初试spark java WordCount
初始环境:OS X 10.10.5
准备:boot2docker
进入boot2docker后安装 docker-spark 地址: https://github.com/sequenceiq/docker-spark 里面有很详细的介绍
我启动这个镜像的命令是
docker run -it -p 8088:8088 -p 8080:8080 -p 9000:9000 -p 50070:50070 -p 8042:8042 -p 7077:7077 -p 4040:4040 -h sandbox sequenceiq/spark bash
还没大整明白,端口映射比较多
然后进入到下面的目录里
cd /usr/local/spark/examples/src/main/java/org/apache/spark/examples/
可以看到经典的JavaWordCount.java 的代码
我们在idea中建立一个JAVA的maven工程,只有一个依赖如下
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
将上面的代码JavaWordCount代码复制出来
打包前有一个地方需要注意下,勾选红框
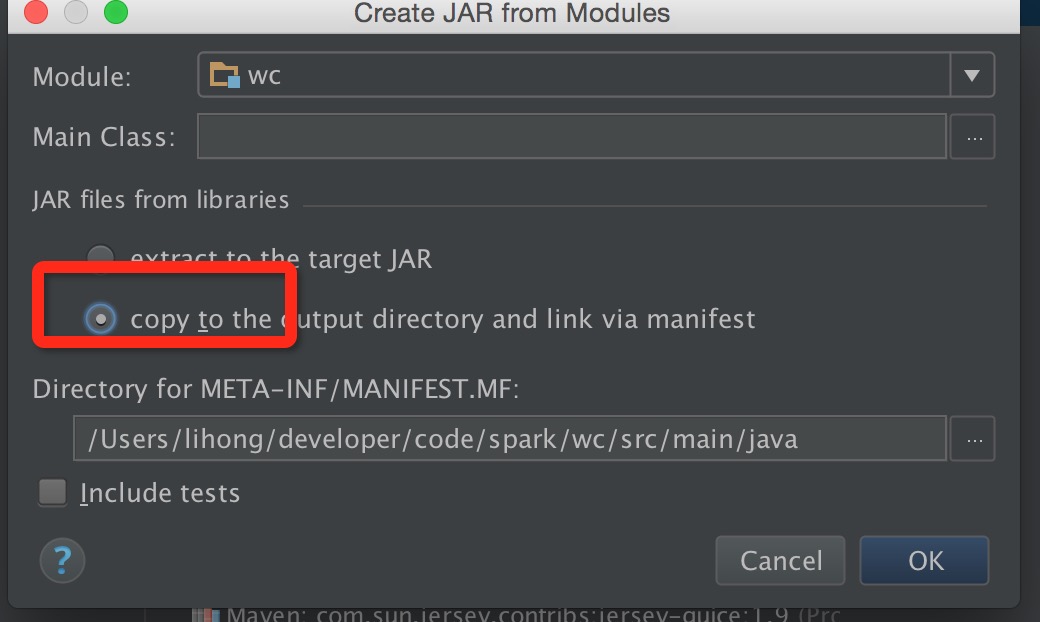
然后在out目录下把跟module同名的jar文件上传到docker-spark中
准备测试文件:
随便建一个文本文件
然后上传到hdfs中
先创建一个目录
hdfs dfs -mkdir testdata
然后上传测试文件
hdfs dfs -put .txt /user/root/testdata
我们使用单机Spark Standalone Mode的方式来运行
进入
/usr/local/spark-1.6.-bin-hadoop2./sbin
启动master
./start-master.sh
启动slave
./start-slave.sh sandbox:
准备就绪,进入到上传的jar文件目录下运行
spark-submit --master spark://sandbox:7077 --name WordCountByDH --class com.dh.WordCount --executor-memory 1G --total-executor-cores 2 wc.jar /user/root/testdata/1.txt
这样你就能看到运行的结果了

问题:再idea下运行是遇到下面这个问题,有几个内部类找不到了,还没解决:
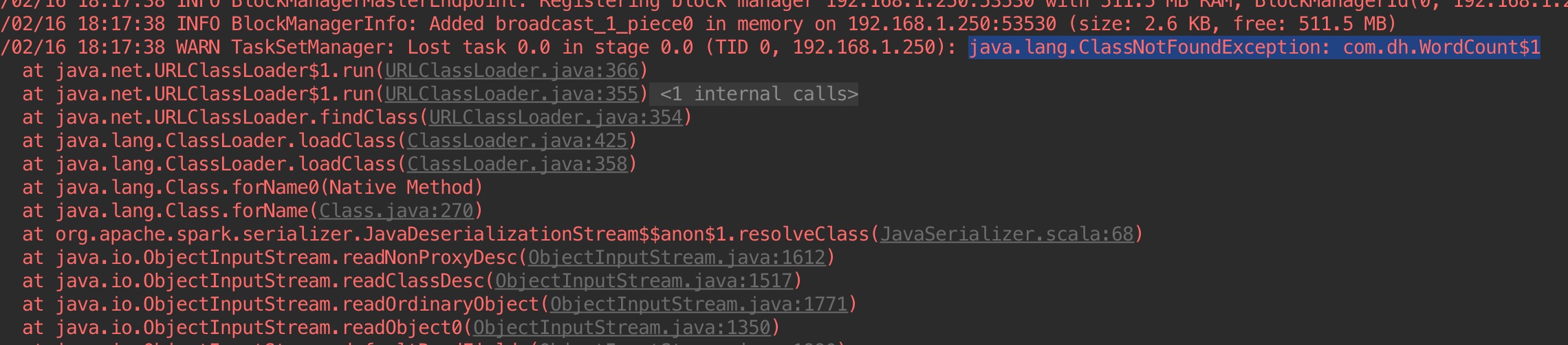
初试spark java WordCount的更多相关文章
- spark java wordCount实例
1. 算子 package com.test; import java.util.Arrays; import java.util.List; import org.apache.spark.Spar ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- [转] 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? [sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需 ...
