by_id
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
- 基于 UI 元素操作的模拟
- 单击
- 右键
- 拖拽
- 输入
- 可以通过 ActionsChains类来做到
- 得到 UI 元素
案例 29chromedriver
- 案例 29chromedriver.py 代码文件:
https://xpwi.github.io/py/py爬虫/py29chromedriver.py
# Selenium + Chrome 案例1
from selenium import webdriver
# 路径是自己解压安装 Chromedriver 的路径
driver = webdriver.Chrome()
url = "http://www.baidu.com"
driver.get(url)
# 根据id查找,后面加.text 表示拿看到的文本数据
text = driver.find_element_by_id('wrapper').text
print(text)
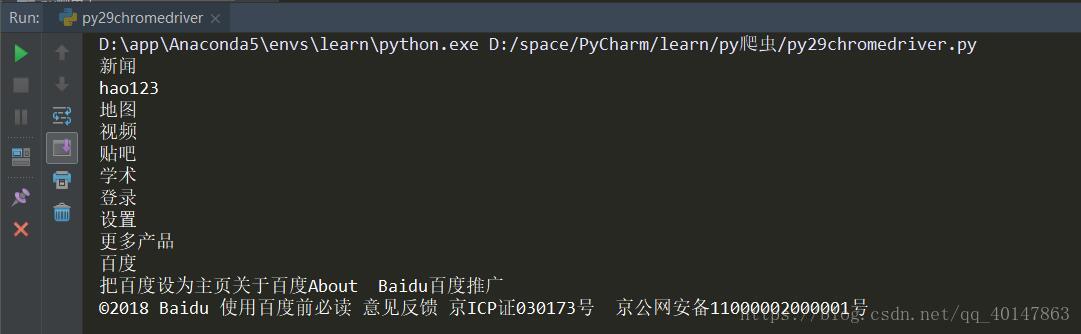
运行结果
1.控制台:打印出来了我们想要的能看到的文本
2.我们可以看到:执行程序自动打开了一个 Chrome 浏览器的窗口,并提示 Chrome 正受到自动检测软件的控制
此时,既然已经控制了浏览器,我们就可以进行更多操作了
重要案例 29chromedriver2.py
- 案例 29chromedriver2.py 代码文件:
https://xpwi.github.io/py/py爬虫/py29chromedriver2.py
# Selenium + Chrome 案例2
# 打开的浏览器可能会弹窗,点击【取消】或者【不管它】都行
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
# 默认不需要路径,如果没有环境变量就需要加上
driver = webdriver.Chrome()
url = "http://www.baidu.com"
driver.get(url)
# 根据id查找,后面加.text 表示拿看到的文本数据
text = driver.find_element_by_id('wrapper').text
print(driver.title)
# 对页面截屏,保存为 baidu.png
driver.save_screenshot('py29baidu.png')
# 控制 Chrome 在输入框输入大熊猫
driver.find_element_by_id('kw').send_keys(u"大熊猫")
# 单击搜索按钮,id = 'su'
driver.find_element_by_id('su').click()
# 缓冲5秒,让页面加载图片等
time.sleep(5)
# 截屏,保存
driver.save_screenshot("py29daxiongmao.png")
# 获取当前页面的 cookie 常用在需要登录的页面
print(driver.get_cookie('cookie'))
# 模拟 按下两个按键 Ctrl + a
driver.find_element_by_id('kw').send_keys(Keys.CONTROL, 'a')
# 模拟 按下两个按键 Ctrl + c
driver.find_element_by_id('kw').send_keys(Keys.CONTROL, 'c')
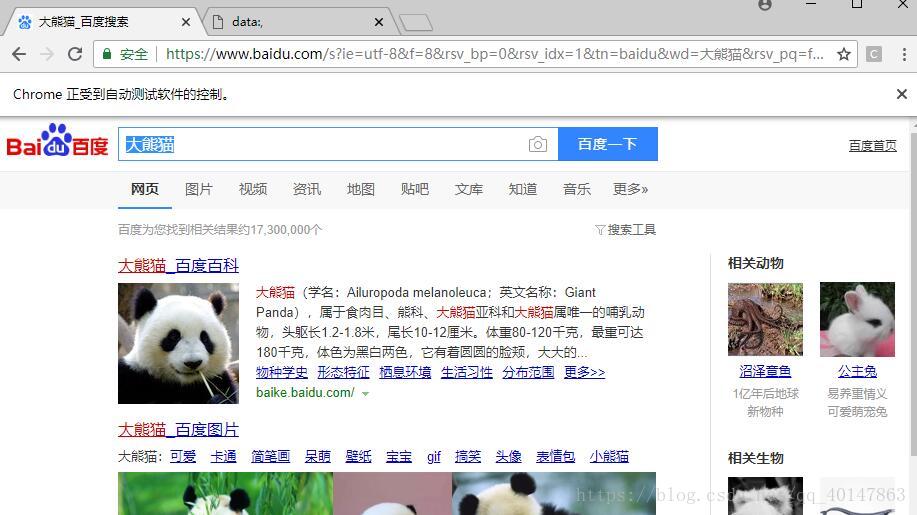
运行结果
运行代码,会自动打开浏览器,自动输入大熊猫,自动截屏并保存,然后选中输入框内容,然后拷贝
是不是很神奇,保存的截屏和代码同级目录
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-28-Selenium 操纵 Chrome的更多相关文章
- 【python爬虫】利用selenium和Chrome浏览器进行自动化网页搜索与浏览