- 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需要 ...
- 1.spark的wordcount解析
一.Eclipse(scala IDE)开发local和cluster (一). 配置开发环境 要在本地安装好java和scala. 由于spark1.6需要scala 2.10.X版本的.推荐 2 ...
- windows下 eclipse搭建spark java编译环境
环境: win10 jdk1.8 之前有在虚拟机或者集群上安装spark安装包的,解压到你想要放spark的本地目录下,比如我的目录就是D:\Hadoop\spark-1.6.0-bin-hadoop ...
- Spark Java API 计算 Levenshtein 距离
Spark Java API 计算 Levenshtein 距离 在上一篇文章中,完成了Spark开发环境的搭建,最终的目标是对用户昵称信息做聚类分析,找出违规的昵称.聚类分析需要一个距离,用来衡量两 ...
- Spark Java API 之 CountVectorizer
Spark Java API 之 CountVectorizer 由于在Spark中文本处理与分析的一些机器学习算法的输入并不是文本数据,而是数值型向量.因此,需要进行转换.而将文本数据转换成数值型的 ...
- spark JAVA 开发环境搭建及远程调试
spark JAVA 开发环境搭建及远程调试 以后要在项目中使用Spark 用户昵称文本做一下聚类分析,找出一些违规的昵称信息.以前折腾过Hadoop,于是看了下Spark官网的文档以及 github ...
随机推荐
- BZOJ1123 BLO
割点的好题. 联通图,难度降低.首先对于一个点,如果他不是割点,那它的贡献是2*(n-1),就是任何一个其他节点都少了正反两个数对,这个看样例可以看出来. 如果它是一个割点,去掉他以后会出现若干个联通 ...
- 解决Vue在IE中报错出现不支持=>等ES6语法和“Promise”未定义等问题
在做VUE项目中大家可能会发现除了IE内核浏览器之外项目都能正常显示,但是到IE就萎了,这主要是IE不支持ES6的原因. 要解决这个我们要先引入browser.js,这样你可以使用ES2015(jav ...
- ELK- elasticsearch 讲解,安装,插件head,bigdesk ,kopf,cerebro(kopf升级版)安装
ElasticSearch:简称es ,分布式全文搜索引擎,使用java语言开发,面向文档型数据库,一条数据就是一个文档,数据用json序列化后存储. 默认端口:9200 借助redis来理解 red ...
- layui表格遇到的小操作
表头文字显示不全 done:function(res){ tdTitle() }, /*表头文字显示不全*/ function tdTitle(){ $('th').each(function(ind ...
- Cortex-M3 异常返回值EXC_RETURN
[EXC_RETURN] 在进入异常服务程序后,硬件自动更新LR的值为特殊的EXC_RETURN.当程序从异常服务程序返回,把这个EXC_RETURN值送往PC时,就会启动处理器的异常中断返回序列.因 ...
- 自定义有焦点的TextView实现广告信息左右一直滚动的跑马灯效果
import android.content.Context; import android.text.TextUtils; import android.util.AttributeSet; imp ...
- [zookeeper]ZooInspector的使用
一.背景 Zookeeper作为常用的集群协调者组件被广泛应用,尤其是在大数据生态圈中: Zookeeper集群存储各个节点信息,包括:Hadoop.Hbase.Storm.Kafka等等: ...
- Ironic 的 Rescue 救援模式实现流程
目录 文章目录 目录 救援模式 实现 UML 图 救援模式 以往只有虚拟机支持救援模式,裸机是不支持的.直到 Queen 版本 Ironic 实现了这个功能.救援模式下,用户可以完成修复.Troubl ...
- 阶段3 3.SpringMVC·_06.异常处理及拦截器_4 SpringMVC拦截器之介绍和搭建环境
拦截器可以有多个 搭建环境 不用改,直接finish 复制原来项目的 依赖的包也复制过来 web.xml配置前端控制器 springmvc的配置文件 先创建对应的文件夹 分别创建java和resour ...
- 配置文件中间件:config-lite
config-lite 是一个轻量的读取配置文件的模块. config-lite 会根据环境变量(NODE_ENV)的不同从当前执行进程目录下的 config 目录加载不同的配置文件. 如果不设置 N ...