功能简介:利用利用selenium和Chrome浏览器,让其自动打开百度页面,并设置为每页显示50条,接着在百度的搜索框中输入selenium,进行查询.然后再打开的页面中选中“Selenium - ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
- python爬虫动态html selenium.webdriver
python爬虫:利用selenium.webdriver获取渲染之后的页面代码! 1 首先要下载浏览器驱动: 常用的是chromedriver 和phantomjs chromedirver下载地址 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
- Python爬虫教程-26-Selenium + PhantomJS
Python爬虫教程-26-Selenium + PhantomJS 动态前端页面 : JavaScript: JavaScript一种直译式脚本语言,是一种动态类型.弱类型.基于原型的语言,内置支持 ...
- Python爬虫教程-21-xpath 简介
本篇简单介绍 xpath 在python爬虫方面的使用,想要具体学习 xpath 可以到 w3school 查看 xpath 文档 xpath文档:http://www.w3school.com.cn ...
- Python爬虫教程-16-破解js加密实例(有道在线翻译)
python爬虫教程-16-破解js加密实例(有道在线翻译) 在爬虫爬取网站的时候,经常遇到一些反爬虫技术,比如: 加cookie,身份验证UserAgent 图形验证,还有很难破解的滑动验证 js签 ...
随机推荐
- dubbo核心流程一览
整体设计 图中从下至上分为十层,各层均为单向依赖,右边的黑色箭头代表层之间的依赖关系,每一层都可以剥离上层被复用,其中,Service 和 Config 层为 API,其它各层均为 SPI. Serv ...
- Stack — 20181121
12. Min Stack public class MinStack { Stack<Integer> stack; Stack<Integer> minStack; pub ...
- PIE SDK影像坏线修复
1.算法功能简介 坏条带的由来:2003年5月31日,Landsat-7ETM+机载扫描行校正器(SLC) 故障,导致此后获取的影像出现了数据条带丢失,严重影响了Landsat ETM遥感影像的使用. ...
- Linux and Shell 实用命令
-name '*.jar' -printf '%p:' ### 查看CPU使用率 mpstat -P ALL
- javascript 正则表达式校验方式写法
if(/[0-9]/.test(value)){return true; } if(/[a-z]/.test(value)){return true; } if(/[A-Z]/.test(value) ...
- Oracle Schema
1.这是Schema的definition: A schema is a collection of database objects (used by a user.) Schema objects ...
- selenium+Python(处理html5的视频播放)
Webdriver支持在指定的浏览器测试HTML5,另外可以用JavaScript来测试这些功能,这样就可以在任何浏览器上测试HTML5 多数浏览器使用控件来播放视频,但是不同浏览器需要使用不同的插件 ...
- selenium中等待元素的加载
在实际使用中,有时会出现一个元素还没有加载出来,导致无法获取,此时需要selenium处理来等待一段时间,此时处理方法有以下几种: 1.最笨.最简单但是最不推荐的方式: Thread.sleep(ti ...
- Python对列表中字典元素排序
问题起源 json对象a,b a = '{"ROAD": [{"id": 123}, {"name": "no1"}]} ...
- Centos7 安装mysql教程
参考原文:http://www.centoscn.com/mysql/2016/0315/6844.html 环境 CentOS 7.1 (64-bit system) MySQL 5.6.24 Ce ...